
Этим летом я работал в лаборатории в Массачусетском технологическом институте, сосредоточившись на некоторых исследованиях, связанных со сжатием информации при ее перемещении по сети. Большая часть моей работы была реализована в MATLAB. Это было не из-за каких-то особых предпочтений с моей стороны; просто так случается, что многие исследования (особенно те, что по математике) основаны на MATLAB.
Есть много вещей, которые мне нравятся в MATLAB. Все, что связано с матрицами (простой пример: создание матрицы с кучей нулей — это просто zeros(n, n) ), действительно просто, документация в целом довольно хорошая, и быстро начать работу с языком. Набор функций потрясающий, и, особенно если вы что-то делаете в компьютерном зрении, быстро увидеть результаты стандартных алгоритмов невероятно полезно.
Есть также много вещей, которые мне сильно не нравятся в MATLAB. В общем, создается впечатление, что MATLAB постоянно пытается помешать вам писать чистый, читаемый код. Создание абстракций неоправданно сложно, и концепция многократно используемых библиотек кажется чужой многим членам сообщества MATLAB. Нет прямого доступа к многопоточности или какой-либо здравой, обобщенной среде параллелизма. Кроме того, я думаю, что это довольно плохой признак того, что есть сайт с недокументированным MATLAB, который посвящен использованию «скрытых» частей MATLAB.
Предполагается, что Джулия выберет язык MATLAB как язык, который быстро подберет и наметит некоторые алгоритмы, но он также напоминает твердый язык, созданный специалистами по компьютерам. Конечно, если вы Rubyist, вы можете не заботиться о MATLAB для начала, так какой в этом смысл? Что ж, если вы выполняете какую-либо числовую работу, Джулия определенно стоит посмотреть: она дает вам ощущение динамического интерпретируемого языка с производительностью, близкой к производительности скомпилированного. Создание быстрой визуализации данных также очень просто.
Джулия может показаться немного странной на первый взгляд из-за отсутствия ООП и всего остального, но, приложив немного усилий, она определенно расширит ваши возможности. Эта статья не очень углубится в синтаксис Джулии, так как вы можете узнать это в другом месте довольно быстро. Вместо этого мы сосредоточимся на том, что делает Джулию интересной и классной. Мы проведем через матрицы, наборы данных, графики и рассмотрим несколько статистических функций. Мы не будем рассматривать каждую реализацию в Ruby, но постараемся сосредоточиться на разнице в философии двух языков.
Установка
К счастью, у Джулии есть хорошая страница загрузок, которая должна указать вам правильное направление. Я использую Juno IDE, основанную на Light Table, и позвольте мне сделать что-то вроде этого:
Это некоторый код Джулии, который оценивается, чтобы показать мне результаты прямо в редакторе. Когда мы рассмотрим некоторые функции построения графиков, удобство Juno поможет вам очень быстро увидеть результаты ваших усилий.
Матрицы
Матрицы — это хлеб с маслом численных вычислений. Все виды алгоритмов зависят от операций, которые обычно определяются на матрицах. Довольно распространенным примером является размытие изображения: размытие часто применяется путем «свертки» (т. Е. С использованием некоторой странной операции) ядра (т. Е. Типа матрицы) с изображением (другой матрицы). По сути, мы хотим, чтобы любой числовой язык имел очень сильную поддержку матриц.
В Ruby есть неплохая поддержка матриц. У нас есть класс Matrix, который предоставляет нам удобные методы, такие как Matrix.zero(n) для создания n по n матриц нулей. Тем не менее, матричные операции в Ruby обычно не очень быстрые (особенно по сравнению с компилируемыми языками). У Джулии есть замечательные вспомогательные методы для матриц, и они достигают C-подобной производительности. Давайте посмотрим на пример. Запустите Julia REPL (к счастью, у него есть один из них) и введите следующее:
x = zeros(10, 10)
Вывод должен выглядеть так:
10x10 Array{Float64,2}: 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Вот так у нас есть матрица из 10 на 10 нулей. Это очень похоже на вызов Matrix.zeros(10, 10) , но есть очень важное отличие: вывод на самом деле выглядит как матрица! Это может показаться тривиальной разницей. Тем не менее, при работе с большим количеством матриц очень важно иметь красиво отформатированные матрицы, когда вы пытаетесь увидеть результаты. Давайте сделаем что-нибудь более интересное:
x = rand(10, 10)
Это должно дать нам:
10x10 Array{Float64,2}: 0.614455 0.166746 0.933275 … 0.777238 0.662781 0.012962 0.000197243 0.975239 0.0263813 0.784601 0.251306 0.0359492 0.0881394 0.450103 0.895747 0.0219986 0.196202 0.259326 0.256392 0.28074 0.542471 0.830691 0.9528 0.905797 0.536424 0.661746 0.885126 0.261195 0.198792 0.03582 0.28776 0.275747 0.94569 … 0.0970672 0.269422 0.246199 0.953955 0.421148 0.0946357 0.677456 0.796799 0.828503 0.492165 0.481043 0.857201 0.862093 0.0634439 0.97161 0.276454 0.208118 0.313016 0.0972178 0.557233 0.00431404 0.117841 0.891073 0.0320966 0.0487335 0.830744 0.426995
Джулия усекает вывод, но ясно, что мы видим матрицу 10 на 10 псевдослучайных чисел от 0 до 1. Это можно сделать с помощью небольшого волшебства Matrix.build в Ruby.
Скалярное умножение довольно распространено, поэтому в Юлии это действительно легко:
x = rand(10, 10) * 10
Как насчет умножения матриц вместе:
x = rand(10, 10) * zeros(10, 10)
Что если мы хотим проиндексировать определенный элемент матрицы? Позвольте мне поразить вас фактом: массивы / матрицы Джулии индексируются одним. Успокойся, начни дышать. Мир не закончится. Да, условия вашего цикла будут меняться. Да, это обычно довольно раздражает, если вы работаете с не-MATLAB и не-R фоном, но к нему довольно легко привыкнуть.
Кроме того, если вы пишете тонны кода, работающего с отдельными элементами матрицы, вы, вероятно, пропускаете какую-то стандартную матричную операцию, которая позволит вам выполнять то, что вы делаете, гораздо проще (примечание: я не использую это как оправдание для индексации Юлии 1, но это хорошо иметь в виду).
Все идет нормально. На самом деле мы не представили, что Руби тоже не делает безболезненным. Но есть общее мнение о Джулии, которое проясняет, что она высоко ценит матрицы: красивая печать, тот факт, что вызовы создания матриц являются функциями верхнего уровня и т. Д. Однако, есть еще много вещей, которые делают Джулию довольно уникальной.
Давайте рассмотрим одну особенность, которую Юлия позаимствовала у R: тип NA. Часто при анализе данных у нас есть некоторые значения данных, которые по какой-то причине недопустимы. Итак, у нас есть наш начальный набор данных с некоторыми недопустимыми значениями, а затем мы выполняем некоторые операции с набором данных, чтобы произвести вывод. Но после обработки данных мы не хотим рассматривать результаты, основанные на недопустимых значениях. Мы можем исправить эту проблему с типом NA. Везде, где у нас есть недействительные данные, замените их на «NA». Впоследствии, где бы у нас не было вычисления с участием NA, мы получим взамен NA. Другими словами, вычисления на неверных данных приводят к неверным данным. Чтобы увидеть его в действии, нам сначала нужно получить пакет «DataArrays». У Джулии фантастическая система управления пакетами, поддерживаемая прямо на языке.
Легко установить пакет:
Pkg.add("DataArrays")
Теперь создайте массив, чтобы мы могли вставить в него «NA»:
using DataArrays x = @data(rand(10, 10)) x[1, 1] = NA
В данный момент не беспокойтесь о том, что делает @data : он более или менее меняет тип матрицы, поэтому мы можем поместить в нее значения «NA». Давайте попробуем вычисление:
y = x*2
Это должно дать нам:
NA 0.553053 0.695716 0.284487 … 1.9758 0.761262 0.4869 1.3595 0.0468469 1.31732 1.83256 1.70817 1.43662 0.930509 0.306142 0.286241 0.982634 0.434252 1.94063 1.64462 0.731219 1.88406 1.70816 1.08887 0.234274 1.45693 1.06927 1.60651 0.503428 0.362866 0.335749 1.88895 0.341048 0.0441141 0.951636 0.774465 0.789801 1.23474 0.0640433 … 1.92382 1.20227 1.0657 1.38033 1.46768 1.78678 1.95522 1.53592 0.211695 0.631171 1.09145 1.32949 1.59082 1.52581 1.50151 0.062626 1.02838 0.386194 1.66468 1.37072 0.163497 0.522523 1.24837 0.880371 1.16056 0.496622 0.994359 1.08291 0.866378 0.187132 1.51157
Большой! Неверные данные привели к неверным данным.
Немного интереснее было бы возведение в квадрат матрицы:
x*x
Это даст нам:
10x10 DataArray{Float64,2}: NA NA NA NA … NA NA NA NA NA 3.14293 3.53757 2.4257 3.8196 4.36326 2.44844 3.22518 NA 2.36765 2.77693 2.60346 3.25948 2.67558 1.35156 2.13138 NA 2.46748 3.67635 3.47746 3.8359 4.51773 2.33752 2.99455 NA 1.90375 2.17352 1.53465 2.25778 2.68 1.34128 1.9858 NA 1.80034 2.47738 2.62089 … 2.9921 2.76951 1.47433 2.18699 NA 2.9391 3.8815 3.72826 4.45572 5.03061 2.59674 3.34063 NA 2.25157 3.12992 2.76169 3.43634 4.00735 2.01751 2.56007 NA 1.62191 2.51771 2.71106 2.91424 2.76869 1.79907 2.02696 NA 1.96264 2.53315 2.69743 3.19891 3.17627 1.44995 2.4413
Вау, что только что произошло? Хорошо, если вы немного помните свою линейную алгебру, вспомните места, где значение «NA» будет использоваться для вычисления позиции в матрице x*x .
Мы только коснулись того, что Джулия может делать с матрицами: чертовски много чего еще . Исходя из Ruby, важность, которую Джулия придает матрицам, поначалу довольно странная. Потратив немного времени на работу в тех областях, к которым обычно применяется Джулия (подумайте много цифр и применили математику), становится понятно, почему.
Данные
Джулия заимствовала еще одну идею от R: готовые наборы данных. R поставляется с набором данных, которые вы можете сразу начать использовать. Юлия предоставляет это нам с пакетом RDatasets . Давайте возьмемся за это:
Pkg.add("RDatasets")
Начните использовать это тоже:
using RDatasets
Вот довольно стандартный набор данных под названием «ирис»:
dataset("datasets", "iris") 150x5 DataFrame | Row | SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |-----|-------------|------------|-------------|------------|-------------| | 1 | 5.1 | 3.5 | 1.4 | 0.2 | "setosa" | | 2 | 4.9 | 3.0 | 1.4 | 0.2 | "setosa" | | 3 | 4.7 | 3.2 | 1.3 | 0.2 | "setosa" | | 4 | 4.6 | 3.1 | 1.5 | 0.2 | "setosa" | | 5 | 5.0 | 3.6 | 1.4 | 0.2 | "setosa" | | 6 | 5.4 | 3.9 | 1.7 | 0.4 | "setosa" | | 7 | 4.6 | 3.4 | 1.4 | 0.3 | "setosa" | | 8 | 5.0 | 3.4 | 1.5 | 0.2 | "setosa" | | 9 | 4.4 | 2.9 | 1.4 | 0.2 | "setosa" | | 10 | 4.9 | 3.1 | 1.5 | 0.1 | "setosa" | | 11 | 5.4 | 3.7 | 1.5 | 0.2 | "setosa" |
Хотя эти данные могут показаться немного бесполезными (я имею в виду, что мы всегда можем прочитать их из CSV-файла в Ruby), некоторые образцы данных всегда у вас под рукой, когда вы пытаетесь набросать некоторые идеи в коде. Обратите внимание, что данные хранятся в Julia DataFrame, который является способом помещения данных различных типов в одну «матрицу». С одним пакетом у нас теперь есть доступ к широкому диапазону наборов данных .
Черчение
Одна из областей, в которой Джулия действительно выделяется, — это возможность быстро получить представление о данных. Чтобы сделать это, составление некоторой части данных обычно является хорошей идеей. Я не нашел много надежных, полезных библиотек Ruby для построения графиков. Долгое время Скраффи был лидером в этой области, но, похоже, развития не происходило. Мы посмотрим на Gadfly, довольно стандартный графический инструментарий Julia. Он основан на идеях из многоуровневой грамматики графики, которая описывает, как построить разумную систему создания графики.
Классический «привет мир» статистических графиков — это «радужная оболочка». Набор данных «ирис» описывает некоторые характеристики нескольких видов цветов ириса. Мы посмотрим, как сделать из них сюжет.
Во-первых, нам нужна библиотека черчения:
Pkg.add("Gadfly")
Давайте построим наш первый сюжет:
using RDatasets using Gadfly plot(dataset("datasets", "iris"),x="SepalLength", y="SepalWidth", Geom.point)
Хорошо, что, черт возьми, этот plot называется? Он принимает DataFrame в качестве первого аргумента (предоставленного из RDatasets) и необязательные параметры для имен переменных x и y (которые, если вы посмотрите на вывод набора данных ранее, являются именами столбцов в DataFrame). Наконец, мы передаем «Geom.point», который сообщает Gadfly, что мы хотим сделать точечный график. Результаты выглядят очень хорошо:
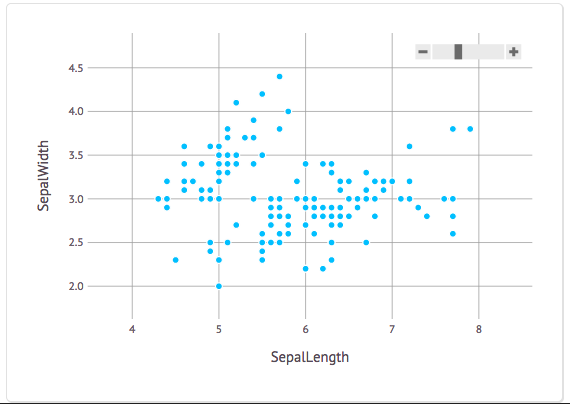
Если вы используете Juno (Julia IDE), вы сможете увидеть свои результаты очень быстро. У нас есть букет видов цветов. Как насчет раскрасить их по-разному на графике? По сути, мы хотим, чтобы цвет определялся одним из столбцов iris DataFrame:
plot(dataset("datasets", "iris"),x="SepalLength", y="SepalWidth", color="Species",Geom.point)
Мы добавили color="Species" чтобы связать цвет с колонкой. Проверьте это:
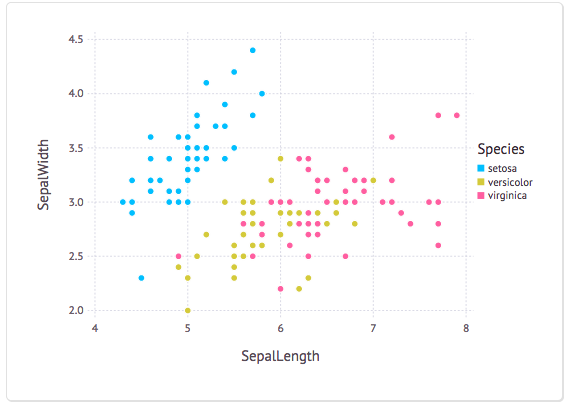
Хорошо, достаточно с точечными графиками. Что если бы мы хотели изучить распределение длины чашелистика для каждого из разных видов? Легко:
plot(dataset("datasets", "iris"), x = "Species", y = "SepalLength", Geom.boxplot)
Вывод тоже выглядит красиво:
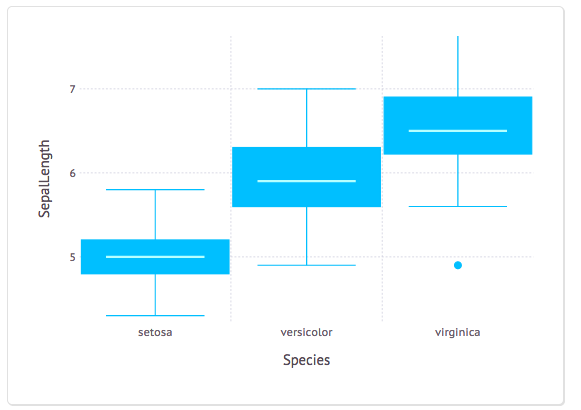
Статистика
Конечно, если мы строим графики, нас, вероятно, интересует статистика, связанная с данными. К счастью, Джулия предоставляет множество полезных утилит для извлечения информации из набора данных. Исходя из Ruby, может показаться странным иметь эти функции в глобальном пространстве имен. Но это принципиальная разница между Руби и Джулией. Под Ruby подразумевается язык общего назначения, ориентированный на такие вещи, как веб-разработка, которая требует обширной компартментализации. С другой стороны, Julia — это язык общего назначения, предназначенный для научных вычислений, где традиция состоит в том, чтобы «наиболее используемые» вещи были спереди и в центре.
Давайте сначала назовем наш набор данных чем-то разумным:
iris = dataset("datasets", "iris")
Вероятно, одна из самых полезных функций, чтобы получить контроль над вашими данными, describe . Поверни на iris :
describe(iris)
Вывод (усеченный) должен выглядеть примерно так:
SepalLength Min 4.3 1st Qu. 5.1 Median 5.8 Mean 5.843333333333334 3rd Qu. 6.4 Max 7.9 NAs 0 NA% 0.0%
Это дает вам сводку из пяти чисел и некоторую другую информацию о каждом столбце набора данных. Мы можем легко получить доступ к определенным столбцам iris DataFrame:
sepal_lengths = iris[:SepalLength]
Мы можем довольно легко узнать подробности о столбце:
mean(sepal_length) #mean std(sepal_length) #standard deviation
Завершение
Вау, это было быстро Пока что мы только взглянули на некоторые вещи, которые делают Джулию замечательной для написания кода, но даже в этом случае различия с Ruby очевидны. Юлия предназначена для работы с числами, матрицами и тому подобным. Ruby, с другой стороны, хочет убедиться, что вы можете делать это, если хотите, но это не является главным приоритетом. В следующей статье о Джулии мы более подробно рассмотрим возможности, а также представим параллельные вычислительные конструкции в языке.