DuyHai Doan является евангелистом Apache Cassandra в DataStax. Он проводит время между техническими презентациями / встречами на Cassandra, программируя проекты с открытым исходным кодом для поддержки сообщества и помогая всем компаниям, использующим Cassandra, сделать свой проект успешным. Ранее он работал внештатным консультантом по Java / Cassandra.
В этом сообщении мы объясним причину, по которой все эксперты и евангелисты Cassandra продвигают операции с одним разделом . Мы подробно рассмотрим все преимущества, которые могут обеспечить операции с одним разделом с точки зрения работы , согласованности и стабильности системы .
Атомность и изоляция
Мутации ( INSERT / UPDATE / DELETE ) для всех столбцов раздела гарантированно будут атомарными, например, обновление N столбцов в одной строке рассматривается как одна операция записи.
Это свойство атомарности важно, потому что оно гарантирует клиентам, что либо все мутации применены, либо ни одна не применена .
Мутации с несколькими разделами не могут обеспечить атомарность прямо сейчас (по крайней мере, пока CASSANDRA-7056 « Операция RAMP » не будет выполнена). Атомарность на нескольких разделах потребует либо установки системы координации (например, глобальной блокировки), либо отправки дополнительных метаданных, как в транзакции RAMP.
Кроме того, мутации в одном разделе изолированы на реплике, например, пока клиент 1 не закончит запись мутаций, другой клиент 2 не сможет их прочитать. Несколько разделов не могут применяться изолированно по тем же причинам, что указаны выше.
партия
Мы, технические евангелисты, болтали о ЗАГРУЗЕННЫХ ДЕТАЛЯХ . Неправильное использование пакетов может привести к отказу узла и нанести ущерб стабильности системы.
Ниже описано, что происходит при отправке зарегистрированного пакета с мутациями в несколько разделов:
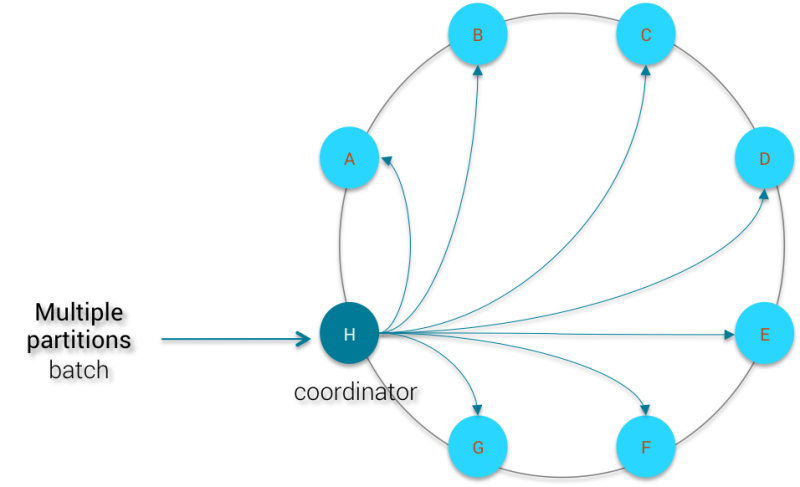
Многосекционная партия
Благодаря высокой распространяемости разделитель Murmur 3 будет равномерно распределять каждый раздел по всему кластеру. Следовательно, узел-координатор должен будет ждать N узлов ( N = количество различных ключей разделения в зарегистрированном пакете, чтобы упростить ) в кластере, чтобы подтвердить наличие мутаций, прежде чем удалять локально сохраненный зарегистрированный пакет. Зарегистрированная партия не может быть удалена из координатора, пока все N узлов не отправят обратно подтверждение. С кластером из 100 узлов эта записанная партия сильно повлияет на стабильность работы координатора.
Теперь давайте посмотрим, как координатор может справиться с одной записанной партией раздела :
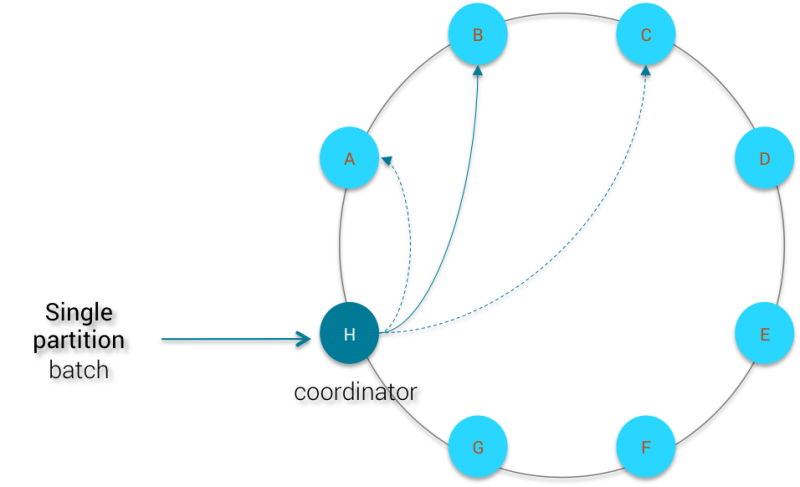
Пакет с одним разделом
Мутации отправляются всем узлам реплики, и координатор ожидает подтверждения RF (RF = коэффициент репликации), прежде чем удалить зарегистрированный пакет. В этом случае размер вашего кластера не имеет значения, поскольку число узлов, участвующих в пакете, привязано к коэффициенту репликации.
Вторичный индекс
Вторичный индекс в Cassandra — полезная функция, но ее очень трудно правильно использовать по двум основным причинам:
- вторичные индексы не очень хорошо масштабируются в зависимости от размера кластера. Действительно, индексы распределяются вместе с базовыми данными, поэтому для запроса с использованием этих индексов потребуется по меньшей мере N / RF- узлы в кластере, причем N — общее количество узлов в кластере Центр обработки данных и RF являются фактором репликации. Например, если у вас кластер из 100 узлов с RF = 3 , запрос со вторичным индексом, вероятно, достигнет 34 узлов (100/3, округленных до 34).
- очень высокая мощность и очень низкая мощность. Представьте, что у вас есть пользователь таблицы с колонкой пола . Первичный ключ таблицы — user_id . Вы хотите, чтобы можно было найти пользователя по полу, поэтому соблазнительно создать вторичный индекс для этого столбца. Однако, поскольку существует только 2 возможных значения для пола, на каждом узле все пользователи будут распределены только между двумя широкими разделами ( MALE & FEMALE ). Другой пример — создание вторичного индекса в электронной почте пользователя, чтобы иметь возможность их найти. по их электронной почте. Проблема в том, что для 1 пользователя существует не более 1 отдельного электронного письма (редко, когда 2 пользователя имеют один и тот же адрес электронной почты). Так что при выдаче запроса вроде:
1
SELECT*FROMusersWHEREemail='doanduyhai@nowhere.com';Кассандра будет нажимать на узлы N / RF, чтобы получить не более 1 строки, а иногда нет результата. Так что стоимость оплаты за поиск только 1 строки весьма запредельна
Единственный хороший и масштабируемый вариант использования вторичного индекса — это когда вы ограничиваете свой запрос одним разделом. Допустим, у нас есть следующая схема для хранения данных датчика:
|
01
02
03
04
05
06
07
08
09
10
|
CREATE TABLE sensors( sensor_id uuid, date timestamp, location text, value double, PRIMARY KEY(sensor_id, date)); CREATE INDEX location_idx ON sensors(location);CREATE INDEX value_idx ON sensors(value); |
Мы создали выше 2 индексов для датчиков для запроса по местоположению датчика и значению датчика. Следующие запросы будут производительными и масштабируемыми, потому что мы предоставляем каждый раз ключ раздела ( sensor_id ), чтобы Cassandra не обращалась к узлам N / RF и только искала данные из одного узла .
|
1
2
3
4
5
6
7
|
//Give all values of my sensor when it is in Los AngelestSELECT value FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014' AND location='Los Angeles'; //Give me the moment and the location of my sensor when it has value 4.5SELECT date,location FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014' AND value=4.5; |
LightWeight Транзакции
Транзакции LightWeight (LWT) были введены в Cassandra 2.0 для решения класса проблем, которые в противном случае потребовали бы внешнего менеджера блокировок.
Под капотом Cassandra внедряет протокол Paxos , чтобы гарантировать линеаризуемость мутаций. Это похоже на распределенную операцию сравнения и обмена.
С LWT вы можете имитировать ограничения целостности с помощью INSERT INTO… IF NOT EXISTS и DELETE… IF EXISTS . Очевидно, что эти 2 операции являются одним разделом.
Также возможно условное обновление с использованием транзакций LightWeight с синтаксисом UPDATE… SET col 1 = xxx WHERE partition_key = yyy IF col 2 = zzz; единственным ограничением является то, что проверяемый условный столбец должен принадлежать той же строке (такому же разделу), что и обновляемый столбец.
Аналогично, вы можете выполнить пакетный оператор, содержащий одну мутацию LWT, при условии, что все другие мутации используют тот же ключ раздела, что и ключ, использующий LWT . пример
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
CREATE TABLE stock_order ( order_id uuid, order_state static text, // OPEN or CLOSED item_id int, item_amount double, PRIMARY KEY (order_id, item_id)); // Batch insert new items into the given order and close it BEGIN LOGGED BATCH INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014', 5, 460000.0); INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014', 6, 50000); INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014', 7, 1200000); UPDATE stock_order SET order_state='CLOSED' WHERE order_id='de305d54-75b4-431b-adb2-eb6b9e546014' IF order_state='OPEN';END BATCH |
В приведенном выше примере, если данный ордер уже закрыт некоторыми другими процессами, условное обновление ( IF order_state = ‘OPEN’ ) завершится неудачно, поэтому вставка не будет выполнена. Это одна из замечательных особенностей LWT . Это дает вам надежную гарантию линеаризации для ваших операций.
Если вы будете распространять эти обновления заказов и мутации по разным разделам, LWT не будет применяться, и вы вернетесь в мир возможной согласованности.
Определяемые пользователем агрегаты
И последнее, но не менее важное: недавно выпущенная функция пользовательских определений (UDA) лучше всего работает на одном разделе. Не вдаваясь в технические детали, вы должны знать, что агрегатные функции в Cassandra применяются на узле- координаторе после логики согласования « последняя запись-выигрыш» .
Таким образом, выполнение агрегации на нескольких разделах или на всей таблице потребовало бы, чтобы координатор извлекал все данные (с использованием действительно внутренней подкачки страниц ) из разных узлов перед применением UDA . В этом случае задержка запроса агрегации связана с задержкой самого медленного узла. Кроме того, объединение нескольких разделов требует извлечения большего количества данных и, таким образом, может значительно увеличить продолжительность запроса.
По всем этим причинам текущая рекомендация состоит в том, чтобы зарезервировать UDA только для одного раздела и полагаться на Apache Spark, если вам нужно объединить всю таблицу или несколько разделов.
Для более подробной информации о UDA , вы можете прочитать эти сообщения в блоге:
- Кассандра UDF / UDA Техническое глубокое погружение
- Cassandra Определяемые пользователем агрегаты в действии
| Ссылка: | Важность операций с одним разделом в Cassandra от нашего партнера JCG DuyHai Doan в блоге Planet Cassandra . |