
Вы когда-нибудь замечали, что в Ruby отсутствует поддержка связанных списков? Большинство учебников по информатике заполнены алгоритмами, примерами и упражнениями, основанными на связанных списках: вставка или удаление элементов, сортировка списков, обращение списков и т. Д. Как ни странно, в Ruby нет объекта связанного списка.
Недавно, после изучения Haskell и Lisp в течение нескольких месяцев, я вернулся в Ruby и попытался использовать некоторые идеи функционального программирования, о которых я узнал. Но как мне создать список в Ruby? Как добавить или удалить элемент из списка в Ruby? Ruby содержит быстрые внутренние C-реализации классов Array и Hash, и в стандартной библиотеке вы можете найти код Ruby, реализующий классы Set, Matrix и Vector среди многих других. Но нет связанных списков — почему?
Ответ прост: в Matz включены функции, которые вы обычно связываете со связанными списками в классе Ruby Array. Например, вы можете использовать Array # push и Array # unshift, чтобы добавить элемент в массив, или Array # pop и Array # shift, чтобы удалить элемент из массива.
Сегодня я расскажу о нескольких распространенных операциях, для которых вы обычно используете связанный список, а затем рассмотрим, как их реализовать с использованием массива. Мы также получим некоторое представление о том, как работает объект массива Ruby.
Использование массива в качестве связанного списка
Когда я думаю о связанных списках, я имею в виду язык программирования Lisp, сокращенно «Обработчик списков». В своей классической статье « Рекурсивные функции символических выражений и их вычисление на машине», часть I , изобретатель Lisp Джон Маккарти определил «ячейку cons» »В качестве основного строительного блока связанных списков и соответствующей функции« (cons…) »Lisp для создания этих cons-ячеек.
Например, чтобы создать список (2, 3) в Лиспе, вы должны вызвать:
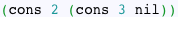
Внутренне Lisp создаст связанный список, который выглядит следующим образом:
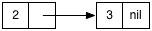
В Ruby, поскольку у нас нет объекта List, мы можем достичь того же, используя массив и метод Array # unshift, например:

Внутренне, Ruby создаст массив следующим образом:

Внешне кажется, что метод unshift в классе Array эквивалентен функции cons в Lisp. Оба они добавляют новый элемент в начало или в начало списка.
Добавление новых элементов в список — смещение элементов массива
Однако массивы и списки — это очень разные вещи. Массивы предназначены для произвольного доступа к данным в большом наборе, в то время как связанные списки вместо этого работают хорошо, вставляя, удаляя или переупорядочивая элементы.
Давайте представим, что я хочу добавить третье значение в свой список — в Лиспе я просто снова вызываю «cons»:

Внутренне Lisp просто создает новую «ячейку cons» и устанавливает указатель так, чтобы он указывал на исходный список:

В Ruby я бы просто снова назвал unshift :

Но помните, в массиве нет указателей, и вместо этого Ruby необходимо сместить все существующие элементы на одну позицию — отсюда и название метода unshift :

Это означает, что использование unshift означает, что вы платите штраф за производительность каждый раз, когда добавляете новый элемент в начало списка. Как вы можете догадаться, добавление элементов в конец списка обходится дешевле, поскольку сдвиг не требуется — лучший способ создать список в Ruby — использовать вместо него метод push или << :

Добавление новых элементов в середину списка работает в основном так же, как добавление нового элемента в начало списка. Если вы вызываете метод Array # insert , Ruby сначала должен переместить оставшиеся элементы вправо, чтобы освободить место для нового значения.
Добавление дополнительных элементов в список — изменение размера массива
Теперь предположим, что я добавляю четвертый элемент. В Лиспе я мог бы продолжать просто вызывать функцию «cons», добавляя все больше и больше элементов точно таким же образом. В Ruby, однако, обратите внимание, что мой массив заполнен, и нет места для четвертого элемента:

Оказывается, я не хотел показывать три блока в моей воображаемой диаграмме массива, чтобы сделать диаграмму проще. Внутренне, Ruby отслеживает два отдельных значения в каждом массиве: «размер» и «емкость:»
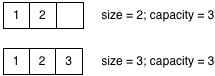
Размер указывает на фактический размер массива. Как я неоднократно вызывал unshift в моем примере выше, размер массива увеличился с 1 до 2 до 3.
Когда Ruby создает массив внутри, он выделяет дополнительную память, так как вы, скорее всего, скоро добавите больше элементов в массив. Каждый раз, когда вы создаете новый объект массива, Ruby изначально устанавливает емкость в 3; это означает, что он может сохранить три значения в массиве без необходимости запрашивать больше места. Однако после добавления четвертого элемента Ruby должен остановиться и получить новую память из системы сбора мусора, прежде чем сохранять четвертое значение. Это может вызвать операцию GC, если нет доступной памяти.

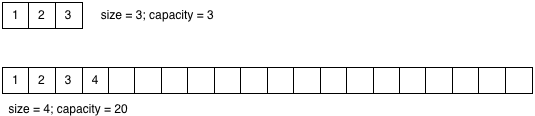
Когда вы добавляете все больше и больше элементов, Ruby многократно увеличивает размер емкости массива в кусках всякий раз, когда вы пересекаете определенные размеры массива: 3, 20, 37, 56, 85 элементов и т. Д. Точные пороговые значения определяются функцией C ary_double_capa внутри из массива. Более или менее емкость массива увеличивается на 50% каждый раз, хотя первое увеличение, с 3 до 20, является особым случаем. Вы платите дополнительный штраф за производительность каждый раз, когда это происходит.
Всякий раз, когда вы удаляете элемент из массива, например, с помощью shift или pop , Ruby может также уменьшить емкость массива вместе с размером. Это означает, что он может остановиться и освободить неиспользуемую память из массива обратно в систему GC, что приведет к дополнительной задержке.
Связанный список как функциональная структура данных
До сих пор мы видели, что массивы Ruby могут функционировать как связанные списки. Ruby предоставляет методы push , unshift и insert для добавления нового элемента в список, а также методы pop или shift для удаления элемента из списка. Мало того, что с массивом вы также получаете прямой, произвольный доступ ко всем элементам массива, чего не может предложить чистая структура связанного списка.
Единственным недостатком использования массива в качестве связанного списка, по-видимому, является производительность: если бы у вас было много тысяч элементов, Ruby теоретически замедлял бы многократное изменение размера массива для размещения всех элементов по мере их добавления.
Кроме того, если вам нужно добавить или удалить элементы в начале списка или где-то посередине, то Ruby также замедлит смещение оставшихся элементов вправо или влево. Но помните, поскольку Ruby реализован внутри C, он может использовать очень эффективные функции C для перемещения элементов. Memmove и подобные функции низкого уровня C часто реализуются непосредственно аппаратным обеспечением микропроцессора и работают очень и очень быстро.
Однако есть еще одна важная особенность связанных списков, которая не сразу бросается в глаза: они прекрасно работают как функциональные структуры данных. Что это значит? В функциональном языке программирования, таком как Lisp, вы определяете свою программу как серию «чистых функций»; это фрагменты кода, которые всегда возвращают один и тот же вывод при одинаковом вводе.
Функциональные языки программирования также препятствуют использованию «изменяемых значений» — переменных или объектов, которые могут меняться от одного значения к другому на месте. Основное преимущество использования чистых функций и неизменяемых значений состоит в том, чтобы позволить вашему программному обеспечению работать более надежно и надежно, поскольку ваш код не будет иметь побочных эффектов. Функциональные языки также хорошо работают в многопоточных средах, поскольку нет необходимости синхронизировать или блокировать код, который изменяет данные — вы просто не изменяете данные вообще.
Структуры данных, которые используют исключительно неизменяемые значения, известны как «функциональные структуры данных». Помимо больших преимуществ надежности и устранения необходимости синхронизировать доступ к различным потокам, функциональные структуры данных также позволяют легко обмениваться данными. Поскольку вы никогда не изменяете данные на месте, многие различные функциональные структуры данных могут легко использовать одну и ту же копию данных для внутреннего использования.
Связанный список является отличным примером этого: разные списки могут совместно использовать одни и те же «против» ячейки или значения данных внутри. Например, предположим, что в Лиспе я создаю один список:

А затем создайте второй список, добавив еще один элемент в первый список:

Теперь у меня есть два связанных списка, которые имеют одинаковые cons-ячейки для 2 и 3. Пока вы на самом деле никогда не меняете один из элементов на месте, для всех элементов связанных списков нет никаких проблем, которыми можно делиться!
Функциональные структуры данных позволяют вам — или, по крайней мере, разработчикам языка — применять оптимизации для совместного использования и сохранения памяти.
Скопируйте при оптимизации записи в Ruby Arrays
На первый взгляд кажется, что использование массивов в качестве списков в Ruby делает невозможной оптимизацию пространства. Во-первых, массив в Ruby не является функциональной структурой данных — вы, конечно, можете изменить любое значение в массиве, когда захотите. Но давайте на минутку предположим, что массивы Ruby были неизменяемыми или что в Ruby был объект «ImmutableArray». Как два отдельных массива могут совместно использовать одни и те же данные? Например, предположим, что я создал массив из шести элементов:
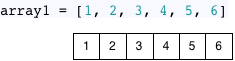
… и второй массив как подмножество:

Чтобы использовать оптимизацию пространства, подобную Lisp и другим функциональным языкам, мы должны представить, что Ruby может совместно использовать одну и ту же копию общих элементов в обоих массивах:

На самом деле, оказывается, что Ruby делает именно это! Используя ряд приемов, известных как «копирование при записи», Ruby делит значения между различными массивами! Ruby делает это, поддерживая единственную копию большего массива со всеми значениями данных и создавая второй массив, используя простой указатель или ссылку на середину большего массива, как показано выше.
Это называется оптимизацией «копирование при записи», поскольку Ruby должен прервать совместное использование и скопировать элементы данных при изменении или записи в одно из значений в общем массиве.
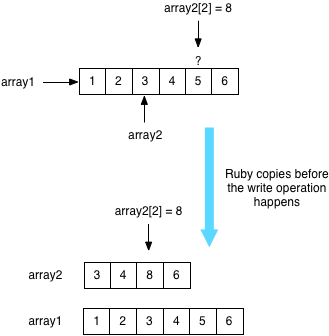
С практической точки зрения вам не нужно беспокоиться об этом: Ruby автоматически обработает все для вас, сэкономит вам память, когда сможет, и заплатит цену за копирование данных, когда это необходимо.
Однако, один простой случай, связанный со связанными списками, который выигрывает от оптимизации копирования при записи, — это многократное использование shift для итерации по списку:

Как я объяснил выше, теоретически Ruby необходимо сдвигать или копировать все существующие элементы влево всякий раз, когда вы удаляете элемент из заголовка списка. Для небольшого массива, подобного этому, это не имеет значения. Но если массив содержит 1000 элементов, возможно, это может быть медленной операцией.
Но из-за копирования в Ruby при оптимизации записи внутри объекта Array, Ruby достаточно умен, чтобы сохранить исходный массив и просто перемещать указатель или ссылку во время вызова shift :
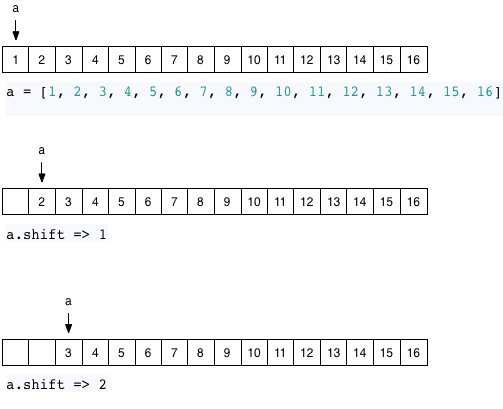
Почему я потрудился нарисовать массив из 16 элементов на этих диаграммах? Оказывается, когда вы вызываете shift, Ruby не использует эту оптимизацию, пока не будет хотя бы 16 элементов. Если вы сдвинете значение массива с 15 или менее элементами, то Ruby просто переместит все элементы влево, так как memmove очень быстр с небольшим массивом.
Реализация вашего собственного связанного списка
Чтобы подвести итоги сегодня, давайте посмотрим, как вы на самом деле реализуете связанный список в Ruby. Как мы уже видели, массивы могут довольно хорошо служить списками. Однако иногда вам может понадобиться многократно вставлять, удалять и переупорядочивать элементы в большом списке. Чтобы избежать снижения производительности, связанного с изменением размера и смещения массива, вам может пригодиться реальный связанный список.
Один простой способ создать связанный список — использовать объект Struct для представления cons-ячейки, например:

Смотрите эту интересную статью 2012 года для более подробной информации об этом подходе. Автор также показывает некоторые тесты, сравнивающие массивы и списки.
Другой подход заключается в создании отдельных объектов Entry и List, как описано в Eno Compton, в его превосходной статье: « Обращение связанного списка в Ruby» . Вот код:

Наконец, если вам интересно узнать больше о функциональных структурах данных и опробовать их в Ruby, посмотрите библиотеку Симона Харриса Hamster с неизменяемыми структурами данных, реализованную в Ruby . Саймон также написал эту прекрасную статью в 2010 году о том, как функциональное программирование заставило его переосмыслить то, как он пишет ОО-классы: функциональное программирование на объектно-ориентированных языках .