PySpark — это Spark API, который позволяет вам взаимодействовать с Spark через оболочку Python. Если у вас есть опыт программирования на Python, это отличный способ познакомиться с типами данных Spark и параллельным программированием. PySpark является особенно гибким инструментом для исследовательского анализа больших данных, поскольку он интегрируется с остальной частью экосистемы анализа данных Python, включая панды (DataFrames), NumPy (массивы) и Matplotlib (визуализация). В этом сообщении вы получите практический опыт использования PySpark и MapR Sandbox.
Пример: использование кластеризации данных кибер-сети для выявления аномального поведения
Обучение без учителя является областью анализа данных, которая является исследовательской. Эти методы используются для изучения структуры и поведения данных. Имейте в виду, что эти методы используются не для прогнозирования или классификации, а для интерпретации и понимания.
Кластеризация — это популярный метод обучения без контроля, в котором алгоритм пытается идентифицировать естественные группы в данных. K-means — наиболее широко используемый алгоритм кластеризации, где «k» — это количество групп, в которые попадают данные. В k-средних, k назначается аналитиком, и выбор значения k — это то, где интерпретация данных вступает в игру.
В этом примере мы будем использовать набор данных из ежегодного конкурса интеллектуального анализа данных The KDD Cup ( http://www.sigkdd.org/kddcup/index.php ). Один год (1999) тема была о вторжении в сеть, и набор данных все еще доступен ( http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html ). Набор данных будет файл kddcup.data.gz и состоит из 42 объектов и приблизительно 4,9 миллиона строк.
Использование кластеризации данных кибер-сети для выявления аномального поведения является распространенным применением обучения без присмотра. Огромное количество собранных данных делает невозможным просмотр каждого журнала или события, чтобы правильно определить, было ли это сетевое событие нормальным или аномальным. Системы обнаружения вторжений (IDS) и Системы предотвращения вторжений (IPS) часто являются единственными сетями приложений, которые должны фильтровать эти данные, и фильтр часто назначается на основе аномальных сигнатур, для обновления которых может потребоваться время. Перед обновлением важно иметь методы анализа для проверки данных вашей сети на предмет недавних аномальных действий.
K-means также используется при анализе данных социальных сетей, финансовых транзакций и демографии. Например, вы можете использовать кластерный анализ, чтобы идентифицировать группы пользователей Twitter, которые пишут в Твиттере из определенных географических регионов, используя их оценки широты, долготы и настроения.
Код для вычисления k-средних в Spark с использованием Scala можно найти во многих книгах и блогах. Реализация этого кода в PySpark использует немного другой синтаксис, но многие элементы одинаковы, поэтому он будет выглядеть знакомо. MapR Sandbox предлагает отличную среду, в которой Spark уже предустановлен, и позволяет вам получить право на анализ и не беспокоиться об установке программного обеспечения.
Установите Песочницу
Инструкции в этом примере будут использовать Песочницу в Виртуальном Ящике, но можно использовать VMware или Виртуальный Ящик. Для получения инструкций по установке Песочницы в Виртуальном Ящике, нажмите на эту ссылку.
http://maprdocs.mapr.com/51/#SandboxHadoop/t_install_sandbox_vbox.html
Запустите песочницу на вашей виртуальной машине
Для начала запустите установленную песочницу MapR с помощью VMware или Virtual Box. Это может занять минуту или две, чтобы полностью начать.
ПРИМЕЧАНИЕ: вам нужно нажать клавишу «команда» в MacOS или правую клавишу «управление» в Windows, чтобы вывести курсор мыши из окна консоли.
Как только песочница запустится, посмотрите, что из этого выйдет. Сама песочница — это среда, в которой вы можете взаимодействовать со своими данными, но если вы зайдете на http://127.0.0.1:8443/, вы сможете получить доступ к файловой системе и ознакомиться с тем, как хранятся данные.
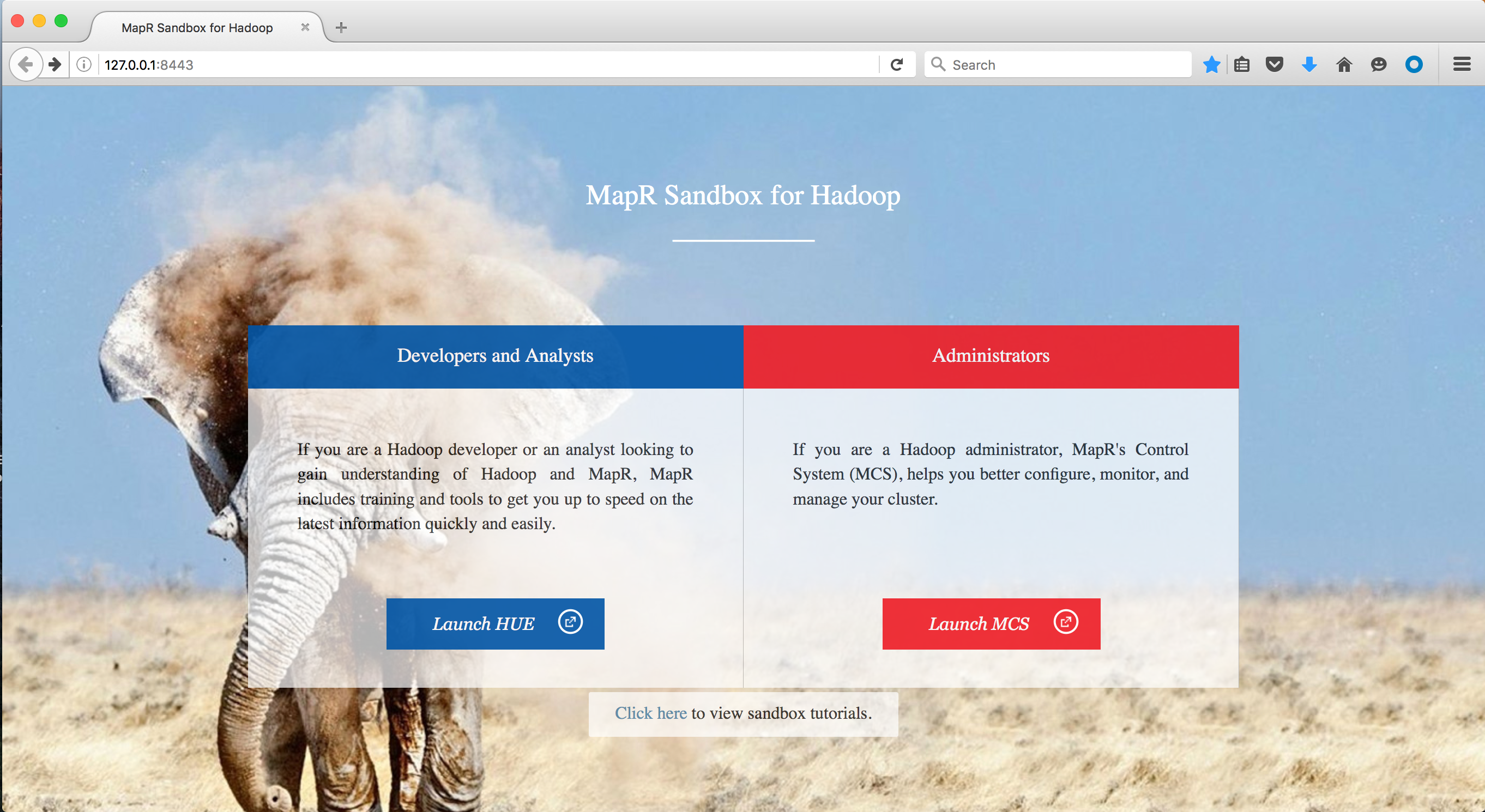
Для этого урока мы будем в HUE. Запустите HUE и введите комбинацию имени пользователя и пароля:
|
1
2
|
Username: maprPassword: mapr |
Когда HUE откроется, перейдите в браузер файлов:
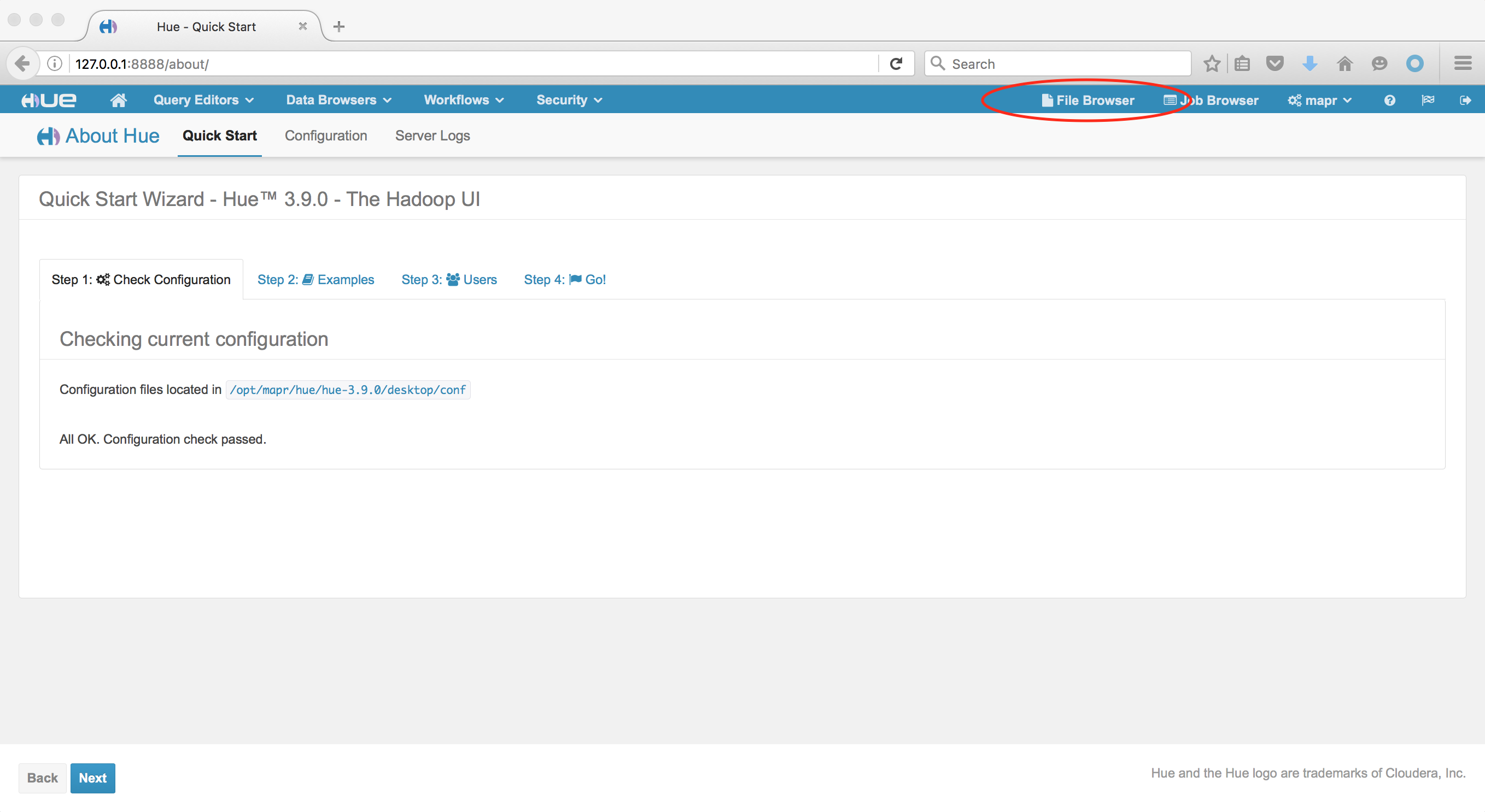
Когда вы находитесь в браузере файлов, вы увидите, что находитесь в каталоге / user / mapr .
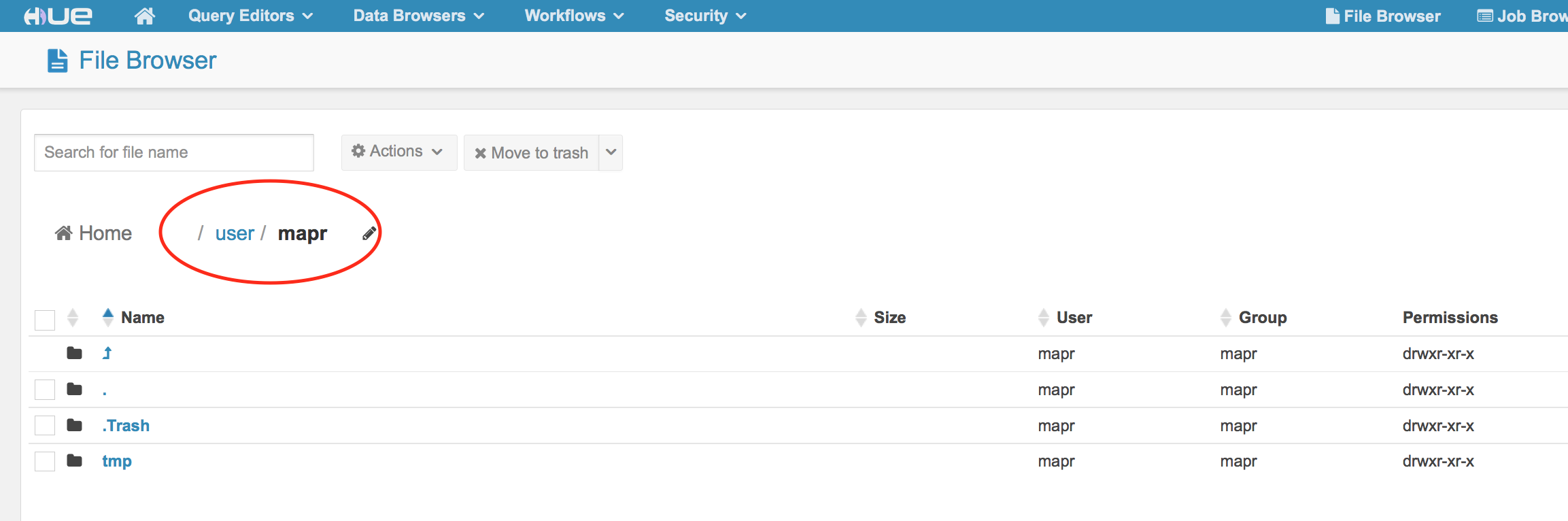
Мы будем действовать как user01. Чтобы попасть в этот каталог, нажмите на каталог / user
Убедитесь, что вы видите user01.
Теперь у нас есть доступ к user01 в нашей песочнице. Здесь вы можете создавать папки и хранить данные, которые будут использоваться для проверки кода Spark. При работе с самой песочницей вы можете использовать командную строку песочницы, если хотите, или можете подключиться через терминал или PuTTY на вашем компьютере как «user01». Если вы решите подключиться через терминал, используйте ssh и следующую команду: $ ssh user01@localhost -p 2222 Пароль: mapr
|
1
2
|
Welcome to your Mapr Demo Virtual machine.[user01@maprdemo ~]$ |
Для этого урока я использую ноутбук Mac и терминальное приложение под названием iTerm2. Я также мог бы использовать мой обычный терминал по умолчанию на моем Mac.
Песочница поставляется с установленной Spark. Python также установлен в Песочнице, и версия Python — 2.6.6.
|
1
2
|
[user01@maprdemo ~]$ python --versionPython 2.6.6 |
PySpark использует Python и Spark; Тем не менее, есть некоторые дополнительные пакеты, необходимые. Чтобы установить эти дополнительные пакеты, нам нужно стать пользователем root для песочницы. (пароль: mapr)
|
1
2
3
4
5
6
|
[user01@maprdemo ~]$ su -Password:[root@maprdemo ~]# [root@maprdemo ~]# yum -y install python-pip[root@maprdemo ~]# pip install nose[root@maprdemo ~]# pip install numpy |
Установка numpy может занять минуту или две. NumPy и Nose — это пакеты, которые позволяют манипулировать массивами и выполнять модульные тесты в Python.
|
1
2
|
[root@maprdemo ~]# su - user01[user01@maprdemo ~]$ |
PySpark в Песочнице
Чтобы запустить PySpark, введите следующее:
[user01@maprdemo ~]$ pyspark --master yarn-client
Ниже приведен скриншот того, как примерно будет выглядеть ваш вывод. Вы будете в Spark, но с оболочкой Python.
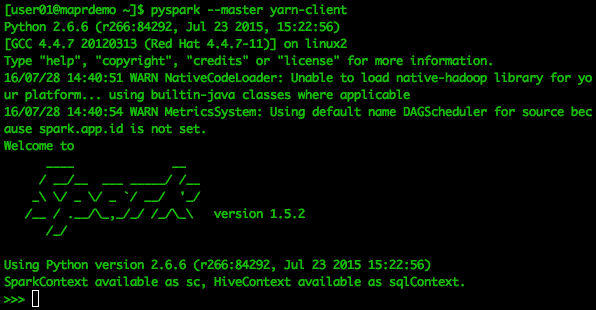
Следующий код будет выполнен в PySpark по приглашению >>>.
Скопируйте и вставьте следующее, чтобы загрузить пакеты зависимостей для этого упражнения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
from collections import OrderedDictfrom numpy import arrayfrom math import sqrtimport sysimport osimport numpyimport urllibimport pysparkfrom pyspark import SparkContextfrom pyspark.mllib.feature import StandardScalerfrom pyspark.mllib.clustering import Kmeans, KmeansModelfrom pyspark.mllib.linalg import DenseVectorfrom pyspark.mllib.linalg import SparseVectorfrom collections import OrderedDictfrom time import time |
Далее мы проверим наш рабочий каталог, поместим в него данные и проверим, есть ли он там.
Проверьте каталог:
|
1
2
3
4
|
os getcwd()>>>> os.getcwd()'/user/user01' |
Получить данные
|
1
|
f = urllib.urlretrieve ("http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data.gz", "kddcup.data.gz") |
Проверьте, чтобы увидеть данные в текущем рабочем каталоге
os.listdir('/user/user01')
Теперь вы должны увидеть kddcup.data.gz в каталоге «user01». Вы также можете проверить в HUE.
Импорт и исследование данных
PySpark может импортировать сжатые файлы непосредственно в RDD.
|
1
2
3
|
data_file = "./kddcup.data.gz"kddcup_data = sc.textFile(data_file)kddcup_data.count() |
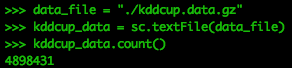
Глядя на первые 5 записей RDD
kddcup_data.take(5)

Этот вывод трудно читать. Это потому, что мы просим PySpark показать нам данные в формате RDD. PySpark имеет функциональность DataFrame. Если версия Python 2.7 или выше, вы можете использовать пакет pandas. Однако pandas не работает на Python версий 2.6, поэтому мы используем функциональность Spark SQL для создания DataFrames для исследования.
|
1
2
3
4
5
6
7
|
from pyspark.sql.types import *from pyspark.sql import DataFramefrom pyspark.sql import SQLContextfrom pyspark.sql import Rowkdd = kddcup_data.map(lambda l: l.split(","))df = sqlContext.createDataFrame(kdd)df.show(5) |

Теперь мы можем видеть структуру данных немного лучше. Для данных нет заголовков столбцов, так как они не были включены в загруженный нами файл. Они находятся в отдельном файле и могут быть добавлены к данным. В этом упражнении нет необходимости, поскольку нас больше интересуют группы данных, а не сами функции.
Эти данные уже помечены, что означает, что типы вредоносного кибер-поведения были назначены на строку. Эта метка является последней функцией, _42, на снимке экрана выше. Первые пять строк набора данных помечены как «нормальные». Однако мы должны определить количество меток для всего набора данных.
Теперь давайте разберемся с различными типами меток в этих данных и общим количеством для каждой метки. Давайте посмотрим, сколько времени это займет.
|
1
2
3
4
|
labels = kddcup_data.map(lambda line: line.strip().split(",")[-1])start_label_count = time()label_counts = labels.countByValue()label_count_time = time()-start_label_count |
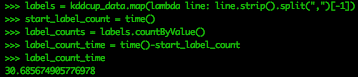
|
1
2
3
|
sorted_labels = OrderedDict(sorted(label_counts.items(), key=lambda t: t[1], reverse=True)) for label, count in sorted_labels.items(): #simple for loop print label, count |
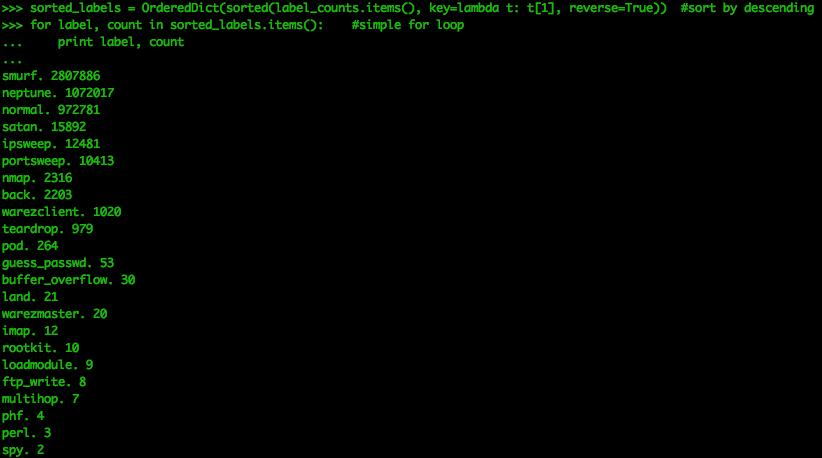
Мы видим, что есть 23 различных ярлыка. Smurf-атаки известны как направленные широковещательные атаки и являются популярной формой DoS-пакетов. Этот набор данных показывает, что «нормальные» события являются третьим наиболее распространенным типом событий. Хотя это хорошо для изучения материала, этот набор данных не следует принимать за реальный сетевой журнал. В реальном наборе сетевых данных меток не будет, и нормальный трафик будет намного больше, чем любой аномальный трафик. Это приводит к несбалансированности данных, что значительно усложняет идентификацию злоумышленников.
Теперь мы можем начать подготовку данных для нашего алгоритма кластеризации.
Очистка данных
K-means использует только числовые значения. Этот набор данных содержит три категориальные функции (не включая функцию типа атаки). Для целей этого упражнения они будут удалены из набора данных. Однако выполнение некоторых преобразований признаков, когда этим категориальным назначениям присваиваются свои собственные свойства, и им назначаются двоичные значения 1 или 0 в зависимости от того, являются ли они «tcp» или нет, может быть выполнено.
Во-первых, мы должны проанализировать данные, разбив исходную СДР kddcup_data на столбцы и удалив три категориальные переменные, начиная с индекса 1 и удалив последний столбец. Оставшиеся столбцы затем преобразуются в массив числовых значений, а затем присоединяются к последнему столбцу метки, чтобы сформировать числовой массив и строку в кортеже.
|
1
2
3
4
5
6
7
|
def parse_interaction(line): line_split = line.split(",") clean_line_split = [line_split[0]]+line_split[4:-1] return (line_split[-1], array([float(x) for x in clean_line_split]))parsed_data = kddcup_data.map(parse_interaction)pd_values = parsed_data.values().cache() |
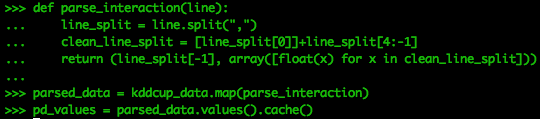
Мы помещаем значения из парсера в кеш для легкого вызова.
Песочнице не хватает памяти для обработки всего набора данных для нашего урока, поэтому мы возьмем образец данных.
|
1
2
|
kdd_sample = pd_values.sample(False, .10, 123) kdd_sample.count() |

Мы взяли 10% данных. Функция sample () принимает значения без замены (false), 10% от общего объема данных, и использует возможность 123 set.seed для повторения этого образца.
Далее нам нужно стандартизировать наши данные. StandardScaler стандартизирует функции путем масштабирования до дисперсии единиц и установки среднего значения на ноль с использованием сводной статистики столбцов для выборок в обучающем наборе. Стандартизация может улучшить скорость сходимости в процессе оптимизации, а также предотвратить появление признаков с очень большими отклонениями, оказывающих влияние во время обучения модели.
standardizer = StandardScaler(True, True)
Рассчитать итоговую статистику с помощью StandardScaler
standardizer_model = standardizer.fit(kdd_sample)
Нормализуйте каждую функцию, чтобы иметь единичное стандартное отклонение.
data_for_cluster = standardizer_model.transform(kdd_sample)

Кластеризация данных
Чем отличается k-means в scikit-learn в Python от Spark? Реализация MLlib Pyspark включает распараллеленный вариант метода k-means ++ (который используется по умолчанию для реализации Scikit-Learn), который называется k-means || который является параллельной версией k-средних. В сборнике по анализу данных Scala (Packt Publishing 2015) Арун Маниваннан объясняет, как они различаются:
K-средства ++
Вместо случайного выбора всех центроидов алгоритм k-means ++ выполняет следующие действия:
- Он выбирает первый центроид случайно (равномерно)
- Он вычисляет квадрат расстояния каждой из остальных точек от текущего центроида
- Вероятность прикрепляется к каждой из этих точек в зависимости от того, как далеко они находятся. Чем дальше кандидат от центроида, тем выше его вероятность.
- Мы выбираем второй центроид из распределения, которое мы имеем на шаге 3. На i-й итерации у нас есть кластеры 1 + i . Найдите новый центроид, пройдя по всему набору данных и сформировав распределение из этих точек в зависимости от того, как далеко они находятся от всех предварительно вычисленных центроидов. Эти шаги повторяются в течение k-1 итераций до тех пор, пока не будет выбрано k центроидов. K-means ++ известен тем, что значительно повышает качество центроидов. Однако, как мы видим, для выбора начального набора центроидов алгоритм проходит через весь набор данных k раз. К сожалению, с большим набором данных это становится проблемой.
K-средства ||
При параллельном k-среднем (K-означает ||) для каждой итерации вместо выбора отдельной точки после вычисления распределения вероятностей каждой из точек в наборе данных выбирается намного больше точек. В случае Spark количество выборок, выбранных на шаг, составляет 2 * k. Как только эти исходные кандидаты-центроиды выбраны, k-means ++ запускается для этих точек данных (вместо того, чтобы проходить через весь набор данных).
В этом примере мы будем использовать k-means ++, потому что мы все еще в песочнице, а не в кластере. Вы увидите это в нашей инициализации в коде, где написано:
initializationMode="random"
Если мы хотим сделать k-means параллельным:
initializationMode="k-means||"
Обратитесь к документации MLlib для получения дополнительной информации. ( http://spark.apache.org/docs/1.6.2/api/python/pyspark.mllib.html#pyspark.mllib.clustering.KMeans )
При выполнении k-средних аналитик выбирает значение k. Однако вместо того, чтобы каждый раз запускать алгоритм для k, мы можем упаковать его в цикл, который проходит через массив значений для k. Для этого упражнения мы просто делаем три значения k. Мы также создадим пустой список с именем metrics, в котором будут храниться результаты нашего цикла.
|
1
2
|
k_values = numpy.arange(10,31,10)metrics = [] |
Одним из способов оценки выбора k является определение суммы внутри квадратов ошибок (WSSSE). Мы ищем значение k, которое минимизирует WSSSE.
def error(point): center = clusters.centers[clusters.predict(point)] denseCenter = DenseVector(numpy.ndarray.tolist(center)) return sqrt(sum([x**2 for x in (DenseVector(point.toArray()) - denseCenter)]))
Запустите следующее в своей песочнице. Обработка может занять некоторое время, поэтому мы используем только три значения k.
|
1
2
3
4
5
6
7
|
for k in k_values: clusters = Kmeans.train(data_for_cluster, k, maxIterations=4, runs=5, initializationMode="random") WSSSE = data_for_cluster.map(lambda point: error(point)).reduce(lambda x, y: x + y) results = (k,WSSSE) metrics.append(results)metrics |
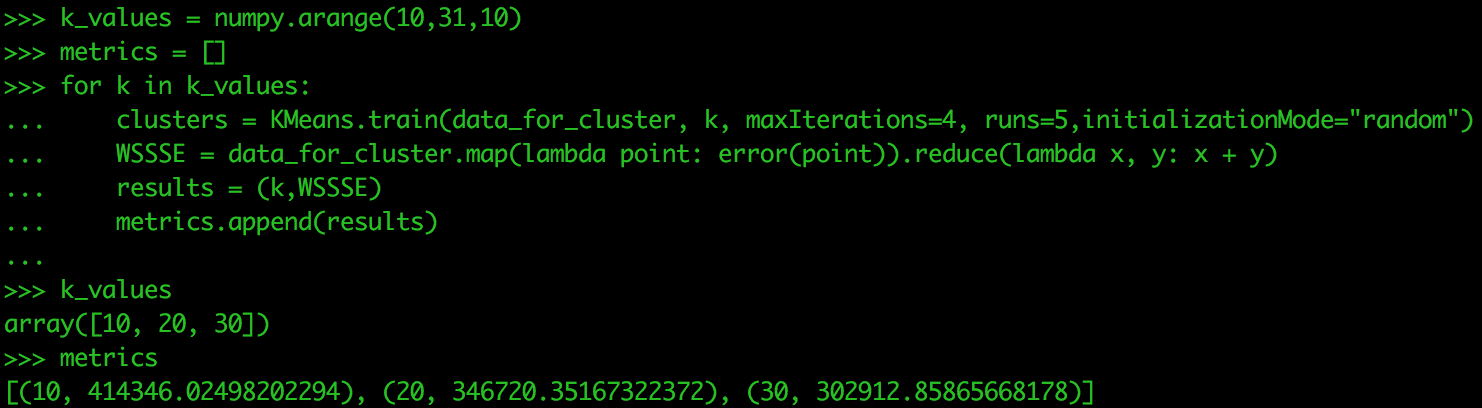
В этом случае 30 является лучшим значением для k. Давайте проверим назначения кластеров для каждой точки данных, когда у нас есть 30 кластеров. Следующим тестом будет запуск для значений k 30, 35, 40. Три значения k — это не самое большее, что вы тестируете за один прогон, но используются только для этого урока.
|
1
2
3
4
|
k30 = Kmeans.train(data_for_cluster, 30, maxIterations=4, runs=5, initializationMode="random")cluster_membership = data_for_cluster.map(lambda x: k30.predict(x))cluster_idx = cluster_membership.zipWithIndex()cluster_idx.take(20) |

Ваши результаты могут быть немного другими. Это связано со случайным расположением центроидов, когда мы впервые начинаем алгоритм кластеризации. Выполнение этого много раз позволяет вам увидеть, как точки в ваших данных изменяют свое значение k или остаются неизменными.
Я надеюсь, что вы смогли получить практический опыт использования PySpark и MapR Sandbox. Это отличная среда для тестирования вашего кода и настройки на эффективность. Кроме того, понимание того, как будет масштабироваться ваш алгоритм, является важной частью знаний при переходе от использования PySpark на локальной машине к кластеру. В платформу MapR встроен Spark, что облегчает разработку и миграцию кода в приложение. MapR также поддерживает потоковые k-средства в Spark, в отличие от пакетных k-средних, которые мы выполняем в этом руководстве.
| Ссылка: | Учебное пособие: Использование PySpark и MapR Sandbox от нашего партнера по JCG Джастина Бранденбурга в блоге Mapr . |