Недавно я начал использовать Liquibase в проекте для отслеживания изменений базы данных в нашем приложении Java Enterprise. Я должен сказать, что мне нравится, как это работает. Это делает развертывание моего приложения (или его нового выпуска) в другой среде более простым и (более) надежным. В прошлом мне приходилось предоставлять сценарий базы данных для администратора баз данных, который должен был выполняться сразу после или до того, как я повторно развернул свой файл EAR / WAR со всеми проблемами, которые идут с этой процедурой (сбой сценария / недоступность DBA и т. Д.). Сейчас я не буду говорить, что с этим решением не может быть проблем, но с точки зрения разработчика оно облегчает жизнь.
Вот как это работает для простого проекта Maven с некоторыми веб-сервисами, которые поддерживаются базой данных MySQL . Поскольку я развернул веб-службы в файле WAR на JBoss, я решил, что сценарии Liquibase запускаются экземпляром ServletContextListener . Чтобы иметь возможность протестировать скрипт базы данных без необходимости развертывания приложения, я также встроил плагин Maven для Liquibase в свой файл pom. Таким образом, я могу запускать сценарии liquibase вручную с Maven для моей локальной базы данных разработки.
Сначала добавьте необходимые зависимости в Maven pom.xml:
|
01
02
03
04
05
06
07
08
09
10
11
|
<dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>2.0.5</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.15</version> <scope>provided</scope> </dependency> |
Зависимость MySQL необходима только для возможности запуска сценариев Liquibase с Maven. Само приложение использует источник данных, который управляется контейнером, в данном случае JBoss. Чтобы иметь возможность запускать сценарии Liquibase с Maven, я определил плагин так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
<plugin> <groupId>org.liquibase</groupId> <artifactId>liquibase-maven-plugin</artifactId> <version>2.0.1</version> <configuration> <changeLogFile>db.changelogs/my-changelog-master.xml</changeLogFile> <driver>com.mysql.jdbc.Driver</driver> <url>jdbc:mysql://localhost:3306/MyDB</url> <username>admin-user</username> <password>*****</password> </configuration> <executions> <execution> <goals> <goal>update</goal> </goals> </execution> </executions> </plugin> |
Как я уже сказал, я выполняю сценарии, вызывая Liquibase с помощью Servlet Listener. Для этого добавьте следующие элементы в файл «web.xml» внутри файла WAR:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
... <context-param> <param-name>liquibase.changelog</param-name> <param-value>db.changelogs/db.changelog-master.xml</param-value> </context-param> <context-param> <param-name>liquibase.datasource</param-name> <param-value>java:jboss/datasources/LiquibaseDS</param-value> </context-param> <listener> <listener-class>liquibase.integration.servlet.LiquibaseServletListener</listener-class> </listener>... |
Здесь мы видим, что я определил два параметра:
- liquibase.changelog
Этот параметр относится к местоположению classpath главного файла db.changelogs. Важно отметить, что этот путь совпадает с тем, который используется в плагине Maven, если вы работаете с той же базой данных. Посмотрите эту проблему, с которой я столкнулся при использовании разных путей.
- liquibase.datasource
Это относится к JNDI-имени источника данных, который будет использоваться со сценарием Liquibase. Поскольку этому пользователю базы данных необходимы права на создание объектов базы данных, таких как таблицы, я предлагаю создать отдельный источник данных для использования с приложением. Этот источник данных должен затем соединиться с пользователем, который имеет права только на доступ к данным и не может создавать или удалять объекты.
Последняя часть — это создание файлов db.changelogs. Как рекомендуется здесь, в качестве лучшей практики я обращаюсь к «основному» файлу изменений в конфигурации. В этом главном файле журнала изменений я имею в виду отдельные сценарии. Например, у меня в папке «resources» есть следующий «главный» скрипт:
|
1
2
3
4
5
6
7
8
|
<?xml version="1.0" encoding="UTF-8"?><databaseChangeLog xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"> <include file="db.changelog-1.0.xml" relativeToChangelogFile="true" /> <include file="db.changelog-2.0.xml" relativeToChangelogFile="true" /></databaseChangeLog> |
В сценарии ‘db.changelog-1.0.xml’ я создаю несколько таблиц с набором изменений на основе XML:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
<?xml version="1.0" encoding="UTF-8"?><databaseChangeLog xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"> <changeSet id="1" author="pascalalma"> <createTable tableName="TEST_TABLE"> <column name="ID" type="bigint(20)" autoIncrement="true"> <constraints primaryKey="true" nullable="false"/> </column> <column name="CODE" type="varchar(20)"> <constraints nullable="false" unique="true"/> </column> <column name="DESCRIPTION" type="varchar(200)"/> <column name="VALUE" type="varchar(200)"/> </createTable> <addUniqueConstraint columnNames="CODE,DESCRIPTION" constraintName="CODE_UK" tableName="TEST_TABLE"/> <createTable tableName="ANOTHER_TEST_TABLE"> <column name="ID" type="bigint(20)" autoIncrement="true"> <constraints primaryKey="true" nullable="false"/> </column> <column name="CODE" type="varchar(20)"> <constraints nullable="false" unique="true"/> </column> <column name="TEST_CODE" type="bigint(20)"> </column> </createTable> <addForeignKeyConstraint baseColumnNames="TEST_CODE" baseTableName="ANOTHER_TEST_TABLE" constraintName="TEST_OTHER_FK" referencedColumnNames="CODE" referencedTableName="TEST_TABLE"/> </changeSet></databaseChangeLog> |
В этом примере сценария я показываю, как создавать таблицы с уникальными ограничениями на комбинации столбцов и как добавлять к ним внешние ключи.
В ‘db.changelog-2.0.xml’ я показываю, как загрузить данные в созданные таблицы, используя в качестве входных данных файл CSV:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
<?xml version="1.0" encoding="UTF-8"?><databaseChangeLog xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"> <changeSet id="2" author="pascalalma"> <loadData file="db.changelogs/mydata.csv" schemaName="MyDB" quotchar="'" tableName="TEST_TABLE"/> </changeSet></databaseChangeLog> |
В «mydata.csv» я определяю строки для загрузки в таблицу:
|
1
2
3
4
|
CODE,DESCRIPTION,VALUE'T01','Not specified','FOO''T02','Wrongly specified','BAR''T03','Correct','FOO-BAR' |
В первой строке CSV-файла указаны столбцы в порядке, в котором поля определены в других строках. Это очень удобный способ загрузки исходных данных в таблицы базы данных. Когда все это на месте, вы можете запустить Liquibase из Maven. Сначала соберите проект с помощью mvn clean install, а затем введите mvn liquibase: update:
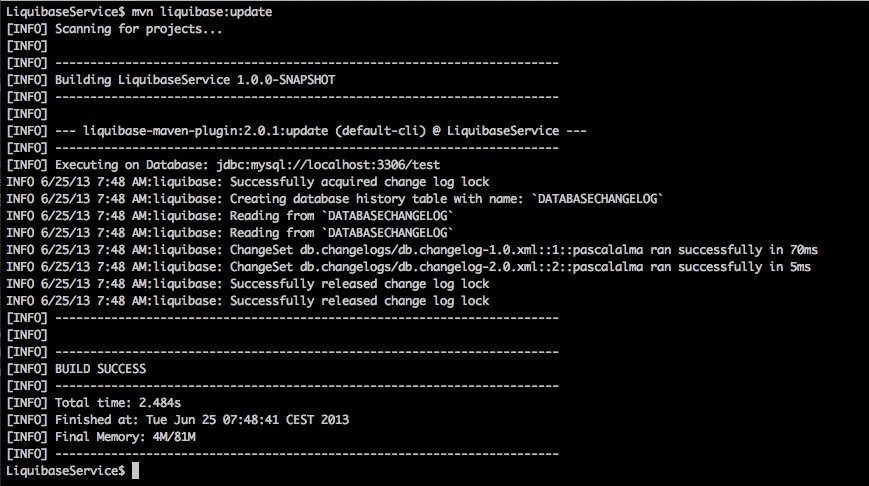
Теперь, если мы посмотрим на результат в схеме базы данных, мы увидим следующие таблицы:
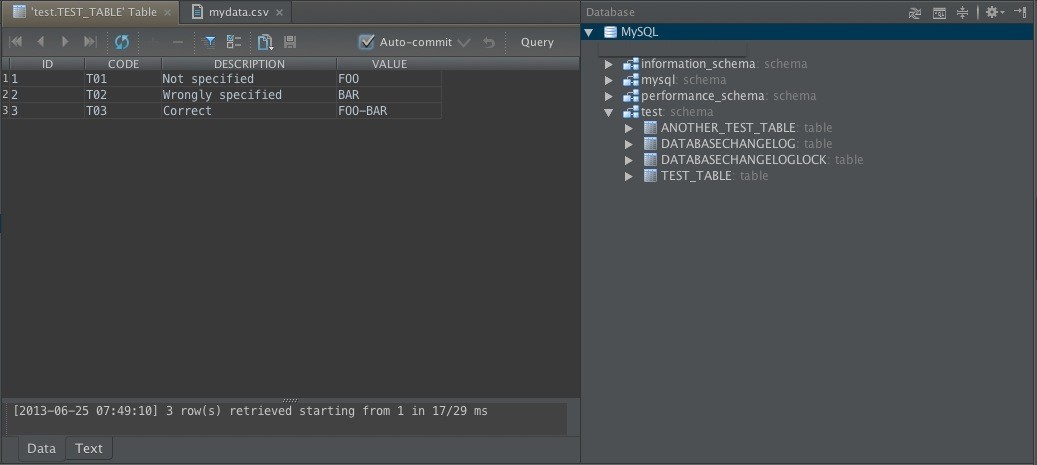
Мы видим, что наши таблицы с данными создаются. Мы также видим еще две таблицы: «DATABASECHANGELOG» и «DATABASECHANGELOGLOCK». Они используются Liquibase для определения состояния базы данных. Если я разверну файл WAR с источником данных в этой базе данных, Liquibase увидит, что сценарии уже запущены, и не выполнит их снова. Однако, если я удалю таблицы, сценарии будут выполнены так же, как и для новой базы данных. Как видите, это может упростить развертывание новых выпусков вашего программного обеспечения, по крайней мере, части базы данных.