Почти каждый тип хранилища данных имеет некоторую форму индексации. Типичная реляционная база данных, такая как MySQL или PostreSQL, может индексировать поля для эффективного запроса. Большинство баз данных документов, таких как MongoDB, также содержат индексацию. Индексация в реляционной базе данных почти всегда выполняется по одной причине: скорость. Однако иногда вам нужно больше, чем просто скорость, вам нужна гибкость. Вот где Solr входит.
В этой статье я хочу рассказать о том, как Solr может использовать возможности индексации вашего проекта. Я начну с введения индексации и расширения, чтобы показать, как Solr можно использовать в приложении Rails.
Что такое индекс?
Индексирование данных — это очень старая концепция. Это далеко предшествует реляционным базам данных и компьютерам полностью. Индексные карточки использовались в самых разных ситуациях, особенно в библиотечных каталогах. Библиотекари индексируют свои книги, используя ряд методов, одним из которых является алфавитизация. Простой индекс можно придумать, перечислив все книги, начинающиеся с А, затем все книги, начинающиеся с В, и так далее. При поиске книги, скажем «Сказка о двух городах», вы смотрите на первую букву названия «А», а затем сразу переходите к разделу «А» в указателе вашей библиотеки.
Целью индексации, независимо от того, где она применяется, всегда является организация данных, чтобы их можно было быстро извлечь. Вы можете себе представить организацию библиотечного каталога по жанрам, в этом случае «Повесть о двух городах» может попасть в «Художественную литературу». Затем библиотекарь сразу перейдет в раздел «Художественная литература».
Индексация реляционной базы данных
Все готовые к использованию системы реляционных баз данных содержат индексы. Часто требуется индексировать по внешнему ключу, чтобы запросы к этому внешнему ключу можно было выполнять эффективно. Это может значительно повысить производительность при выполнении соединений, например. Как MySQL, так и PostgreSQL поддерживают «полнотекстовую индексацию», которая позволяет запрашивать в большом блоке текста биты и фрагменты, содержащиеся в нем.
Если вы просто хотите, чтобы на вашем сайте было простое окно поиска, полнотекстовая индексация с использованием уже существующей реляционной базы данных может оказаться подходящим вариантом. У него есть два основных преимущества: вы работаете с одним и тем же инструментом, и ваши показатели всегда актуальны. У него есть один существенный недостаток: он недостаточно гибок, чтобы справляться с «нестандартными» ситуациями индексации.
Solr — когда вашей реляционной базы данных недостаточно
Если вы придерживаетесь реляционной базы данных для всех ваших поисковых запросов, вы часто будете создавать неловкие и неэффективные запросы. Это хороший признак того, что вы достигли пределов того, что может предоставить база данных. Вот где приходит Solr. Он предназначен для расширения существующей реляционной базы данных и предоставления дополнительных средств для запроса данных.
Solr — очень зрелая технология, изначально созданная в 2004 году и используемая такими крупными собаками, как Netflix и Интернет-архив . Основанный на Lucene , Solr предоставляет вам другой способ определения ваших показателей. По сути, Solr помогает переопределить ваши реляционные данные в более ориентированную на документы структуру, эффективную для запросов.
Вот как Solr вписывается в ваше Rails-приложение:
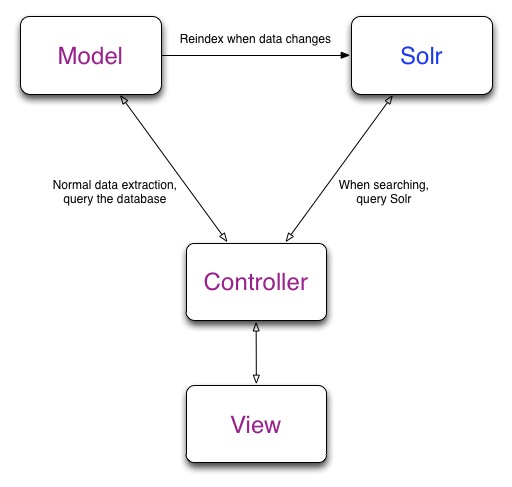
Sunspot — Ruby / Solr Love Child
Sunspot — король интеграции между Ruby и Solr. Он предоставляет чистый DSL (предметно-ориентированный язык), чтобы определить, как вы хотите, чтобы ваши реляционные данные были проиндексированы с помощью Solr. Придумай пример.
Допустим, у нас есть модель продукта, которая имеет следующие атрибуты:

У нас есть нормальная модель ActiveRecord для определения нашей базы данных с помощью Ruby:
| class Product < ActiveRecord::Base | |
| validates :name, :color, :used, :presence => true | |
| validates :name, :uniqueness => true | |
| validates :used, :inclusion => {:in => [true, false]} | |
| end |
 by
by Если мы хотим найти продукты с названием «города» и ожидаем увидеть «Сказку о двух городах», мы могли бы построить следующий запрос:
| Product.where(«name LIKE ‘%?%'», ‘cities’).all |
Это не достаточно гибко в большинстве случаев. Что если бы мы хотели, чтобы поиск «городов» включал также «Нью-Йорк: большой город»? Этот метод не даст нам желаемых результатов. Давайте представим Sunspot.
Чтобы начать работу с Sunspot, поместите его в свой Gemfile:
| gem ‘sunspot_rails’ | |
| gem ‘sunspot_solr’ # optional pre-packaged Solr distribution for use in development |
Хватай драгоценные камни:
| bundle |
Создайте файл конфигурации Sunspot, чтобы ваше приложение Rails знало, где найти сервер:
| rails g sunspot_rails:install |
Включив в свой Gemfile гем ‘sunspot_solr’, Sunspot предоставит вам копию Solr. Запустите сервер Solr, выполнив:
| rake sunspot:solr:start |
На этом этапе вы должны начать работать с Solr. Давайте переопределим нашу модель продукта. Я не буду включать проверки снова, я просто притворюсь, что они все еще существуют.
| class Product < ActiveRecord::Base | |
| searchable do | |
| text :name, :boost => 2.0 | |
| text :color | |
| boolean :used | |
| end | |
| end |
То, что мы сделали в приведенной выше модели, это скажем Solr, как мы хотим, чтобы она индексировала нашу модель Product. Мы сказали, что поля имени и цвета следует рассматривать как текст, а используемые поля — как логические. Определение чего-либо как «текста» в Sunspot означает, что оно доступно для полнотекстового поиска. Другими словами, при поиске по полям имени и цвета он находит частичные совпадения (т. Е. При поиске «хлеб» будет возвращаться «хлеб с маслом»). Мы также сказали Sunspot, что мы хотим, чтобы поле имени имело двойную (2.0) распространенность как поле цвета. Если при поиске отображаются результаты как по имени, так и по цвету, результаты, соответствующие полю имени, будут более релевантными.
Поиск данных в индексе Solr обычно происходит на уровне контроллера. Давайте посмотрим, как мы можем запросить Solr для продуктов, соответствующих «городам», которые не используются:
| class ProductsController < ApplicationController | |
| def search | |
| Product.search do | |
| fulltext ‘cities’ | |
| with :used, false | |
| end | |
| end | |
| end |
Этот поиск вернул бы новые копии «Повести о двух городах» и любых других книг с «городами». По умолчанию поиск не учитывает регистр. Поиски также могут содержать диапазоны, сравнения дат, наборы включений, больше и меньше запросов и многое другое.
Как видно из модели и определения поиска, Sunspot предоставляет нам чистый и читаемый DSL. Это один из моих любимых аспектов библиотеки.
Копаем глубже — Solr Конфигурация
Вы можете многого достичь, даже не касаясь конфигурации Solr. По умолчанию Solr разбивает текстовые поля на отдельные слова и затем преобразует их в строчные. Это позволяет полнотекстовым запросам быть чувствительными к регистру. Gem ‘sunspot_solr’ дает нам файл schema.xml по умолчанию для использования. schema.xml — это обычно то место, куда вы пойдете, когда захотите настроить Solr на более низком уровне (вы также можете коснуться solrconfig.xml). Этот файл обычно находится в {RAILS ROOT} /solr/conf/schema.xml. Давайте посмотрим, как определяются наши текстовые поля:
| <fieldType name=«text« class=«solr.TextField« omitNorms=«false«> | |
| <analyzer> | |
| <tokenizer class=«solr.StandardTokenizerFactory«/> | |
| <filter class=«solr.StandardFilterFactory«/> | |
| <filter class=«solr.LowerCaseFilterFactory«/> | |
| </analyzer> | |
| </fieldType> |
У нас есть три интересных определения в конфигурации Solr по умолчанию, поставляемой с Sunspot. Вот что они делают:
- StandardTokenizerFactory маркирует наш текст. Другими словами, он разбивает наше текстовое поле на отдельные слова.
- StandardFilterFactory предоставляет Solr средство поиска данных по токенизированному тексту.
- LowerCaseFilterFactory преобразует все токенизированные слова в строчную форму.
Новые фильтры могут быть добавлены в конец этого определения текстового поля. Фильтры выполняются последовательно, поэтому фильтры, добавленные в конец списка, будут каскадно фильтроваться перед ним.
Если бы мы хотели, чтобы наш поиск по «городам» возвратил книгу под названием «Нью-Йорк: большой город», мы бы использовали стеммер. Цель любого стеммера — разбить слово на «стебель». Таким образом, тогда «ходил», «ходил» и «ходок» был бы «гулять». Давайте сделаем наш поиск более надежным, задав стеммер Solr для наших текстовых полей:
| <fieldType name=«text« class=«solr.TextField« omitNorms=«false«> | |
| <analyzer> | |
| <tokenizer class=«solr.StandardTokenizerFactory«/> | |
| <filter class=«solr.StandardFilterFactory«/> | |
| <filter class=«solr.LowerCaseFilterFactory«/> | |
| <filter class=«solr.PorterStemFilterFactory«/> | |
| </analyzer> | |
| </fieldType> |
Теперь мы сказали Solr, что мы хотим остановить любой текст, который мы индексируем после того, как он был сначала токенизирован, а затем преобразован в строчные. У нас проблема, однако. Не все стеммеры достаточно умны, чтобы заменить «и» на «у» в случае «городов». На самом деле эту работу обычно оставляют на усмотрение лемматизатора . Stemmers и lemmatizers оба специфичны для языка. То есть, по понятным причинам определение английского слова сильно отличается от определения румынского слова.
Если бы мы попытались остановить слово «города», то на самом деле мы получили бы слово «citi», которое явно неверно. Попробуйте использовать несколько разных слов на этом сайте . Такое ощущение, что мы столкнулись с Solr, и это правда. Solr не имеет встроенного лемматизатора. Мы могли бы написать такой фильтр, но это была бы кропотливая задача. Возможно, лучшим вариантом является использование SynonymFilterFactory .
Копаем еще глубже — Solr Синонимы
Solr понимает синонимы и позволяет нам определять свои собственные. Вы можете настроить Solr так, чтобы он возвращал совпадения для разных слов на основе его синонимов. Такие синонимы определены в файле synonyms.txt следующим образом:
| # citi is the stem of cities | |
| citi => city | |
| # copi is the stem of copies | |
| copi => copy |
Приведенный выше файл synonyms.txt сообщает Solr, что мы хотели бы рассматривать слово «citi» так, как будто это слово «город», а слово «copi» — как «копия».
Теперь нам нужно поместить правильный фильтр в наш файл schema.xml:
| <fieldType name=«text« class=«solr.TextField« omitNorms=«false«> | |
| <analyzer> | |
| <tokenizer class=«solr.StandardTokenizerFactory«/> | |
| <filter class=«solr.StandardFilterFactory«/> | |
| <filter class=«solr.LowerCaseFilterFactory«/> | |
| <filter class=«solr.PorterStemFilterFactory«/> | |
| <filter class=«solr.SynonymFilterFactory« synonyms=«synonyms.txt« /> | |
| </analyzer> | |
| </fieldType> |
Теперь мы сказали Solr, что хотели бы рассматривать основы «citi» и «copi» как их законную лемматизацию, «city» и «copy». На этом этапе, когда индексируется книга с названием «Нью-Йорк: большой город», выполняются следующие шаги:
- «Нью-Йорк: большой город» разбит на токены: [«Новый», «Йорк», «А», «Большой», «Город»]
- Каждый токен конвертируется в нижний регистр: [«новый», «йорк», «а», «большой», «город»]
Когда выполняется поиск «городов», выполняются следующие шаги:
- «Города» разбиваются на токены (в данном случае только один токен): [«города»]
- Каждый токен конвертируется в нижний регистр (в данном случае не действует): [«города»]
- Найдены книги, соответствующие «городам»
- Каждый жетон стоит: [«citi»]
- Найдены книги, соответствующие «citi»
- Каждый токен проверяется или синонимы: [«город»]
- Найдены книги, соответствующие «городу» — возвращение «Нью-Йорк: большой город»
Завершение
Solr — это феноменальная технология, которая предоставляет мощные возможности поиска. Мы коснулись некоторой истории, стоящей за индексацией, и основных моментов поиска в реляционной базе данных. Мы также рассмотрели, как мы можем использовать Solr в приложении Rails с помощью Sunspot и углубиться в конфигурацию Solr, чтобы показать, как справляться с жестким краевым регистром. Но мы только поцарапали поверхность. Одна из самых мощных функций Solr — это огранка, концепция разделения вашего индекса на иерархические порции, в которых вы можете углубиться, чтобы найти релевантные результаты. Обычно, когда вы углубляетесь в категорию (фасет), большее количество категорий отображается, чтобы показать более глубокие слои фасетов. Sunspot справляется с огранкой изящества. Newegg и Amazon демонстрируют отличное использование огранки при изучении категорий на левой навигационной панели .
Я надеюсь, что эта статья заинтриговала вас, раскрывая некоторые более глубокие особенности Solr. Есть чему поучиться, и шаг за шагом это всегда лучший подход. Я рекомендую вам освоиться с Solr, чтобы вы могли легко обрабатывать сложные поисковые запросы.