За последние несколько месяцев я написал пару постов об опасном долге истории транзакций InnoDB и о том, что MVCC может быть причиной серьезных проблем с производительностью MySQL . В этом посте я расскажу о смежной теме — режимах изоляции транзакций InnoDB, их взаимосвязи с MVCC (многоуровневым управлением параллелизмом) и их влиянии на производительность MySQL.
В руководстве по MySQL дается приличное описание режимов изоляции транзакций, поддерживаемых MySQL — я не буду здесь повторяться, а скорее остановлюсь на влиянии на производительность.
SERIALIZABLE — это самый сильный режим изоляции до того момента, когда он по существу побеждает Multi-Versioning, делая все блокировки SELECTs вызывающими значительные накладные расходы как с точки зрения управления блокировками (установка блокировок стоит дорого), так и с точки зрения параллелизма, который вы можете получить. Этот режим используется только в особых случаях в приложениях MySQL.
REPEATABLE READ — это уровень изоляции по умолчанию, и, как правило, он довольно приятный и удобный для приложения. Он видит все данные во время первого чтения (при условии использования стандартных неблокирующих операций чтения). Это, однако, требует больших затрат — InnoDB необходимо поддерживать историю транзакций до момента начала транзакции, что может быть очень дорогим. В худшем случае приложения с высоким уровнем обновлений и горячими строками — вы действительно не хотите, чтобы InnoDB имел дело со строками с сотнями тысяч версий.
С точки зрения влияния на производительность могут быть затронуты как чтение, так и запись. Для запросов на выбор, обход многострочных версий очень дорог, но также и для обновлений, тем более что контроль версий, по-видимому, вызывает серьезные проблемы конкуренции в MySQL 5.6.
Вот пример: я запустил sysbench для набора данных полностью в памяти, а когда запускал транзакцию и пару раз выполнял запрос на полное сканирование таблицы, оставляя транзакцию открытой:
sysbench --num-threads=64 --report-interval=10 --max-time=0 --max-requests=0 --rand-type=pareto --oltp-table-size=80000000 --mysql-user=root --mysql-password= --mysql-db=sbinnodb --test=/usr/share/doc/sysbench/tests/db/update_index.lua run
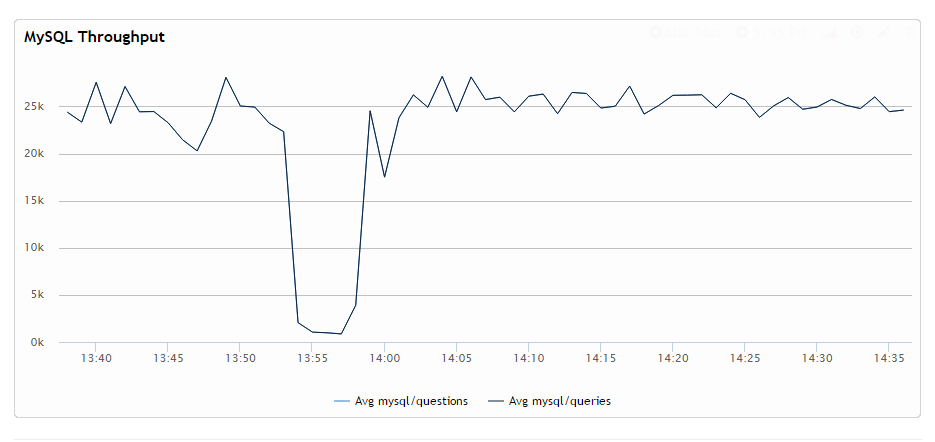
Как вы можете видеть, пропускная способность записи резко падает и остается низкой всегда, когда транзакция открыта, а не только во время выполнения запроса. Это, пожалуй, худший сценарий, который я мог бы найти, который происходит, когда вы выбираете вне транзакции, за которой следует длинная транзакция в режиме изоляции с повторяющимся чтением. Хотя вы можете увидеть регрессию и в других случаях.
Вот набор запросов, которые я использовал, если кто-то хочет повторить тест:
select avg(length(c)) from sbtest1; begin; select avg(length(c)) from sbtest1; select sleep(300); commit;
Repeatable Read не только уровень изоляции по умолчанию, он также используется для логического резервного копирования с InnoDB — думаю, mydumper или mysqldump –single-транзакция.
Эти результаты показывают, что такие методы резервного копирования нельзя использовать не только с большими наборами данных из-за длительного времени восстановления но также не может использоваться с некоторыми средами высокой записи из-за их влияния на производительность.
Режим READ COMMITTED аналогичен режиму REEATABLE READ, с существенным отличием в том, что версии хранятся не до начала первого чтения в транзакции, а до начала текущего оператора. Таким образом, использование этого режима позволяет InnoDB поддерживать намного меньше версий, особенно если у вас нет очень долго выполняющихся операторов . Если у вас есть какие-то долго выполняемые выборки, такие как отчеты о запросах, влияние на производительность может быть серьезным.
В целом, я думаю, что хорошей практикой является использование режима изоляции READ COMITTED по умолчанию и изменение на REEATABLE READ для тех приложений или транзакций, которые этого требуют.
ЧИТАЙТЕ БЕЗ КОММИТЕТЫ — я думаю, что это наименее понятный режим изоляции (не удивительно, так как в нем всего две строчки документации), который описывает его только с логической точки зрения. Если вы используете этот режим изоляции, вы увидите все изменения, сделанные в базе данных, по мере того, как они происходят, даже те, которые произошли в транзакциях, которые еще не были зафиксированы. Один хороший пример использования этого режима изоляции — это то, что вы можете «наблюдать», поскольку некоторые крупномасштабные операторы UPDATE происходят с грязными операциями чтения, показывающими, какие строки уже были изменены, а какие — нет.
Таким образом, это утверждение показывает изменения, которые еще не были зафиксированы и, возможно, никогда не будут зафиксированы, если транзакция, выполняющая их, сталкивается с некоторыми ошибками, поэтому этот режим следует использовать с особой осторожностью. Есть ряд случаев, когда нам не нужны 100% точные данные, и в этом случае этот режим становится очень удобным.
Так как же READ UNCOMMITTED ведет себя с точки зрения производительности? Теоретически InnoDB может очищать версии строк, даже если они были созданы после запуска оператора в режиме READ UNCOMMITTED. На практике, из-за ошибки или некоторых сложных деталей реализации, этого не происходит — версии строк по-прежнему будут сохраняться до начала оператора. Поэтому, если вы очень долго выполняете SELECT в инструкциях READ UNCOMMITTED, вы получите большое количество созданных версий строк, как если бы вы использовали READ COMMITTED. Здесь нет победы.
Со стороны SELECT есть важный выигрыш — режим чтения READ UNCOMMITTED означает, что InnoDB никогда не нужно идти и проверять более старые версии строк — последняя версия строки всегда является правильной, что может привести к значительному улучшению производительности, особенно если пространство отмены было перенесено на диск, поэтому поиск старых версий строк может вызвать много операций ввода-вывода.
Возможно, лучшая иллюстрация, которую я обнаружил с помощью запроса select avg (k) из sbtest1; работал параллельно с тем же обновлением тяжелой нагрузки, как указано выше. В режиме изоляции READ COMMITTED он никогда не завершается — я полагаю, потому что новые записи индекса вставляются быстрее, чем они сканируются, в случае режима изоляции READ UNCOMMITTED он завершается через минуту или около того.
Заключение: правильное использование режимов изоляции InnoDB может помочь вашему приложению добиться максимальной производительности. Ваш пробег может отличаться, и в некоторых случаях вы не увидите никакой разницы; в других это будет абсолютно драматично. Также, похоже, предстоит проделать большую работу в отношении производительности InnoDB с длинной историей версий. Я надеюсь, что это будет решено в будущей версии MySQL.