Впервые я услышал о Spark в конце 2013 года, когда заинтересовался Scala — языком, на котором написан Spark. Некоторое время спустя я сделал забавный проект по науке о данных, пытаясь предсказать выживание на Титанике . Это оказалось отличным способом познакомиться с концепциями и программированием Spark. Я настоятельно рекомендую его всем начинающим разработчикам Spark, которые ищут место для начала.
Сегодня Spark внедряют такие крупные игроки, как Amazon, eBay и Yahoo! Многие организации запускают Spark на кластерах с тысячами узлов. Согласно FAQ Spark, самый большой известный кластер имеет более 8000 узлов. Действительно, Spark — это технология, которую стоит отметить и изучить.

Эта статья содержит введение в Spark, включая примеры использования и примеры. Он содержит информацию с веб-сайта Apache Spark, а также книгу Learning Spark — молниеносный анализ больших данных.
Что такое Apache Spark? Введение
Spark — это проект Apache, рекламируемый как «молниеносные кластерные вычисления». Он имеет процветающее сообщество open-source и является самым активным проектом Apache на данный момент.
Spark обеспечивает более быструю и общую платформу обработки данных. Spark позволяет запускать программы в 100 раз быстрее в памяти или в 10 раз быстрее на диске, чем Hadoop. В прошлом году Spark взял на себя Hadoop, завершив конкурс Daytona GraySort объемом 100 ТБ в 3 раза быстрее на одну десятую числа машин, и он также стал самым быстрым движком с открытым исходным кодом для сортировки петабайта.
Spark также позволяет быстрее писать код, поскольку в вашем распоряжении более 80 высокоуровневых операторов. Чтобы продемонстрировать это, давайте посмотрим на «Hello World!» BigData: пример подсчета слов. Написанный на Java для MapReduce, он содержит около 50 строк кода, тогда как в Spark (и Scala) вы можете сделать это так просто:
|
1
2
3
4
|
sparkContext.textFile("hdfs://...") .flatMap(line => line.split(" ")) .map(word => (word, 1)).reduceByKey(_ + _) .saveAsTextFile("hdfs://...") |
Другим важным аспектом при изучении использования Apache Spark является интерактивная оболочка (REPL), которую она предоставляет «из коробки». Используя REPL, можно проверить результат каждой строки кода без необходимости сначала кодировать и выполнять всю работу. Таким образом, путь к рабочему коду намного короче, и возможен специальный анализ данных.
Дополнительные ключевые функции Spark включают в себя:
- В настоящее время предоставляет API в Scala, Java и Python с поддержкой других языков (например, R)
- Хорошо интегрируется с экосистемой Hadoop и источниками данных (HDFS, Amazon S3, Hive, HBase, Cassandra и т. Д.)
- Может работать на кластерах, управляемых Hadoop YARN или Apache Mesos, а также может работать автономно
Ядро Spark дополняется набором мощных высокоуровневых библиотек, которые можно беспрепятственно использовать в одном приложении. Эти библиотеки в настоящее время включают SparkSQL, Spark Streaming, MLlib (для машинного обучения) и GraphX, каждая из которых более подробно описана в этой статье. Дополнительные библиотеки Spark и расширения в настоящее время находятся в стадии разработки.
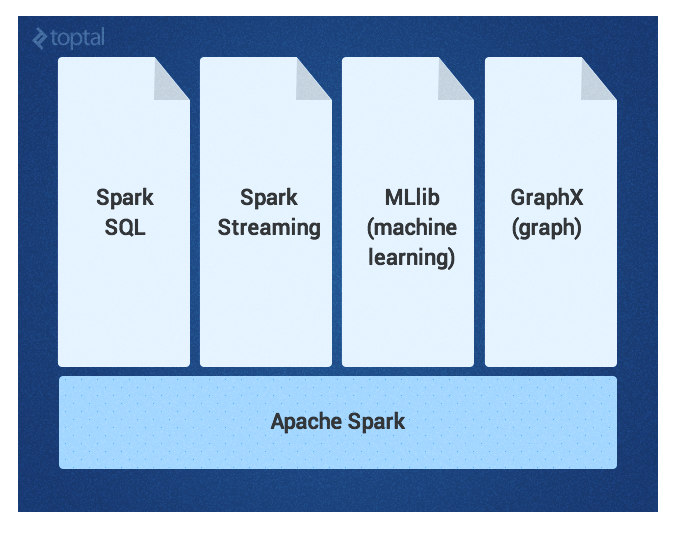
Spark Core
Spark Core — базовый движок для крупномасштабной параллельной и распределенной обработки данных. Он отвечает за:
- управление памятью и устранение неисправностей
- планирование, распределение и мониторинг заданий в кластере
- взаимодействуя с системами хранения
Spark представляет концепцию RDD (Resilient Distributed Dataset) , неизменяемого отказоустойчивого распределенного набора объектов, с которым можно работать параллельно. СДР может содержать любой тип объекта и создается путем загрузки внешнего набора данных или распространения коллекции из программы драйвера.
СДР поддерживают два типа операций:
Преобразования в Spark являются «ленивыми», то есть они не сразу вычисляют свои результаты. Вместо этого они просто «запоминают» выполняемую операцию и набор данных (например, файл), для которого должна быть выполнена операция. Преобразования фактически вычисляются только тогда, когда вызывается действие и результат возвращается в программу драйвера. Такая конструкция позволяет Spark работать более эффективно. Например, если большой файл был преобразован различными способами и передан первому действию, Spark обрабатывает и возвращает результат только для первой строки, а не выполняет работу для всего файла.
По умолчанию каждый преобразованный СДР может пересчитываться каждый раз, когда вы выполняете над ним действие. Однако вы также можете сохранить RDD в памяти, используя метод persist или cache, и в этом случае Spark сохранит элементы в кластере для более быстрого доступа при следующем запросе.
SparkSQL
SparkSQL — это компонент Spark, который поддерживает запросы данных через SQL или с помощью языка запросов Hive . Он возник в виде порта Apache Hive для запуска поверх Spark (вместо MapReduce) и теперь интегрирован со стеком Spark. В дополнение к обеспечению поддержки различных источников данных, он позволяет создавать запросы SQL с преобразованиями кода, что приводит к очень мощному инструменту. Ниже приведен пример запроса, совместимого с Hive:
|
1
2
3
4
5
6
7
8
|
// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")// Queries are expressed in HiveQLsqlContext.sql("FROM src SELECT key, value").collect().foreach(println) |
Spark Streaming
Spark Streaming поддерживает обработку потоковых данных практически в реальном времени, таких как файлы журналов рабочего веб-сервера (например, Apache Flume и HDFS / S3), социальные сети, такие как Twitter, и различные очереди сообщений, такие как Kafka. Под капотом Spark Streaming получает потоки входных данных и делит данные на пакеты. Затем они обрабатываются механизмом Spark и генерируют окончательный поток результатов в пакетном режиме, как показано ниже.
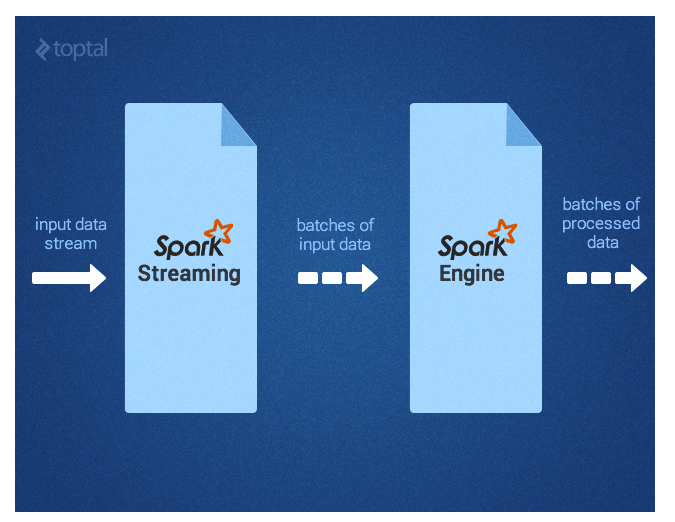
Spark Streaming API близко соответствует Spark Core, что облегчает программистам работу в мире как пакетных, так и потоковых данных.
MLlib
MLlib — это библиотека машинного обучения, которая предоставляет различные алгоритмы, предназначенные для масштабирования в кластере, для классификации, регрессии, кластеризации, совместной фильтрации и т. Д. (Дополнительную информацию по этой теме можно найти в статье Toptal об машинном обучении ). Некоторые из этих алгоритмов также работают с потоковыми данными, такими как линейная регрессия с использованием обычных наименьших квадратов или кластеризация с помощью k-средних (и многое другое). Apache Mahout (библиотека машинного обучения для Hadoop) уже отвернулась от MapReduce и объединила усилия на Spark MLlib.
Graphx
GraphX — это библиотека для управления графами и выполнения параллельных графов операций. Он предоставляет единый инструмент для ETL, исследовательского анализа и итерационных вычислений графа. Помимо встроенных операций для манипулирования графами, он предоставляет библиотеку общих алгоритмов графов, таких как PageRank.
Как использовать Apache Spark: сценарий использования обнаружения событий
Теперь, когда мы ответили на вопрос «Что такое Apache Spark?», Давайте подумаем о том, какие проблемы или проблемы могут быть использованы наиболее эффективно.
Недавно я наткнулся на статью об эксперименте по обнаружению землетрясения путем анализа потока в Твиттере . Интересно, что было показано, что этот метод, скорее всего, будет информировать вас о землетрясении в Японии быстрее, чем Японское метеорологическое агентство. Несмотря на то, что они использовали разные технологии в своей статье, я думаю, что это отличный пример того, как мы могли бы использовать Spark с упрощенными фрагментами кода и без связующего кода.
Во-первых, нам нужно будет отфильтровать твиты, которые кажутся актуальными, например, «землетрясение» или «сотрясение». Мы могли бы легко использовать Spark Streaming для этой цели следующим образом:
|
1
2
|
TwitterUtils.createStream(...) .filter(_.getText.contains("earthquake") || _.getText.contains("shaking")) |
Затем нам нужно будет выполнить некоторый семантический анализ твитов, чтобы определить, ссылаются ли они на текущее землетрясение. Твиты типа «Землетрясение!» или «Сейчас трясется», например, можно было бы рассмотреть положительные совпадения, тогда как твиты, такие как «Участие в конференции по землетрясению» или «Вчерашнее землетрясение было страшным», не будут. Для этой цели авторы статьи использовали машину опорных векторов (SVM). Мы сделаем то же самое здесь, но также можем попробовать потоковую версию . Результирующий пример кода из MLlib будет выглядеть следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// We would prepare some earthquake tweet data and load it in LIBSVM format.val data = MLUtils.loadLibSVMFile(sc, "sample_earthquate_tweets.txt")// Split data into training (60%) and test (40%).val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)val training = splits(0).cache()val test = splits(1)// Run training algorithm to build the modelval numIterations = 100val model = SVMWithSGD.train(training, numIterations)// Clear the default threshold.model.clearThreshold()// Compute raw scores on the test set. val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label)}// Get evaluation metrics.val metrics = new BinaryClassificationMetrics(scoreAndLabels)val auROC = metrics.areaUnderROC()println("Area under ROC = " + auROC) |
Если мы довольны скоростью предсказания модели, мы можем перейти к следующему этапу и реагировать всякий раз, когда обнаруживаем землетрясение. Чтобы обнаружить его, нам нужно определенное количество (то есть, плотность) положительных твитов в определенном временном окне (как описано в статье). Обратите внимание, что для твитов с включенными службами определения местоположения в Твиттере мы также извлекли бы местоположение землетрясения. Вооружившись этими знаниями, мы могли бы использовать SparkSQL и запросить существующую таблицу Hive (хранящую пользователей, заинтересованных в получении уведомлений о землетрясениях), чтобы получить их адреса электронной почты и отправить им персональное предупреждение по электронной почте следующим образом:
|
1
2
3
4
5
|
// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)// sendEmail is a custom functionsqlContext.sql("FROM earthquake_warning_users SELECT firstName, lastName, city, email") .collect().foreach(sendEmail) |
Другие случаи использования Apache Spark
Потенциальные варианты использования Spark, конечно, выходят далеко за рамки обнаружения землетрясений.
Вот быстрая (но, конечно, далеко не исчерпывающая!) Выборка из других вариантов использования, которые требуют учета скорости, разнообразия и объема больших данных, для которых Spark так хорошо подходит:
В игровой индустрии обработка и обнаружение паттернов из потенциального источника событий в игре в реальном времени и возможность мгновенно реагировать на них — это возможность, которая может принести прибыльный бизнес в таких целях, как удержание игрока, целевая реклама, авто -регулировка уровня сложности и так далее.
В индустрии электронной коммерции информация о транзакциях в реальном времени может передаваться алгоритму потоковой кластеризации, например, k-means или совместной фильтрации, такой как ALS . Затем результаты можно даже объединить с другими неструктурированными источниками данных, такими как комментарии клиентов или обзоры продуктов, и использовать их для постоянного улучшения и адаптации рекомендаций с течением времени с учетом новых тенденций.
В сфере финансов или безопасности стек Spark может применяться к системе обнаружения мошенничества или вторжений или аутентификации на основе рисков. Он может достичь первоклассных результатов, собирая огромное количество архивных журналов, комбинируя его с внешними источниками данных, такими как информация о взломах данных и взломанных учетных записях (см., Например, https://haveibeenpwned.com/ ) и информация из соединения / запрос, такой как IP-геолокация или время.
Вывод
Подводя итог, можно сказать, что Spark помогает упростить сложную и требующую большого объема вычислений задачу обработки больших объемов данных в реальном времени или архивированных данных, как структурированных, так и неструктурированных, бесшовно интегрируя соответствующие сложные возможности, такие как машинное обучение и алгоритмы графов. Spark приносит обработку больших данных в массы. Проверьте это!
- Преобразования — это операции (такие как отображение, фильтрация, объединение, объединение и т. Д.), Которые выполняются на СДР и дают новый СДР, содержащий результат.
- Действия — это операции (такие как уменьшение, подсчет, сначала и т. Д.), Которые возвращают значение после выполнения вычисления в СДР.
| Ссылка: | Введение в Apache Spark с примерами и примерами использования от нашего партнера JCG Радека Островского в блоге Mapr . |