
JRubyConf запланирован на
21-23 мая в Миннеаполисе
Недавно в новостях появился JRuby: всего пару недель назад был выпущен JRuby 1.6.7 , скоро выйдет JRubyConf , и за последние несколько месяцев было много шума о предстоящем выпуске JRuby 1.7 и о том, как Я воспользуюсь новой поддержкой Java 7 для «InvokeDynamic». После всего этого я был рад возможности побеседовать с Чарльзом Натттером , одним из разработчиков в основной команде JRuby.
Если у вас есть несколько минут, читайте дальше, чтобы непосредственно услышать от Чарльза его собственные слова о том, что нового в JRuby, почему традиционный Rubyist захочет использовать JRuby, как приложения Ruby могут использовать библиотеки Java из репозитория Maven, и — мой любимый тема — JRuby внутренности. Для меня это было все увлекательно! Собеседование с Чарльзом было прекрасной возможностью узнать больше о JRuby.
RubyConf Индия, JRubyConf и JRuby 1.6.7

Чарльз Наттер
Вопрос: Я слышал, что на следующей неделе вы выступите с основным докладом на RubyConf India … поздравляю!

Да, основной слот был своего рода сюрпризом! Я просто хотел выйти и поговорить и потусоваться, но это должно быть весело.
Q: А если говорить о конференциях, разве JRubyConf не запланирован на май ?
Да! Я приглашаю всех прийти на JRubyConf в Миннеаполисе, родном городе Тома Энебо , Ника Сигера и меня, с 21 по 23 мая. Это по разумной цене, в дешевом районе, и мы хотели бы, чтобы как можно больше людей приехали. Мы поговорим о вещах как на JRuby, так и на других языках. Это должно быть просто отличное событие!
Q: И я слышал, что вы, ребята, только что выпустили JRuby 1.6.7 . Что нового в этом выпуске?
Мы выпустили основной / минорный релиз в 1.6.6, который, как мы надеялись, станет последним релизом 1.6. У нас было много исправлений: множество улучшений, исправлены некоторые ошибки производительности и улучшено поведение Ruby 1.9. Поскольку у 1.6.6 был длинный цикл, и никто не пробовал что-то делать до тех пор, пока вы его не выпустите, сразу после того, как мы выпустили его, мы получили множество сообщений об ошибках, особенно проблемы с кодированием 1.9, которые мы не исправили. Итак, пару недель спустя мы решили, что выпустим еще один релиз. Мы исправили еще 40 проблем, большинство из которых были связаны с Ruby 1.9, и это то, что есть в 1.6.7. Это быстрый выпуск, чтобы исправить кучу проблем, обнаруженных в 1.6.6.
Зачем использовать JRuby?
Q: На случай, если некоторые из наших читателей не очень знакомы с JRuby, где хорошее место, чтобы начать изучать JRuby?

Ну, есть книга « Использование JRuby: привнесение Ruby в Java от прагматичных программистов» — это отличная книга, которая, похоже, помогает многим людям.
Q: Можете ли вы объяснить, почему традиционный Rubyist захочет использовать JRuby?
Есть несколько вещей, на которые мы обычно указываем: одна из самых важных заключается в том, что мы постоянно работаем над улучшением производительности. В небольших приложениях или ресурсоемких задачах JRuby обычно является самым быстрым Ruby на данный момент. Это не означает, что для всех приложений мы самые быстрые, в частности, есть некоторые сложные приложения на Rails, у нас возникают проблемы с запуском так быстро, как хотелось бы. Но производительность большая, и мы продолжаем работать над этим все время. Плюс мы используем работу, которую ребята из JVM делают с производительностью все время.
Следующее, что может случиться, если сборка мусора или управление памятью является узким местом для приложения, основанного на MRI, это, вероятно, не решит проблему на JRuby. У JVM есть отличные сборщики мусора, и мы, в основном, просто добавляем их.
Последняя область — это стабильность и кроссплатформенность JVM: множество отличных библиотек, работающих на каждой платформе, и вы получаете все это бесплатно, в значительной степени. Вам не нужно делать много работы по переносу JRuby с платформы на платформу. Если у вас есть код, который работает на одной платформе, он тоже будет работать где-то еще.
В: С Heroku очень легко с помощью нескольких команд запустить новое приложение в Интернете. Есть ли такой же простой вариант для JRuby?
На самом деле это одна из областей, на которой мы проводим много времени. Мы хотим, чтобы повседневный опыт JRuby напоминал обычный Ruby. Для этого есть облачный вариант, который хорошо протестирован и используется людьми из Engine Yard , например. Способ развертывания приложения с помощью MRI или JRuby в Engine Yard в основном идентичен. Возможно развертывание в Heroku, используя стек кедра и другие вещи. И я думаю, что есть пакет сборки, который делает его немного проще. И если вы выполняете собственное развертывание вручную, есть ряд серверов командной строки, которые имитируют Unicorn или Passenger или любой из них. Нашим предпочтительным вариантом является Тринидад, который оборачивает Tomcat и дает вам параметр командной строки. Мы многое сделали для того, чтобы заставить его чувствовать себя почти так же, как при развертывании или запуске обычного Ruby.
Это непрерывный процесс, но мы хотим, чтобы Rubyists могли работать как Rubyists, когда они используют JRuby.
В: Каковы очевидные различия между JVM и стандартным MRI Ruby?
С JRuby вы запускаете реальные параллельные потоки … у вас есть преимущество: возможность работать одновременно и использовать несколько ядер. Но есть некоторые вещи, которые мы не гарантируем потокобезопасности, просто потому, что они будут слишком накладными: вещи, такие как параллельные мутации строк, массивов, хэши и тому подобное.
Одним из недостатков JRuby, который мы всегда пытаемся улучшить, является время запуска. Для JRuby это определенно хуже, но как только у вас все получится, производительность будет лучше, иногда намного лучше, чем стандартная реализация Ruby. Это своего рода компромисс там.
Q: Значит, время запуска ежедневных разработок является болезненным?
На повседневное время разработки влияет то, что нужно начинать. TDD, типичный способ работы Rubyists, все еще может быть немного болезненным с JRuby. Это определенно улучшается с течением времени, но все же немного мешает. Время запуска JVM само по себе неплохое, но в значительной степени весь код JRuby все еще должен быть скомпилирован JVM во время выполнения в какой-то момент. Таким образом, в течение первой или двух секунд, в течение которых выполняется приложение, ничто не компилируется в собственный код. Даже Java-части JRuby. Так что нам нужно немного больше времени, чтобы разогреться и набрать полную скорость.
Другая половина этого заключается в том, что многие библиотеки и инструменты Ruby были построены на том факте, что MRI запускается быстро. Например, «bundle exec» — это два запуска любой используемой вами реализации Ruby. Если вы запускаете «rake test» в Rails, я считаю, что он запускает 4 или 5 отдельных процессов.
В: Имеет ли смысл заниматься разработкой с помощью МРТ и перейти на JRuby?
Если используемые вами библиотеки совместимы, то на самом деле это не плохой путь. Например, квадратные люди для своей повседневной разработки, как правило, используют MRI, а затем тестирование и развертывание происходит на JRuby.
Q: Многие Rubyists ненавидят Java по той или иной причине … если вы ненавидите Java, вы также будете ненавидеть JRuby?
Время запуска, вероятно, единственное, что было бы видно большинству из них. Другие аспекты Java, которые люди ненавидят, такие как пути к классам, серверы приложений и многословность самого языка Java — большинство из этого вы никогда не увидите, если используете JRuby. Мы довольно хорошо спрятали все эти вещи.
JRuby и Maven: использование библиотек Java в приложении Ruby
В: Я смотрел видео с RubyConf прошлой осенью и видел, как вы говорили об использовании Maven в качестве менеджера пакетов для Ruby. Можете ли вы рассказать нам больше об этом?
Любой, кто имеет дело с миром Java, знает, что он вращается вокруг репозиториев Maven и Maven — в какой-то момент все относится к Maven. Maven действительно хорошо справляется, нравится ли вам процесс сборки и его жесткость, — это предоставляет глобальный репозиторий всех библиотек Java со всеми их зависимостями и всей доступной информацией. То, что мы хотим сделать, это сделать весь этот репозиторий библиотек Java доступным, как если бы они были просто обычными гемами.

search.maven.org позволяет выполнять поиск в центральном репозитории Apache Maven, пока
mvnrepository.com позволяет искать в различных общедоступных репозиториях Maven
Q: Так это что-то вроде Java-версии RubyGems.org ? Это то, как я должен думать об этом?
Да, по большому счету. Он намного больше, он объединяет множество серверов, и библиотек гораздо больше, чем в RubyGems, но это, по сути, то, что он делает для мира Java. Поскольку мы хотим упростить разработчикам Ruby использование библиотек Java и не думать о таких вещах, как Maven, мы постепенно со временем добавили некоторые вещи, такие как исправления, в нашу копию RubyGems, которая позволяет устанавливать любую библиотеку Maven, как если бы она была просто драгоценный камень.
Q: То есть я могу просто запустить «gem install XYZ» и установить библиотеку из Maven?
Да точно. Вы просто указываете, какой идентификатор для этой библиотеки, и он извлекает ее из серверов Maven.
Q: И это будет работать с любой библиотекой Java?
О, да — один из примеров, которые я использую, — это установка Gem Clojure , языка для JVM. Вы опускаете библиотеку, запускаете IRB и можете фактически вызвать Clojure или любую другую установленную таким образом библиотеку Java.
JRuby Internals
Вопрос: Я всегда знал, что Java-код JRuby был скомпилирован в байт-код, но до недавнего времени я никогда не знал, что целевой скрипт Ruby также был скомпилирован в байт-код. Можете ли вы описать, как это работает?
Для стандартных фрагментов, таких как базовые классы String и Array, по большей части то, что написано на C в обычном Ruby, написано на Java для JRuby. Это основы. Кроме того, у нас есть интерпретатор, похожий на Ruby 1.8, который по сути просто прогуливается по дереву, абстрактному синтаксическому дереву (AST), которое было проанализировано из кода.
У нас есть парсер, который в основном является портом парсера Ruby, использующий аналогичный генератор парсера. Руби использует тот, который называется Бизон ; мы используем тот, который называется Jay, который по сути та же самая грамматика, тот же синтаксис, и наш парсер выглядит почти так же, как Ruby.
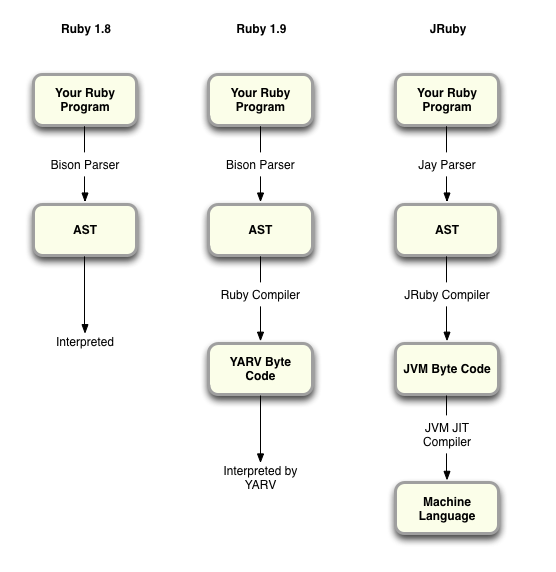
Чем отличаются Ruby 1.8, Ruby 1.9 и JRuby при разборе и выполнении вашего кода
Мы интерпретируем это какое-то время, просто ходя по нему и делая то, что говорит AST. Если фрагмент кода запускается много раз, то мы делаем еще один проход и компилируем его в байтовый код JVM. Я думаю, что порог составляет около 50 вызовов, и мы превратим его в байт-код JVM. Оттуда это до JVM. У JVM есть собственный цикл интерпретации на некоторое время, а затем компиляции в нативный код. Но в основном мы стараемся передать код JVM как можно быстрее, чтобы в какой-то момент все скомпилировалось до нативного.
Q: Я много слышал о «InvokeDynamic» в последнее время, и о том, как он ускорит JRuby, но я не уверен, что это такое. Можете ли вы объяснить, что на самом деле делает InvokeDynamic?
Основы вызова метода Ruby: если вы вызываете метод «foo», вам нужно найти фрагмент кода, который идет вместе с методом «foo» для некоторого целевого объекта, а затем вызвать его. В идеале, вы не хотите делать такой поиск каждый раз, когда вызываете foo, так как может потребоваться обход иерархии классов, между вызовом и целевым классом могут быть некоторые сложные модули и другие вещи. Итак, вы хотите как-то это кешировать. Типичный способ, которым Ruby 1.9, JRuby и некоторые другие реализации делают это, заключается в том, что называется встроенным кэшем. В каждой точке кода, где вы делаете вызов, у нас есть небольшой кеш, который сохраняет последний увиденный метод. Если вы продолжаете вызывать один и тот же метод в этот момент, снова и снова, он не будет продолжать выполнять поиск. Вот как работает JRuby на Java 6.
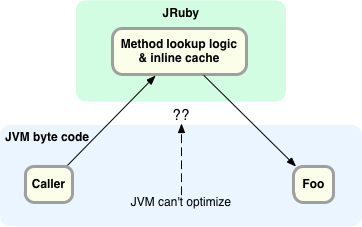
В JRuby 1.6 JVM не может оптимизировать код поиска сложных методов в JRuby
На Java 7 мы действительно можем сказать JVM: «Вот как вы смотрите на этот метод. Иди и найди его и свяжи с конкретным звонком. Мы сделаем логику поиска метода. И вот как мы хотим, чтобы вы назвали это. Вот как мы хотим, чтобы вы организовали параметры, вот любая логика, которая должна присутствовать до и после, вот как вы знаете, является ли этот метод правильным для последующего вызова, вот как вы защищаетесь от того, что это другой тип, другой класс, который находится в этот момент. Поскольку мы можем сообщить JVM всю эту информацию, ее гораздо проще оптимизировать. На самом деле он может видеть весь путь от вызова «foo» до целевого метода и понимает всю логику между ними. Это было то, чего мы просто не могли сделать в предыдущих версиях JVM.
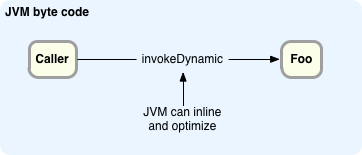
В JRuby 1.7 JVM может встроить и оптимизировать динамический вызов
Сама JVM довольно динамична, потому что почти все является объектом, и все они являются виртуальными вызовами. Он должен делать много динамического языка внутри, даже если он статически типизирован на уровне языка Java. Когда дело доходит до фазы связывания в Java 6 JVM, на самом деле есть четыре или пять способов, которыми он знает, как это сделать. Это либо статический вызов, либо виртуальный вызов, либо интерфейсный вызов и т. Д., И он уже жестко запрограммирован в оптимизаторе, чтобы знать, как это сделать как можно быстрее. InvokeDynamic дает нам новый способ связать вызов с целевым методом в терминах, которые он может понимать и оптимизировать, как и все остальные протоколы вызовов.
JRuby 1.7, которая сейчас является главной веткой, — это то место, где выполняется вся работа InvokeDynamic. Вы можете поиграть с ним прямо сейчас — производительность уже выглядит великолепно, хотя у нас еще много работы.
Что дальше?
Q: Я где-то читал, что выходит новый компилятор JRuby, называемый «IR Compiler» — это правильно?
Это верно! В попытке улучшить байт-код JVM, я думаю, это самый простой способ сказать это, мы работаем над новым собственным компилятором, который работает полностью выше уровня JVM, с нашим собственным набором инструкций. Это набор команд, которым мы можем управлять, мы можем оптимизировать его по-своему, и мы начинаем делать простую вставку на этом уровне набора команд, прежде чем мы передадим его в JVM. Мы пытаемся настроить среду исполнения и набор инструкций, которые лучше соответствуют принципам работы Ruby, а затем перейти к получению лучшего интерпретатора и компилятора.
Q: Так что будет дополнительный шаг в этом процессе; Вам нужно сначала скомпилировать этот новый набор команд, а затем перевести его обратно в байт-код Java?
Да, точно. Это подошло бы там, где у нас сейчас ходит AST, переводчик AST. Вместо того, чтобы идти прямо в интерпретатор AST, мы могли бы передать код нашему IR-компилятору и оптимизатору, а затем позволить этому некоторое время интерпретировать. И оттуда мы превратили бы IR в байт-код JVM, и в идеале байт-код, который из него получился, был бы как бы «предварительно оптимизирован» и не имел ничего общего.
Q: Какое будущее у JRuby? Что дальше?
Ну, мы продолжаем работать над улучшением производительности JRuby. За последние пару месяцев мы проделали большую работу, чтобы действительно дополнить возможности Ruby 1.9. Мы снова начнем обращать внимание на производительность: IR-компилятор, работа invokeDynamic, все эти вещи должны начать приносить серьезные дивиденды как часть JRuby 1.7 и выше.
Благодарность!
Q: Вау — увлекательно! Спасибо, что объяснили мне все это!
Большое спасибо — приятно пообщаться с вами …