По большей части я ненавижу конкурентные тесты. Продавец, который их публикует, всегда, кажется, выходит на первое место. Числа всегда удивительны, но как только вы начинаете копать немного, вы начинаете видеть ошибки в том, что на самом деле измеряется, и это никогда не относится к реальным рабочим нагрузкам. Например, у вас есть Cassandra, требующая 1 миллион записей в секунду на 300 серверах. Затем Aerospike требует 1 миллион записей в секунду на 50 серверах. MongoDB утверждает, что почти 32 000 операций записи в секунду на одном сервере, но утверждает, что Cassandra может выполнять только 6 Кбит / с, а Couch может работать только на 1,2 кВт / с на одной подаче. Тогда ScyllaDB имеет почти 2 миллиона записей в секунду на 3 серверах, поражающих всех.
Майкл Хангер написал тест, в котором Neo4j может записывать более 1 миллиона записей в секунду на одном сервере с использованием Cypher. Но мы не публикуем тесты производительности, которые не отражают реальных нагрузок на графики. На самом деле, довольно сложно разработать реальные тесты, которые не влияют ни на одну компанию или технологию. Усилия в этом направлении предпринимаются Советом по сравнительным оценкам связанных данных . Иди посмотри на их работу. Также помните, что никому не нужны миллионы записей в секунду в оперативном хранилище данных. Этот объем данных лучше всего отправлять в ваш кластер больших данных для аналитики и отчетности.
Недавно ArangoDB опубликовал серию тестов, показывающих, насколько крут ArangoDB и как много других отстой. OrientDB оспорил эти тесты с новыми результатами, показывающими, насколько хорош OrientDB в кешировании результатов .
Контрольный набор данных составляет 2 миллиона узлов и 30 миллионов отношений. При таком размере вы можете поставить его на SQLite и жить долго и счастливо, так что это не очень реалистично. В любом случае, давайте посмотрим на некоторые результаты и начнем с кратчайшего пути.
INFO Neo4J: shortest path, 40 items
INFO Total Time for 40 requests: 400 ms
Хм… 400 мс, чтобы выполнить 40 запросов для Neo4j против 60 мс для ArangoDB. Не выглядит слишком хорошо. Интересно, что случится, если я запустлю это снова?
INFO Neo4J: shortest path, 40 items
INFO Total Time for 40 requests: 77 ms
Вау … это упало с 400мс до 77мс. Что происходит? В соответствии с их методологией тестирования, они в среднем 5 прогонов, каждый раз перезагружая сервер (потому что это именно то, что вы будете делать в производственной среде). Что делает Neo4j в первый раз против второго запуска теста? Давайте начнем с рассмотрения запроса:
MATCH (s:PROFILES {_key:'P10000'}),(t:PROFILES {_key:'P10001'}),
p = shortestPath((s)-[*..15]->(t))
RETURN [x in nodes(p) | x._key] as pathЭтот запрос Cypher необходимо преобразовать в код … это происходит в следующие шаги :
- Преобразовать строку входного запроса в абстрактное синтаксическое дерево (AST)
- Оптимизировать и нормализовать АСТ
- Создать график запроса из нормализованного AST
- Создайте логический план из X
- Перепишите логический план
- Создать план выполнения из логического плана
- Выполнить запрос, используя план выполнения
Для тех из вас, кто более нагляден:
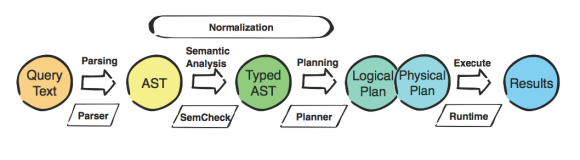
Давайте поместим «PROFILE» перед этим запросом и посмотрим, что на самом деле делает Neo4j:

Этот план выполнения становится кодом Scala, который интерпретируется и запускается. Существует новая скомпилированная среда выполнения , которая превратит этот план выполнения в байт-код Java, но пока не знает, как обрабатывать этот тип запроса. Код для этого запроса кэшируется, поэтому в следующий раз, когда Neo4j увидит тот же запрос (даже с другими параметрами), он просто запустит его, а не выяснит его снова. Это основная причина того, что во второй раз мы запускаем этот тест намного быстрее. Однако есть и другая причина:
ArangoDB написан на C ++, поэтому он не связан с разогревом JVM. Виктор Граци объясняет:
Хорошо известной особенностью платформы Java является то, что по мере запуска и выполнения приложения Java JVM компилирует приложение в исполняемый машинный код. Поскольку приложение продолжает работать, JVM будет оценивать историю выполнения приложения и перекомпилировать важные части кода приложения для повышения производительности. Следовательно, производительность приложения со временем улучшится.
В производственной среде это не проблема, поскольку базы данных постоянно видят одни и те же запросы, и этот код оптимизируется. Эти тесты, однако, не делают этого.
Итак, каково правильное значение 400 мс или 77 мс … Я оставлю это на ваше усмотрение. Теперь, этот пост в блоге называется «Тесты и нагнетатели», и я вообще не говорил о нагнетателях, что дает. Ну, единственное, что я очень люблю, люблю и люблю в Neo4j — это то, что это Hot Rod .

Я имею в виду, что это полностью настраиваемый. Вы можете добавить расширения API , плагины , расширения ядра , ваши собственные функции Cypher , ваше собственное модифицированное ядро , его полностью встраиваемое , и все, что вам нужно .
Итак, давайте добавим расширение SuperCharger « Guacamole » в Neo4j, чтобы справиться с некоторыми из этих работ. Я скомпилировал файл jar, добавил его в каталог плагинов, настроил его и перезапустил сервер. Теперь я изменил тесты javascript и добавил Neo4jExt, чтобы я мог выполнить эту команду:
nodejs benchmark neo4jext -a 10.240.0.2 -t shortestТеперь вместо 400 мс я получаю:
INFO Neo4JExt: shortest path, 40 items
INFO Total Time for 40 requests: 120 ms
Второй раз:
INFO Neo4JExt: shortest path, 40 items
INFO Total Time for 40 requests: 61 ms
Та же скорость, что и у ArangoDB. Что если я запустлю его еще несколько раз …
INFO Neo4JExt: shortest path, 40 items
INFO Total Time for 40 requests: 55 ms
Хорошо … теперь Neo4j на 10% быстрее, чем ArangoDB.
Давайте посмотрим на запрос Соседи и что ArangoDB думает по этому вопросу:
Выглядит как случай для графовых баз данных, но это не обязательно. По крайней мере, Neo4j и OrientDB не могут выделиться в этом тесте — несмотря на то, что это простой обход графика. ArangoDB работает очень быстро, используя AVG всего 464 мс, нет никакой базы данных графиков. Это потому, что поиск в графе известной длины быстрее при поиске по индексу, чем при использовании исходящих ссылок в каждой вершине.
Ах … вот оно! В этом наборе данных всего 1,6 миллиона пользователей и около 30 миллионов отношений, поиск индекса выполняется быстрее, чем обход. Что происходит, когда вы получаете 10 миллионов пользователей? 100 миллионов пользователей или даже 1 миллиард пользователей, и у вас есть 20 миллиардов отношений для поиска в индексе. О, это правильно. Обход СЕЙЧАС намного быстрее, чем поиск по индексу . В-дерево поиск Индекс O (журнал N). Это означает, что когда ваши данные растут в 10 раз, ваша скорость замедляется на n для каждого соединения (10 = 1x, 100 = 2x, 1000 = 3x и т. Д.). Таким образом, по мере того, как ваши данные растут, индекс становится все толще и толще, он начинает замедляться, и однажды не имеет значения, сколько денег вы потратите на Oracle RAC, он просто не сможет с этим справиться.
Реляционные базы данных не могут масштабировать объединения. Это и есть причина, по которой началось движение NoSQL. У магазинов Key Value их нет. Базы данных документов реплицируют данные, объединяя целые объекты, поэтому вам не нужно объединяться. Столбец Хранит реплицированные данные для каждого запроса, поэтому вам не нужно присоединяться. Вот почему у вас есть 300 кластеров серверов этих типов баз данных, в то время как кластеры Neo4j обычно находятся в диапазоне 3-7 серверов. Neo4j не должен дублировать данные и не имеет индексов монстров для работы.
Мне удалось снизить «Соседи2» с 2,3 до 1,7 с, а агрегацию с 2,8 до 1,3 с. В случае агрегации я использую непубличный API (непослушный я), но я еще не дошел до его распараллеливания. Да, верно, вы можете сделать ваши запросы параллельными, если хотите (см. В этом репозитории пример параллельного постраничного поиска ). На самом деле я еще не пробовал, но также можно распределить особенно тяжелый запрос по кластеру. Представьте, что вы начинаете с пользователя, заводите его друзей, а затем, чтобы каждый из них отправлял конкретные запросы друзьям себе и остальной части кластера, а затем собирал их все вместе.
Еще одна вещь, которую я не сделал, это встроил Neo4j в высокоскоростной веб-сервер, такой как Undertow, чтобы сократить некоторые мои http-издержки или переключиться на интерфейс на основе сокетов, чтобы вообще его пропустить. Я также мог бы обмануть и добавить свой собственный « Кэш команд », используя Google Guava .
С Neo4j это всегда прекрасный день для настройки вашей базы данных! Так что катаюсь вечно блестящий и хромированный !