
Добро пожаловать в новую статью из серии SitePoint « Рубин по медицине », где я показываю, как язык программирования Ruby может применяться к задачам, связанным с медицинской областью.
Эта серия статей может принести пользу начинающим, средним и продвинутым программистам на Ruby, а также исследователям и практикам в области здравоохранения и медицины, которые с нетерпением ждут изучения языка программирования Ruby, и применять его в своей области.
В этой статье я собираюсь показать вам, как мы можем использовать Ruby для проверки частоты появления слов в каком-либо файле. Подсчет частоты встречаемости слов может оказаться полезным в больших текстовых файлах, таких как файл OMIM ^ ® ^ — онлайн-наследование Менделяна в Man ^ ® ^ , с которым мы работали в предыдущей статье. , Причина, по которой подсчет частоты слов может быть полезен, состоит в том, что просмотр списка слов и их частоты даст нам больше понимания того, о чем документ. Он также может определять любые ошибки и орфографические ошибки, особенно когда у нас есть словарь для сравнения. Например, если слово из словаря не указано в выходных данных, вы можете просто сделать вывод, что с этим словом произошло неправильное написание, или вместо самих слов были использованы сокращения.
В этой статье мы будем работать с файлом OMIM® — онлайн-наследование Менделя в Man®. Давайте начнем.
Получить файл OMIM®
Я говорил о том, как получить файл OMIM® в моей последней статье: Ruby on Medicine: подсчет реальных слов с помощью Ruby , но я повторю это здесь, на тот случай, если вы не хотите переходить от одной статьи к другой.
OMIM ^ ® ^ можно получить, выполнив следующие действия:
Перейдите по этому анонимному ftp-адресу: ftp://ftp.ncbi.nih.gov . У вас должно появиться диалоговое окно, которое выглядит примерно так:
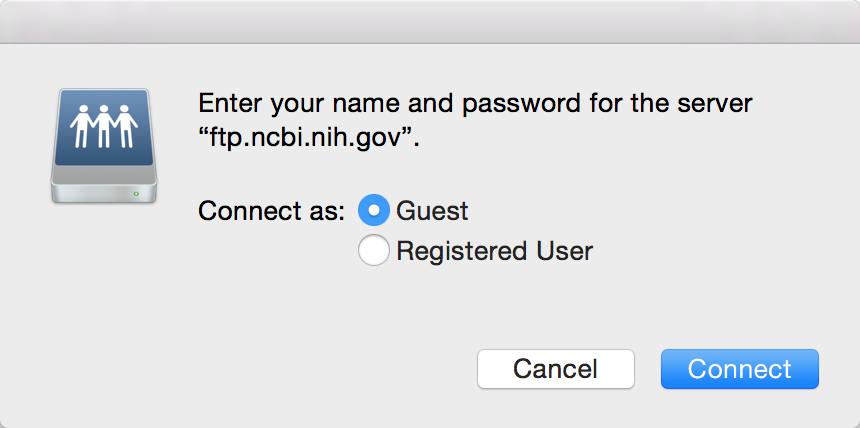
Выберите « Гость» рядом с « Подключить как:» , а затем нажмите кнопку « Подключиться» , и в этом случае вы увидите следующий каталог:
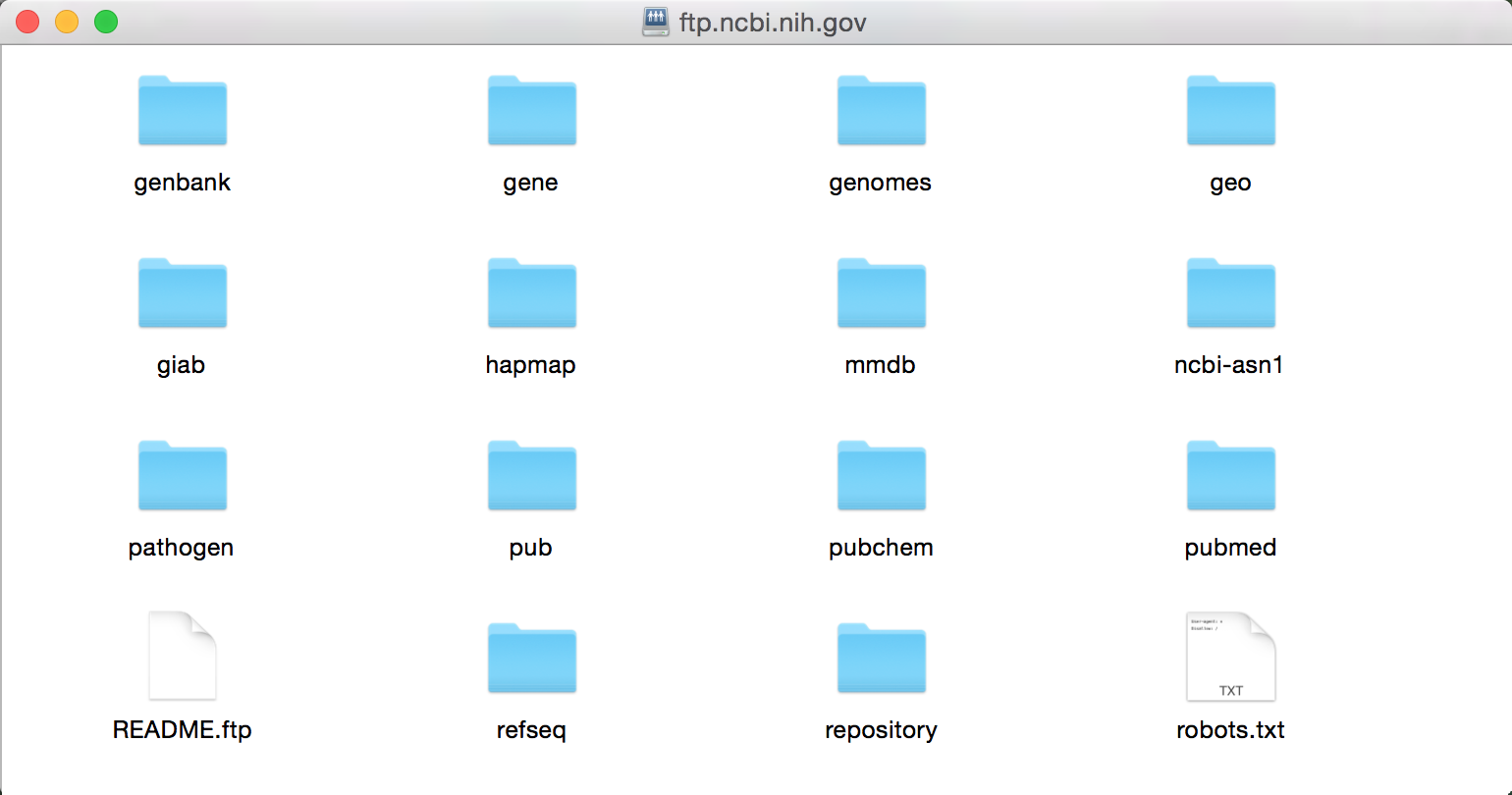
Нам нужен текстовый файл omim.txt.Z (66,3 МБ), который можно найти в каталоге / repository / OMIM / ARCHIVE .
Распакуйте файл, и в этом случае вы получите omim.txt (151,2 МБ).
Хэш
Поскольку мы будем проверять слова в файле и подсчитывать частоту появления каждого слова, хеши будут очень полезны.
Но что такое хэши Ruby ?
Когда я начал этот раздел, я упомянул, что мы будем проверять слова в файле и частоту появления каждого слова. Хэши представляют собой набор пар ключ-значение . В нашем случае это будет выглядеть следующим образом:
"word" => frequency Где word — это какое-то слово в файле, а frequency — это число, представляющее количество вхождений слова в этот файл.
Таким образом, хеш выглядит в значительной степени как массив, но вместо индекса с целочисленными значениями индексы являются ключами , которые могут быть любого типа.
Создание хэша в Ruby очень просто и может быть сделано следующим образом, который создаст пустой хеш:
Hash.new
Если вы хотите создать хеш со значением по умолчанию , вы можете сделать следующее:
Hash.new(0)
Приведенный выше хэш имеет значение по умолчанию 0 . Это означает, что, если вы попытались получить доступ к ключу, которого нет в хэше, созданном со значением по умолчанию, будет возвращено значение по умолчанию. Чтобы уточнить, что я имею в виду здесь, посмотрите на пример ниже, где два puts в следующем скрипте вернут 0 :
frequency = Hash.new(0) puts "#{frequency[0]}" puts "#{frequency[653]}"
Для получения дополнительной информации о хэше Ruby, вы можете прочитать эту статью и документы .
Подсчет количества вхождений
В этом разделе мы будем создавать программу Ruby, которая будет проверять частоту появления каждого слова в файле и сохранять результаты в выходном файле.
Первое, что мы хотим сделать, это создать новый хеш и присвоить ему значение по умолчанию 0 :
частота = Hash.new (0)
Мы хотим сохранить результаты в файле, поэтому скрипт Ruby write результаты в выходной файл. Мы можем использовать File.open () с режимом w (запись):
output_file = File.open('wordfrequency.txt', 'w')
Фронтендом операции является чтение в файле OMIM®, в нашем случае это omim.txt . Оператор для этой операции будет выглядеть следующим образом:
input_file = File.open('omim.txt', 'r')
Когда мы просматриваем файл на наличие слов, нам нужна функция Ruby — scan (pattern) . В документации Ruby упоминается следующее об этой функции:
scan выполняет итерацию по * str *, сопоставляя шаблон (который может быть регулярным выражением или строкой). Для каждого совпадения генерируется результат, который либо добавляется в массив результатов, либо передается в блок. Если шаблон не содержит групп, каждый отдельный результат состоит из соответствующей строки, $ &. Если шаблон содержит группы, каждый отдельный результат сам является массивом, содержащим одну запись на группу.
Когда мы говорим о сопоставлении с образцом, в этом случае сопоставление слов в файле, регулярные выражения (регулярное выражение) пригодятся. Я говорил о регулярном выражении в другой статье: Рубин на медицине: охота за последовательностью генов .
Основное регулярное выражение, которое нам нужно в этом уроке, это \b , то есть граница слова . Как вы уже догадались по его названию, это помогает нам подобрать слова.
Посмотрите следующие примеры, чтобы увидеть, как работает граница слова:
\bhat\b
Это регулярное выражение соответствует hat в red hat .
Если мы берем только одну границу следующим образом:
\bhat
Это будет соответствовать слову с hat в начале, например, в hatrat .
И, если мы хотим сопоставить hat в конце, например rathat , мы можем сделать это с помощью этого регулярного выражения:
hat\b
Вот скрипт, который будет возвращать частоту появления каждого слова в файле вместе:
frequency = Hash.new(0) input_file = File.open('omim.txt', 'r') output_file = File.open('wordfrequency.txt', 'w') input_file.read.downcase.scan(/\b[az]{3,16}\b/) {|word| frequency[word] = frequency[word] + 1} frequency.keys.sort.each{|key| output_file.print key,' => ',frequency[key], "\n"} exit
Прежде чем я покажу вам вывод, я просто хочу быстро уточнить некоторые моменты в приведенном выше сценарии.
Функция downcase возвращает все заглавные буквы, замененные их строчными аналогами. Мы используем его здесь, чтобы совпадения слов происходили независимо от их регистра.
Регулярное выражение /\b[az]{3,16}\b/ в основном говорит нам возвращать все слова, длина которых (количество символов) составляет от 3 до 16. Например, мы можем пропустить эти слова без особого интерес, как будто, или, на . Слова длиной более 16 могут быть последовательностью генов, которую мы не будем рассматривать словом.
Наконец, sort сортирует ключи ( то есть слова), перечисленные в выходном файле, по алфавиту.
Выход
Список слов и их частота встречаемости в файле OMIM®, используя вышеприведенный скрипт Ruby, сгенерирует этот выходной файл: wordfrequency.txt (2.37 МБ)
В списке вы можете заметить некоторые слова с очень небольшой частотой. Что будет указывать в большом текстовом файле, таком как OMIM ^ ® ^? Это слова без смысла? Слова с ошибками? Как вы думаете?
Последние две статьи этой серии посвящены тому, как использовать регулярные выражения для подсчета определенных слов и всех слов соответственно. Я надеюсь, что эти два примера предоставят вам инструменты для применения этой техники в вашем домене.