
Большинство людей очень смущаются, когда пытаются освоить нокогири, не осваивая вначале некоторые основы. Для этого есть причина. Попытка выучить Нокогири без изучения того, что заставляет его работать, — это все равно что попытаться выучить особенности Слова, не зная, как печатать. К концу этой статьи вам будет удобно взять веб-сайт и извлечь из него любую часть данных.
Nokogiri — один из самых популярных драгоценных камней Ruby, который на момент публикации был загружен более 37 миллионов раз. Для сравнения, в настоящий момент Rails имеет 47 миллионов загрузок . Первой моей мыслью, увидев это, было: «Ого, если этот драгоценный камень настолько популярен, для него должны быть довольно подробные учебные пособия, верно?» Если вы введете «учебник по рельсам» в Google, вы получите более 280 000 результатов. Поиск по «учебнику по nokogiri» дает вам… менее 3000 результатов (с другой стороны, после выхода этой статьи это число должно увеличиться!).
Нокогири — это парсер … Что?
Что еще хуже, большинство уроков скорее сбивают с толку, чем разъясняют. Например, при описании Nokogiri большинство статей описывает его как «парсер». У большинства людей нет четкого определения, что такое парсер. Чтобы ответить на этот вопрос, взгляните на этот ответ StackOverflow, где он описывается как «что-то, что превращает некоторые данные (обычно строки) в данные другого типа (обычно структуры данных)». Теперь все становится понятнее.
Почему так много людей используют нокогири?
Наиболее распространенное использование такого синтаксического анализатора, как Nokogiri, — это извлечение данных из структурированных документов. Данные, которые важны для вас. Примеры:
- Список цен на сайте сравнения цен.
- Результаты поиска ссылок из поисковой системы.
- Список ответов с сайта вопросов и ответов.
Прежде чем ответить, почему вы хотите использовать для этого Nokogiri, давайте рассмотрим более ручной подход. Еще в 2009 году на главной странице SitePoint внизу было облако тегов «Темы» :
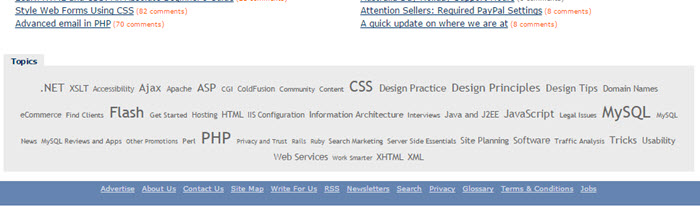
Допустим, я хотел, чтобы вы написали программу для очистки всех тем внутри этого облака (таких как Flash, Php, Architecture и т. Д.). Что бы вы сделали? Если бы я попросил вас описать шаги, которые ваша программа предпримет на очень высоком уровне, он, вероятно, начнется с двух вещей:
- Загрузите содержимое файла HTML (в качестве содержимого будут использоваться некоторые текстовые данные)
- Извлеките соответствующие данные из содержимого, полученного на шаге 1.
Вы можете выполнить шаг 1 многими способами в Ruby:
- Используйте
open-uriдля хранения содержимого HTML в строковой переменной (пример этого приведен ниже) - Используйте
watir-webdriverдля перехода на веб-страницу и получения ее HTML ( краткое объяснение приведено здесь)
Шаг 2 сложный. После того, как вы получите фактическое HTML-содержимое страницы, как вы извлекаете соответствующие данные, такие как элементы «Темы»? Конечно, вы можете использовать регулярные выражения (в конце концов, HTML-контент — это просто текст). Но это ужасная, ужасная идея . Текст HTML отличается от обычного текста (примером обычного текста являются слова, которые вы сейчас читаете), и есть гораздо лучшие методы для извлечения соответствующих данных из него.
Большая часть вашего времени будет потрачена на поиск шаблонов
На пути к извлечению данных из веб-страниц вы фактически потратите меньше всего времени на взаимодействие с Nokogiri. Большая часть вашего времени будет потрачена на поиск способа выбрать нужные данные на веб-странице. Это тот же принцип, что и регулярные выражения; вы тратите большую часть своего времени на выяснение фактического выражения, чтобы выбрать нужный текст. В парсере, таком как Nokogiri, вместо текста большая часть вашего времени будет потрачена на выяснение способов выбора элементов HTML (технически говоря, вы выбираете узлы, и есть 3 типа узлов: элемент, атрибут и текстовые узлы, однако). В подавляющем большинстве случаев вы будете писать выражения для выбора узлов элементов, потому что Nokogiri позволяет вам впоследствии легко получить информацию об атрибутах / текстовых узлах. Это отличный учебник, если вы не знакомы с узлами).
Большинство веб-сайтов имеют предсказуемую структуру в своем HTML-коде, и это в ваших интересах. Все, что вам нужно сделать, это описать эту структуру с помощью выражений xPath / CSS (о которых мы поговорим позже), и большая часть вашей работы выполнена. Думайте о выражениях xPath / CSS как о регулярных выражениях для HTML.
Давайте возьмем облако тегов SitePoint в качестве примера. Если вы проанализируете HTML-код с помощью такого инструмента, как Chrome inspector (щелкните правой кнопкой мыши что-либо в облаке тегов и нажмите «Проверить элемент»), вы заметите, что само облако тегов — это большой элемент ul с атрибутом class установленным в tagcloud . Внутри списка отдельные имена тегов хранятся в элементах li , и непосредственно внутри элементов li вас есть элементы, в которых данные, которые мы хотим получить, хранятся внутри элемента a как текст.
Конечно, вы могли бы написать одно сложное гигантское регулярное выражение для описания этих данных, но, как мы видели, это ужасная идея. Существует два основных способа, которые поддерживает Nokogiri для описания элементов HTML:
Выражения xPath
Большинство определений xPath довольно загадочно. По сути, xPath — это язык, который находит элементы в документе. Документ может быть либо HTML, либо XML (большинство учебных пособий по xPath используют XML-документы в своих примерах), это не имеет значения, если весь документ представляет собой структурированную коллекцию элементов , строительных блоков HTML / XML.
Ранее мы описывали, где размещать элементы нашего облака тегов, используя простой английский. Мы упоминали, что они хранятся в элементах непосредственно внутри элементов li которые сами находятся внутри элемента ul с атрибутом class tagcloud . Давайте переведем это в xPath:
//ul[@class='tagcloud']/li/a
Смущенный? Давайте проанализируем все шаг за шагом:
// - Start anywhere in the HTML document ul - get a <li> [@class="tagcloud"] - where the class attribute equals to tagcloud /li/a - get a <li> element with <a> child.
Мой совет — всегда начинать выражение xPath с // вместо одного /, потому что одна косая черта приведет вас к корню документа. С двойной косой чертой, вы ищете весь документ. Если бы мы использовали одну косую черту в приведенном выше примере, нам нужно было бы сделать что-то вроде этого:
/html/body/p/ul ..and so on
Потратьте как минимум 2 часа на ПРАКТИКУЮ xPath. Если бы кто-то сказал мне это, когда я начинал с Nokogiri, это избавило бы меня от многих головных болей!
Как практиковать xPath
Самый эффективный способ изучения xPath — это практиковать его в среде, которая обеспечит вам мгновенную обратную связь о том, работает ли ваше выражение xPath (например, Rubular для регулярных выражений).
Я рекомендую установить xPath Helper для Chrome и использовать его на своих любимых веб-сайтах. Перейдите на сайт Archive.org, который мы использовали в этой статье, и введите приведенное выше выражение, чтобы увидеть, что вы получите (совпадения имеют желтый фон):

Это также хороший ресурс для практики xPath с определенным контентом HTML. Что касается хороших руководств, чтобы начать, смотрите:
-
Учебник по w3cSchools xPath (не смущайтесь тем фактом, что они работают с XML вместо HTML, основная структура документов обоих типов одинакова).
-
Шпаргалка xPath (она также содержит примечания о том, как выбирать элементы с помощью селекторов CSS).
Я не могу подчеркнуть это достаточно: потратьте хотя бы несколько часов на практику xPath, если хотите работать с Нокогири . Изучение Nokogiri без предварительного изучения, как выбирать элементы HTML, используя что-то вроде xPath, похоже на изучение Word, не зная, как печатать! Напишите свои собственные выражения xPath, чтобы выбрать нужные данные на ваших любимых веб-сайтах. Некоторые браузеры имеют возможность генерировать выражения xPath для вас, но они делают их более сложными, чем они должны быть. Проверьте свои собственные выражения, введя их в помощник xPath и проверив, совпадают ли они с чем-либо.
CSS селекторы
Если вы когда-либо создавали какой-либо CSS, вы будете знать, что правило CSS состоит из селектора (где вы даете инструкции относительно того, к какому элементу применяется правило) и объявления. Вы можете использовать только часть селектора, чтобы выбрать любой элемент HTML в Nokogiri. Хорошее расширение, такое как SelectorGadget, дает мгновенную обратную связь для выбранных вами селекторов и является вашим лучшим выбором при их изучении. Для нашего примера облака тегов вот эквивалентное выражение селектора CSS, которое выберет те же элементы, что и предыдущее выражение xPath:
ul.tagcloud > li > a
Если вы не разбираетесь в селекторах CSS, вы, вероятно, тоже не знаете CSS. Отправляйтесь в школу W3C и приступайте к работе (отборщики рассматриваются в начале после того, как вы ознакомитесь с самыми основными темами).
Давайте напишем вашу первую программу Nokogiri с использованием селекторов.
Ваша первая программа Nokogiri
Эта программа выведет все имена тегов внутри нашего облака тегов SitePoint:
require 'nokogiri' require 'open-uri' html_data = open('http://web.archive.org/web/20090220003702/http://www.sitepoint.com/').read nokogiri_object = Nokogiri::HTML(html_data) tagcloud_elements = nokogiri_object.xpath("//ul[@class='tagcloud']/li/a") tagcloud_elements.each do |tagcloud_element| puts tagcloud_element.text end
Я намеренно сделал эту программу немного больше, пропуская немного синтаксического сахара, чтобы было легче объяснить.
В этой строке ВСЕ начинается:
nokogiri_object = Nokogiri::HTML(html_data)
Нокогири нужен СОДЕРЖАНИЕ, чтобы создать объект. В нашем примере этот контент получен при получении данных HTML с внешнего веб-сайта. Но так не должно быть! Допустим, я сохранил локальную копию файла HTML (вы можете скачать его здесь ) и поместил ее в ту же папку, что и ваша программа Ruby. Затем можно заменить данные, в html_data переменная html_data объявлена, следующим образом:
html_data = File.read('index.html')
Теперь запустите программу. Все будет работать как задумано. Nokogiri нужны некоторые данные, чтобы начать, и не имеет значения, поступают ли эти данные из удаленного места или с вашего жесткого диска. Вы часто будете видеть что-то вроде этого:
nokogiri_object = Nokogiri::HTML(open('http://web.archive.org/web/20090220003702/http://www.sitepoint.com/'))
Это сокращенная версия, в которой в одной строке происходит несколько вещей. Данные собираются и загружаются немедленно в Nokogiri. Если вы используете это, вам не нужна строка, где html_data .
Следующая часть:
Nokogiri::HTML(html_data)
создает новый объект Nokogiri. Вы не можете редактировать изображение в Photoshop, если не открыли его в программе, верно? Представьте, что вы создаете объект Nokogiri таким же образом: вы не можете делать что-то с HTML, если сначала не загрузите его в Nokogiri.
Как только у нас будет объект Nokogiri, мы можем вызывать методы для него. Как? Указывая ГДЕ найти нужные нам элементы HTML (точно так же, как набирая определенное слово в Блокноте, чтобы найти все его вхождения, мы делаем то же самое с селекторами xPath / CSS). Именно здесь вы будете проводить большую часть своего времени, выбирая «правильный» селектор и так далее.
Одна большая ошибка, которую я сделал вначале, заключалась в том, чтобы придумать выражение xPath / CSS и ввести его прямо в Nokogiri. Большую часть времени мое выражение было неправильным, и ничего не было выбрано, что приводило к неожиданным ошибкам Ruby. Чтобы избежать этого, сначала протестируйте выражение xPath / CSS, используя что-то вроде расширения Chrome, рекомендованного выше, и посмотрите, соответствуют ли они.
Следующая строка — это место, где мы просим наш объект Nokogiri дать HTML-элементу MATCHES (если есть) из предоставленного выражения:
nokogiri_object.xpath("//ul[@class='tagcloud']/li/a")
Если вы хотите использовать версию CSS, замените ее на:
nokogiri_object.css("ul.tagcloud > li > a") # The white space in the CSS selector is optional
Большой! Теперь у нас есть куча тегов cloud_elements, хранящихся в виде массива. Они хранятся в виде NodeSet , который представляет собой массив узлов. Ранее мы говорили об узлах, и сейчас я рекомендовал просматривать их как элементы HTML, поскольку 99% выражений xPath / CSS будут выбирать элементы HTML. Существуют варианты для выбора только текстовой / атрибутивной информации, но я бы предпочел поместить эту логику в Nokogiri, а не в xPath / CSS. Следующий фрагмент кода показывает это.
Когда у вас есть элементы, хранящиеся в массиве, выполните цикл, чтобы получить текст внутри них. Вот что происходит в последней части:
tagcloud_elements.each do |tagcloud_element| puts tagcloud_element.text end
Предположим, что требование изменилось, и вместо текста мы хотим получить значение атрибута href . Для этого измените tagcloud_element.text на tagcloud_element['href'] или tagcloud_element.attribute('href') . Так вы получаете любое значение атрибута. Замените href любым другим атрибутом ( id , class и т. Д.), Чтобы получить значение этого атрибута. Если вы попытаетесь получить атрибут, который не существует для элемента, в результате вы получите nil .
Полезные Нокогири Сниппетс
Я потратил более 2 часов на анализ кода на GitHub, который использует Nokogiri, и в 90% случаев происходил один и тот же шаблон: люди создавали новый объект Nokogiri, пытались получить элементы HTML с использованием определенного шаблона xPath / CSS, а затем получить атрибут текста этих элементов. Мы уже рассмотрели все эти вещи. Вот несколько других полезных вещей, которые вы можете сделать с Nokogiri, как только вы изучите основы. Мы будем использовать тот же пример облака тегов, что и в статье.
nokogiri_object.at_xpath("//ul[@class='tagcloud']/li/a")
Использование at_xpath (или at_css ) вместо xpath / css даст вам только первое совпадение. Если совпадений не найдено, возвращается nil .
tagcloud_elements.each do |tagcloud_element| puts tagcloud_element.to_html end
Получите HTML- to_html соответствующих элементов HTML с помощью метода to_html .
tagcloud_elements.each do |tagcloud_element| puts tagcloud_element.parent puts tagcloud_element.children puts tagcloud_element.next_sibling puts tagcloud_element.previous_sibling end
Это методы для навигации по объектной модели документа вашего соответствия.
Теперь вы готовы начать работу с Nokogiri без головной боли, которую испытывает большинство новичков! Не стесняйтесь комментировать ниже, если у вас есть какие-либо вопросы.