Вступление
Как все мы знаем, разработчики предпочитают Index Seek в случае выполнения запроса, и мы все знаем, что такое Index Seek и как он повышает производительность. В этой статье мы не будем обсуждать поиск по индексу.
Сканирование таблицы выполняется на таблице, на которой нет индекса (кучи) — он просматривает строки в таблице, а сканирование индекса выполняется на индексированной таблице — самом индексе.
Здесь мы пытаемся обсудить определенный сценарий, связанный со сканированием таблиц и индексами.
Описание сценария
Предположим, у нас есть табличный объект без индекса. Имя табличного объекта — tbl_WithoutIndex, а другой табличный объект — tbl_WuthIndex.
-- Heap Table Defination IF OBJECT_ID(N'dbo.tbl_WithoutIndex', N'U') IS NOT NULL BEGIN DROP TABLE [dbo].[tbl_WithoutIndex]; END GO CREATE TABLE [dbo].[tbl_WithoutIndex] ( EMPID INT NOT NULL, EMPNAME VARCHAR(50) NOT NULL ); GO -- Insert Some Records INSERT INTO [dbo].[tbl_WithoutIndex] (EMPID, EMPNAME) VALUES (101, 'Joydeep Das'), (102, 'Sukamal Jana'), (103, 'Ranajit Shinah'); GO -- Table with Index (Clustered Index for primary Key) IF OBJECT_ID(N'dbo.tbl_WithIndex', N'U') IS NOT NULL BEGIN DROP TABLE [dbo].[tbl_WithIndex]; END GO CREATE TABLE [dbo].[tbl_WithIndex] ( EMPID INT NOT NULL PRIMARY KEY, EMPNAME VARCHAR(50) NOT NULL ); GO -- Finding Index Name sp_helpindex tbl_WithIndex;
|
index_name
|
index_description
|
index_keys
|
|
PK__tbl_With__14CCD97D3AD6B8E2
|
кластерный, уникальный первичный ключ, расположенный на ПЕРВИЧНОМ |
EmpId |
-- Insert Some Records INSERT INTO [dbo].[tbl_WithIndex] (EMPID, EMPNAME) VALUES (101, 'Joydeep Das'), (102, 'Sukamal Jana'), (103, 'Ranajit Shinah'); GO
Теперь мы собираемся сравнить результаты выполнения плана
SELECT * FROM [dbo].[tbl_WithoutIndex];
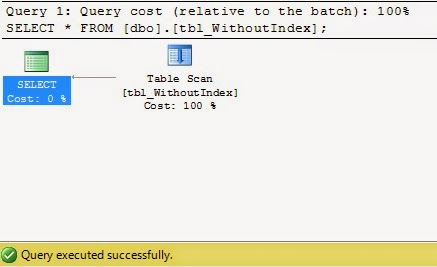
не имеет индекса (здесь я имею в виду кластеризованный индекс) таблица является кучей. Поэтому, когда мы помещаем оператор SELECT, сканируется вся таблица.
SELECT * FROM [dbo].[tbl_WithIndex];

Здесь у таблицы есть ПЕРВИЧНЫЙ КЛЮЧ, поэтому он имеет кластерный индекс. Но здесь мы не помещаем столбцы индекса в предложение WHERE, поэтому происходит сканирование кластерного индекса.
Внимательное наблюдение за планом выполнения

Пожалуйста, помните, что таблица имеет небольшое количество записей.
|
Имя таблицы
|
Ориентировочная стоимость ввода-вывода
|
|
tbl_WithoutIndex
|
0.0032035
|
|
Tbl_WithIndex
|
0.003125
|
Если мы увидим оценочную стоимость операции , она будет одинаковой для обоих запросов ( 0,0032853 ).
Вопрос в мыслях
Здесь мы видим, что оценочная стоимость операции для обоих запросов одинакова. Итак, Вопрос в том, что если происходит сканирование индекса, мы можем удалить индекс и использовать кучу (в нашем случае). Так есть ли другая разница между ними?
Как они отличаются
Здесь мы понимаем, в чем внутренняя разница между сканированием таблиц и индексным сканированием.
Когда происходит сканирование таблицы, сервер MS SQL считывает все строки и столбцы в память. Когда происходит сканирование индекса, он будет читать все строки и только столбцы в индексе.
Эффекты в производительности
В случае производительности сканирование таблицы и сканирование индекса имеют одинаковый вывод, если мы используем одну инструкцию SELECT таблицы. Но это отличается в случае сканирования индекса, когда мы собираемся в таблицу JOIN.
Надеюсь, вам понравится.