SOA, или Сервис-ориентированная архитектура, часто используется как термин, предназначенный только для предприятий, который используется компаниями, не меньшими, чем Amazon. Не бойтесь, SOA также может использоваться маленькими парнями! Давайте сломать форму.
Целью любой реализации SOA является сегментирование частей приложения по логическим и бизнес-функциям. Он может разбить монолитные приложения на множество небольших потребляемых услуг. Маленькие парни могут использовать SOA, но, как правило, это не то, что вы хотите применять, пока не почувствуете боли роста. Нет точного ответа на вопрос, когда следует использовать SOA, но неэффективность базы данных, проблемы масштабируемости команды, проблемы развертывания и неуправляемая сложность — все это ключевые показатели. Небольшие группы могут захотеть использовать SOA в надежде на более простое обслуживание, более быстрые итерации, более надежные тесты и масштабируемость.
В этой статье я хочу познакомить вас с архитектурой большинства монолитных приложений Rails, сравнить ее с сервис-ориентированной архитектурой, а затем внедрить базовый сервис с Sinatra , Redis и RSpec . Чтобы продемонстрировать SOA, выделим (вымышленное) музыкальное приложение, которое объединяет людей со всего мира с похожими музыкальными интересами.
Типичное приложение Rails
Типичные приложения Rails сильно зависят от одной базы данных. Обычно мы встраиваем все наши первичные данные в базу данных и строим стек MVC сверху. Эти приложения имеют следующую архитектуру:
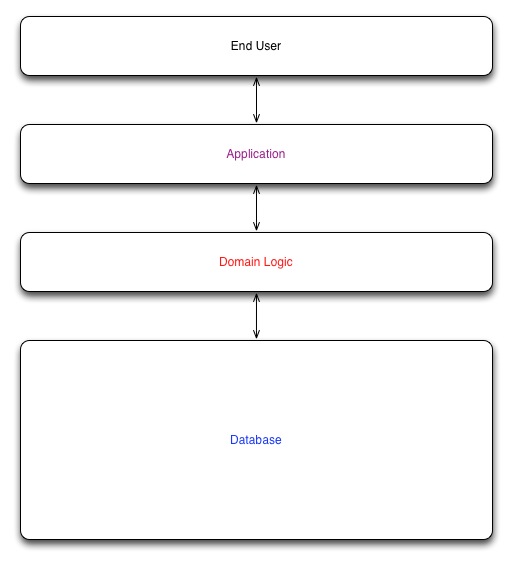
Приложение Rails Monolith
Эта структура прекрасно работает по мере появления приложений, но имеет ряд долгосрочных проблем:
- Неэффективность базы данных. К сожалению, базы данных, которые мы полюбили, не масштабируются. Миллионы строк в таблице могут создать огромную нагрузку на базу данных, особенно если эти данные объединяются, обрабатываются и запутываются. Поэтому мы либо оптимизируем наши запросы, либо используем новую технологию для кэширования вычисленных значений или предоставляем новый интерфейс для данных (например, MapReduce). Мы исправляем проблему.
- Масштабируемость команды. Работа над одной моделью часто ломает другие модели. Слишком много команд работают над одной и той же кодовой базой и имеют побочные эффекты. Там нет разделения проблем среди приложения; это все один репо.
- Развертывание. Вы вносите изменения во все приложение при внесении небольших изменений, что может потребовать простоев.
- Сложность. Поскольку данные так тесно связаны, каждый новый разработчик в команде должен изучить всю систему. Найти разработчиков становится все труднее, а систему гораздо сложнее понять.
SOA-подход
Сервис-ориентированная архитектура пытается облегчить проблемы с монолитными приложениями Rails. Было бы неразумно прыгать в SOA при создании новых приложений, поскольку природа архитектуры часто может добавить нежелательную сложность. Обычно это поздний игрок в игре, и он становится полезным, когда приложение Rails становится слишком большим. Цель состоит в том, чтобы взять большое приложение и оживить его, разбив его логические компоненты на отдельные сервисы. На каждую службу можно положиться атомарно, чтобы выполнить набор задач для ее соответствующего домена. По сравнению с монолитной архитектурой Rails, вот как может выглядеть SOA-приложение:
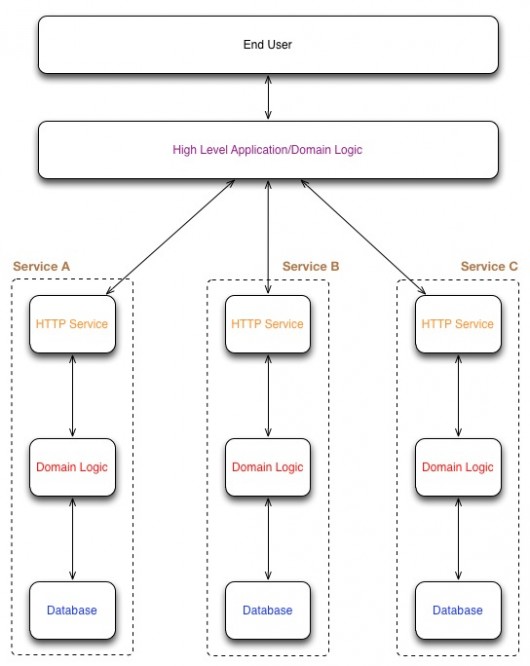
Приложение SOA
У каждого сервиса есть своя собственная база данных, своя логика домена и собственный HTTP-интерфейс. На приведенной выше диаграмме показаны три разных сервиса. Эти сервисы затем объединяются в высокоуровневое приложение, которое обслуживает конечного пользователя. Часть доменной логики все еще живет в высокоуровневом приложении, но большая ее часть была абстрагирована в сервисы. Основная задача приложения высокого уровня — объединить данные из сервисов в нечто, что может быть предоставлено пользователю.
Реконструкция приложения в сервисы может обеспечить несколько улучшений:
- Базы данных меньше. Каждый сервис может выбрать, какое хранилище данных соответствует его потребностям. Как правило, служебные данные являются подмножеством исходных данных и хранятся в реляционной базе данных. Однако, если служба будет испытывать большие чтения и записи, возможно, хранилище в памяти, такое как Redis, обеспечит более быстрые результаты. Независимо от хранилища данных, сложность данных уменьшается.
- Команды теперь могут работать самостоятельно. Каждый сервис становится собственным развертываемым приложением. Это означает, что каждой команде может быть назначен отдельный сервис, и они могут поддерживать свою кодовую базу без нарушения работы смежных команд.
- Каждая кодовая база может быть развернута в одиночестве. Пока интерфейс HTTP остается постоянным, службы могут быть развернуты быстро и быстро, не затрагивая остальную часть приложения.
- Сложность была сломана. Каждый сервис — это четко определенный, простой способ доступа к данным и логике в определенном домене. Новые разработчики могут работать с одним сервисом без необходимости понимать другие. Они также могут познакомиться с кодовой базой намного быстрее.
Определение услуг
Давайте посмотрим, как приложение социальной музыки можно разбить на сервисы. Цель приложения — дать пользователям возможность найти людей по всему миру со схожими музыкальными интересами. Это социальное приложение извлекает исполнителей из Last.fm , позволяет пользователям выражать интерес к исполнителям и предоставляет список пользователей, которым нравится одна и та же музыка.
Первый вопрос, который приходит на ум: «Как я делю свое приложение на сервисы?» Конечно, это зависит от рассматриваемого приложения, но есть несколько ключевых рекомендаций, которым нужно следовать, и несколько вариантов под рукой.
Сначала рассмотрим построение сервисов вокруг логической функциональности. Основные функциональные возможности музыкального приложения уже были разбиты: извлекать данные с Last.fm (Служба исполнителей), отслеживать интерес пользователей к исполнителям (Служба интересов) и управлять пользователями (Служба пользователей).
Далее рассмотрим, где меняется приложение. Как правило, вы хотите, чтобы ваши службы оставались стабильными с течением времени, поэтому лучше сохранять часто меняющиеся функциональные возможности в приложении высокого уровня , отделившись от самих служб.
Рассмотрим тип данных и частоту операций чтения / записи. Отдельные услуги могут быть оптимизированы для одного или другого, или обоих. Регистрация интереса к исполнителю — это функция с высокой степенью записи, а объединение похожих пользователей — функция с высокой степенью чтения, обе из которых будут существовать в службе интересов.
Посмотрите, как часто данные объединяются. Если данные объединяются часто, возможно, эти данные должны находиться в одной и той же службе и обрабатываться в базе данных. Если данные объединяются редко, они могут быть распределены по нескольким службам и объединены с Ruby в приложении высокого уровня .
Для этого примера мы определим три сервиса, один из которых мы реализуем: сервис Artist, сервис User и сервис Interest. Мы пропустим сервисы User и Artist и сразу перейдем к реализации сервиса Interest. Вот как работает каждый сервис:
- Сервис Artist в основном состоит из фонового работника, который запрашивает данные на Last.fm. Сервис Artist хранит имена художников и их жанры в реляционной базе данных.
- Сервис пользователя использует реляционную базу данных и типичную модель пользователя. Сервис обеспечивает CRUD и аутентификацию для пользователей.
- Служба интересов предоставляет интерфейс для регистрации интереса конкретного пользователя к исполнителю. Данный пользователь также предоставляет набор пользователей с похожим интересом. Чтобы обеспечить этот набор, мы сохраним соединение между Artist и User в наборе Redis . Redis SET дают нам высокую способность чтения / записи и возможность находить пересечения между музыкальными интересами многих пользователей.
Протестируйте сервис по интересам
Сначала написание тестов помогает определить, как ваш HTTP-сервис будет выглядеть для внешнего мира. Это также самый важный компонент для тестирования в любой реализации SOA. Не заглушайте и не фальсифицируйте запрос в сервис, проверьте реальную вещь. На данный момент мы предполагаем, что сервисы User и Artist были реализованы. Напишем несколько тестов для сервиса Interest с использованием RSpec.
спецификации / interest_spec.rb
| require ‘services/user’ | |
| require ‘services/artist’ | |
| describe ‘POST /interests’ do | |
| # Use User and Artist Ruby wrappers to call services | |
| let(:user) { Services::User.create(:name => ) } | |
| let(:artist) { Services::Artist.create(:name => ‘Cool Band’, :genres => [‘Jazz’, ‘R&B’]) } | |
| it ‘registers a users interest in an artist’ do | |
| # Initiate POST request | |
| post ‘/interests’, { | |
| :user_id => user.id, | |
| :artist_id => artist.id | |
| }.to_json | |
| last_response.should be_ok | |
| end | |
| end |
 by
by Для краткости предполагается, что классы Services :: User и Services :: Artist являются простыми оболочками HTTP для служб User и Artist. Они вызывают аналогичные POST-запросы к своим соответствующим конечным точкам HTTP, чтобы создать настройку, необходимую для тестирования службы интересов.
Этот тест отправляет POST-запрос службе интереса, чтобы зарегистрировать интерес пользователя к конкретному исполнителю. Он создает строку JSON для отправки в качестве тела POST. Наконец, мы проверяем, чтобы ответ был в порядке.
Как и любой другой HTTP-сервис, он должен быть включен в собственную библиотеку Ruby. Я не буду рассказывать о создании библиотеки-оболочки, но она должна быть реализована аналогично тестовому примеру выше. REST Client , HTTParty , Faraday , ActiveResource и многие другие HTTP-библиотеки могут быть использованы для создания оболочки Ruby.
Реализация услуг
Синатра является идеальным кандидатом на услуги. Он обеспечивает чистый DSL и легко обслуживается при условии, что обслуживание остается простым. Давайте посмотрим, как мы реализуем проверенный ранее метод сервиса Interest.
service.rb
| post ‘/interests’ do | |
| # Connect to Redis | |
| uri = URI.parse(ENV[«REDIS_URL»] || ‘redis://localhost:6379’) | |
| REDIS = Redis.new(:host => uri.host, :port => uri.port, :password => uri.password) | |
| # Parse the JSON body | |
| join = JSON.parse(request.body.read) | |
| # Register the user’s interest in an artist | |
| REDIS.sadd(«artists:#{join[‘artist_id’]}«, join[‘user_id’]) | |
| REDIS.sadd(«users:#{join[‘user_id’]}«, join[‘artist_id’]) | |
| status 201 | |
| end |
Чтобы реализовать эту конечную точку, мы сначала инициализируем Redis (вероятно, абстрагированный от этого блока), анализируем тело JSON, чтобы у нас был доступ к идентификаторам пользователя и исполнителя, а затем регистрируем интерес пользователя в Redis. Ключом к нашему набору Redis является комбинация пространства имен «artist:» и идентификатора исполнителя. Точно так же мы отслеживаем всех исполнителей, в которых заинтересован конкретный пользователь. После того, как несколько пользователей проявят интерес к исполнителям, наборы Redis будут выглядеть следующим образом:
| REDIS.smembers(‘artists:1’) #=> [«1″,»2″,»3»] where 1, 2 and 3 are user IDs | |
| REDIS.smembers(‘users:1’) #=> [«1″,»2″,»3»] where 1, 2 and 3 are artist IDs |
Я не буду создавать конечную точку службы для извлечения пользователей со схожими интересами, но она будет использовать пересечения Redis для определения этой взаимосвязи:
| artist_keys = REDIS.smembers(‘users:1’) | |
| artist_keys.map!{ |artist_id| «artists:#{artist_id}« } #=> [«artists:1», «artists:2», «artists:3»] | |
| REDIS.sinter(*artist_keys) #=> [«2″,»3»] where 2 and 3 are user IDs |
Чтобы найти похожих пользователей, мы сначала находим всех художников, которых интересует данный пользователь, а затем сопоставляем их с ключами Redis. Затем мы находим пересечение между ключами Redis (используя оператор splat ), которое предоставляет нам идентификаторы пользователей массива, которые интересуются теми же художниками.
Завершение
Сервис-ориентированная архитектура может кардинально изменить способ управления и разработки приложения. Это может обеспечить хорошее разделение, основанное на деловых и инженерных потребностях. Однако не без недостатков. Миграция на SOA может добавить общую сложность при упрощении отдельных компонентов. Его обширное разделение может затруднить объединение данных, заставить обычно произвольные решения усложняться и потенциально становиться громоздкими. Дядя Боб Мартин недавно написал статью в этом духе: сервис-ориентированная агония .
Преимущества, безусловно, могут перевесить затраты во многих ситуациях. Прежде чем приступить к переводу вашего приложения на сервис-ориентированную архитектуру, продолжайте исследовать лучшие практики по разделению сервисов.
Мы только поцарапали сервис SOA. Коммуникация сервисов, аутентификация, лучшие практики тестирования и кэширование — все это хорошие последующие концепции. Этой статьи должно быть достаточно, чтобы даже Маленькие парни перешли к поддерживаемым, масштабируемым решениям.
Удачной архитектуры!
SOA изображение через Shutterstock