При работе с многомерными массивами программист должен принять довольно важное решение в самом начале проекта: какой тип памяти использовать для хранения данных и как получить к ним наиболее эффективный доступ. Поскольку память компьютера по своей природе линейна — это одномерная структура, отображение многомерных данных на нее может быть выполнено несколькими способами. В этой статье я хочу подробно изучить эту тему, рассказывая о различных доступных макетах памяти и их влиянии на производительность кода.
Роу-мажор против Мэйн-мажора
Безусловно, два наиболее распространенных макета памяти для данных многомерного массива — основной ряд и основной столбец .
При работе с двумерными массивами (матрицами) основные строки и основные столбцы легко описать. Макет основной строки матрицы помещает первую строку в непрерывную память, затем вторую строку сразу после нее, затем в третью и т. Д. Макет основной колонки помещает первый столбец в непрерывную память, затем второй и т. Д.
Более высокие размеры немного сложнее визуализировать, поэтому давайте начнем с некоторых диаграмм, показывающих, как работают 2D-макеты.
2D Row-Major
Сначала несколько замечаний по номенклатуре этой статьи. Память компьютера будет представлена в виде линейного массива с низкими адресами слева и высокими адресами справа. Также мы будем использовать нотацию программиста для матриц: строки и столбцы начинаются с нуля, в верхнем левом углу матрицы. Индексы строк идут по строкам сверху вниз; индексы столбцов идут над столбцами слева направо.
Как упомянуто выше, в макете основной строки первая строка матрицы помещается в непрерывную память, затем вторая и так далее:
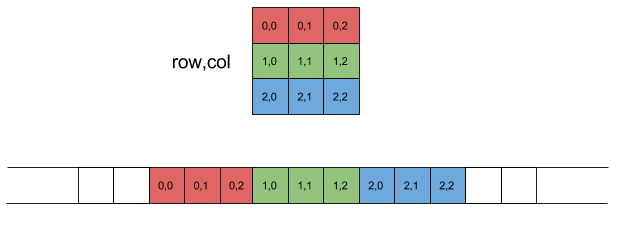
Другой способ описать расположение строк — это то, что индексы столбцов меняются быстрее всего . Это должно быть очевидно, если взглянуть на линейное расположение внизу диаграммы. Если вы прочтете пары индексов элементов слева направо, вы заметите, что индекс столбцов изменяется все время, а индекс строк изменяется только один раз для каждой строки.
Для программистов еще одним важным наблюдением является то, что с учетом индекса строки и индекса 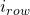 столбца
столбца 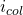 смещение элемента, который они обозначают в линейном представлении:
смещение элемента, который они обозначают в линейном представлении:
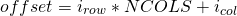
Где NCOLS — количество столбцов в строке в матрице. Легко видеть, что это уравнение соответствует линейному расположению на диаграмме, показанной выше.
2D колонна-майор
Описание двухмерного макета столбца — это просто описание основного ряда и замена каждого появления «строки» на «столбец» и наоборот. Первый столбец матрицы помещается в непрерывную память, затем второй и т. Д.

В основной колонке макеты строк изменяются быстрее всего . Смещение элемента в основной колонке можно найти с помощью этого уравнения:
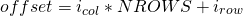
Где NROWS — количество строк на столбец в матрице.
Beyond 2D — индексирование и компоновка N-мерных массивов
Хотя матрицы являются наиболее распространенными многомерными массивами, с которыми имеют дело программисты, они далеко не единственные. Обозначения многомерных массивов полностью обобщаются на более чем 2 измерения. Эти объекты обычно называют «массивами ND» или «тензорами».
Когда мы переходим в 3D и далее, лучше оставить обозначение строк / столбцов матриц. Это связано с тем, что это обозначение нелегко преобразовать в 3 измерения из-за общей путаницы между строками, столбцами и декартовой системой координат. В четырех измерениях и выше мы теряем любую чисто визуальную интуицию для описания многомерных сущностей, поэтому лучше вместо этого придерживаться последовательной математической записи.
Итак, давайте поговорим о некотором произвольном количестве измерений d , пронумерованных от 1 до d . Для каждого измерения 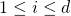 ,
, 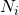 является размер размерности. Кроме того , индекс элемента в измерении
является размер размерности. Кроме того , индекс элемента в измерении 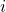 находится
находится  . Например, в последней матричной диаграмме выше (где показано расположение столбцов) мы имеем
. Например, в последней матричной диаграмме выше (где показано расположение столбцов) мы имеем 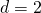 . Если мы выберем измерение 1 как строку, а измерение 2 — как столбец, тогда
. Если мы выберем измерение 1 как строку, а измерение 2 — как столбец, тогда 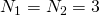 и элемент в нижнем левом углу матрицы имеет
и элемент в нижнем левом углу матрицы имеет 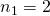 и
и 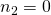 .
.
В макете многомерных массивов на уровне строк последний индекс изменяется наиболее быстро. В случае матриц последний индекс — столбцы, так что это эквивалентно предыдущему определению.
Для данного 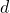 -мерного массива с обозначениями, показанными выше, мы вычисляем место в памяти элемента по его индексам как:
-мерного массива с обозначениями, показанными выше, мы вычисляем место в памяти элемента по его индексам как:
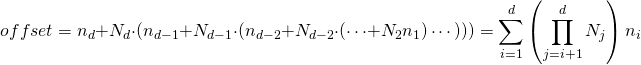
Для матрицы это сводится к:
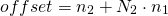
Это именно та формула, которую мы видели выше для макета основной строки, просто используя немного более формальную запись.
Аналогичным образом, в макете многомерных массивов по главному столбцу первый индекс изменяется наиболее быстро. Для данного -мерного массива мы вычисляем область памяти элемента по его индексам как:
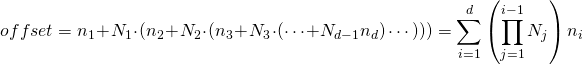
И снова для матрицы с этим сводится к привычному:
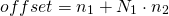
Пример в 3D
Давайте посмотрим, как это работает в 3D, который мы все еще можем визуализировать. Предполагая 3 измерения: строки, столбцы и глубина. На следующей схеме показано распределение памяти 3D — массива с 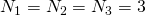 , в строке-главная :
, в строке-главная :
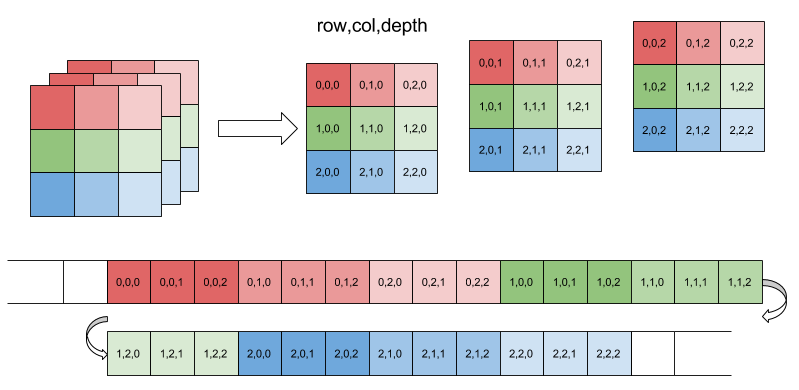
Обратите внимание, как последнее измерение (в данном случае глубина) изменяется быстрее всего, а первое (строка) изменяется медленнее. Смещение для данного элемента:
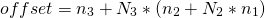
Например, смещение элемента с индексами 2,1,1 составляет 22.
В качестве упражнения попытайтесь выяснить, как этот массив будет размещен в основном порядке столбцов . Но будьте осторожны — есть предостережение! Термин « столбец-майор» может заставить вас поверить, что столбцы — это самый медленно меняющийся индекс, но это неверно. Последний показателем является самым медленным изменением в столбцах, а последний индекс здесь глубина, а не столбцы. На самом деле, столбцы были бы прямо посередине с точки зрения скорости изменения. Именно поэтому в обсуждении выше я предложил отказаться от обозначения строки / столбца при переходе выше 2D. В более высоких измерениях это сбивает с толку, поэтому лучше обратиться к относительной скорости изменения индексов, поскольку они однозначны.
Фактически, можно представить своего рода гибридную (или «смешанную») компоновку, в которой второе измерение изменяется быстрее, чем первое или третье. Это не будет ни основной строкой, ни основной столбца, но сама по себе это согласованная и совершенно корректная компоновка, которая может принести пользу некоторым приложениям. Подробнее о том, почему мы выбрали один макет вместо другого, позже в статье.
История: Фортран против С
Хотя знание того, какой макет использует конкретный набор данных, имеет решающее значение для хорошей производительности, нет однозначного ответа на вопрос, какой макет «лучше» в целом. Это мало чем отличается от дебатов с прямым порядком байтов или с прямым порядком байтов; важно выбрать последовательный стандарт и придерживаться его. К сожалению, как почти всегда бывает в мире вычислений, разные языки программирования и среды выбирают разные стандарты.
Среди языков программирования, все еще популярных сегодня, Fortran был определенно одним из пионеров. И Fortran (который все еще очень важен для научных вычислений) использует макет для колонки. Я где-то читал, что причина этого в том, что векторы столбцов чаще используются и считаются «каноническими» в вычислениях линейной алгебры. Лично я не покупаю это, но вы можете сделать свое собственное мнение.
Множество современных языков следуют примеру Фортрана — Matlab, R, Julia и многие другие. Одна из самых веских причин для этого заключается в том, что они хотят использовать LAPACK — быструю библиотеку Fortran для линейной алгебры, поэтому использование компоновки Fortran имеет смысл.
С другой стороны, C и C ++ используют разметку основных строк. Следуя их примеру, несколько других популярных языков, таких как Python, Pascal и Mathematica. Поскольку многомерные массивы являются типом первого класса в языке C, стандарт очень четко определяет макет в разделе 6.5.2.1.
Фактически, иметь первое изменение индекса самым медленным, а последнее изменение индекса самым быстрым имеет смысл, если вы подумаете о том, как индексируются многомерные массивы в Си.
Учитывая декларацию:
int x[3][5];
Тогда x является массивом из 3 элементов, каждый из которых является массивом из 5 целых чисел. x [1] является адресом второго массива из 5 целых чисел, содержащихся в x, а x [1] [4] является пятым целым числом второго 5-целого массива в x. Эти правила индексации подразумевают разметку основных строк.
Ничто из этого не говорит о том, что C не мог выбрать макет для колонки. Возможно, но тогда правила его индексации многомерного массива также должны были быть другими. Результат может быть таким же последовательным, как и сейчас.
Более того, поскольку C позволяет вам манипулировать указателями, вы можете выбирать расположение данных в вашей программе, самостоятельно вычисляя смещения в многомерных массивах. Фактически, так написано большинство программ на Си.
Пример расположения памяти — Numpy
До сих пор мы обсуждали макет памяти исключительно концептуально — используя диаграммы и математические формулы для вычисления индекса. Стоит увидеть «реальный» пример того, как многомерные массивы хранятся в памяти. Для этой цели библиотека Numpy из Python является отличным инструментом, поскольку она поддерживает оба типа макетов и с ней легко играть из интерактивной оболочки.
Конструктор numpy.array можно использовать для создания многомерных массивов. Одним из параметров, который он принимает, является порядок, который является либо «C» для разметки в стиле C (основной ряд), либо «F» для разметки в стиле Fortran (основной столбец). «С» является значением по умолчанию. Посмотрим, как это выглядит:
In [42]: ar2d = numpy.array([[1, 2, 3], [11, 12, 13], [10, 20, 40]], dtype='uint8', order='C')
In [43]: ' '.join(str(ord(x)) for x in ar2d.data)
Out[43]: '1 2 3 11 12 13 10 20 40'В порядке «C» элементы строк, как и ожидалось, являются смежными. Давайте попробуем макет Фортрана сейчас:
In [44]: ar2df = numpy.array([[1, 2, 3], [11, 12, 13], [10, 20, 40]], dtype='uint8', order='F')
In [45]: ' '.join(str(ord(x)) for x in ar2df.data)
Out[45]: '1 11 10 2 12 20 3 13 40'Для более сложного примера давайте закодируем следующий трехмерный массив как numpy.array и посмотрим, как он устроен:
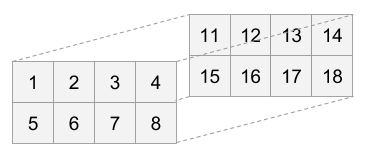
Этот массив имеет две строки (первое измерение), 4 столбца (второе измерение) и глубину 2 (третье измерение). Как вложенный список Python, это его представление:
In [47]: lst3d = [[[1, 11], [2, 12], [3, 13], [4, 14]], [[5, 15], [6, 16], [7, 17], [8, 18]]]
И расположение памяти в порядке C и Fortran:
In [50]: ar3d = numpy.array(lst3d, dtype='uint8', order='C')
In [51]: ' '.join(str(ord(x)) for x in ar3d.data)
Out[51]: '1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18'
In [52]: ar3df = numpy.array(lst3d, dtype='uint8', order='F')
In [53]: ' '.join(str(ord(x)) for x in ar3df.data)
Out[53]: '1 5 2 6 3 7 4 8 11 15 12 16 13 17 14 18'Обратите внимание, что в макете C (основной ряд) первое измерение (строки) изменяется медленнее, а третье измерение (глубина) меняется быстрее всего. В макете Фортрана (основной столбец) первое измерение изменяется быстрее, а третье — медленнее.
Производительность: почему стоит позаботиться о том, в каком макете находятся ваши данные
После прочтения статьи до сих пор можно задаться вопросом, почему все это имеет значение. Разве это не просто еще один способ расхождения стандартов, а-ля endianness? Пока мы все согласны с макетом, разве это не скучная деталь реализации? Почему мы заботимся об этом?
Ответ: производительность. Мы говорим о числовых вычислениях здесь (сокращение чисел на больших наборах данных), где производительность почти всегда критична. Оказывается, что соответствие того, как ваш алгоритм работает с макетом данных, может снизить или снизить производительность приложения.
Короткий вывод: всегда просматривайте данные в порядке их размещения . Если ваши данные находятся в памяти в макете основной строки, итерируйте по каждой строке перед переходом к следующей и т. Д. В оставшейся части раздела будет объяснено, почему это так, а также будет представлена контрольная маска с некоторыми измерениями, чтобы получить представление о последствия этого решения.
Существуют два аспекта современной компьютерной архитектуры, которые оказывают большое влияние на производительность кода и имеют отношение к нашему обсуждению: кеширование и векторные блоки. Когда мы выполняем итерацию по каждой строке массива с основными строками, мы получаем доступ к массиву последовательно. Этот шаблон имеет пространственную локальность , что делает код идеальным для оптимизации кэша. Более того, в зависимости от операций, которые мы выполняем с данными, векторный блок ЦП может срабатывать, поскольку он также требует последовательного доступа.
Графически это выглядит примерно так: Допустим, у нас есть массив: int array [128] [128], и мы перебираем каждую строку, переходя к следующей, когда посещаются все столбцы в текущей. Число в каждой серой ячейке является адресом памяти — оно увеличивается на 4, поскольку это массив, если он целочисленный. Синяя пронумерованная стрелка перечисляет доступы в порядке их выполнения:
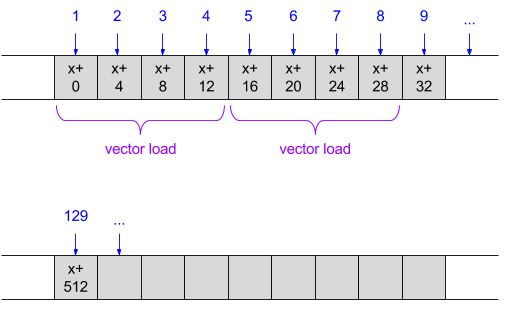
Здесь оптимальное использование кэширования и векторных инструкций должно быть очевидным. Поскольку мы всегда обращаемся к элементам последовательно, это идеальный сценарий для кэшей ЦП — мы всегда попадем в кеш . На самом деле, мы всегда используем самый быстрый кеш — L1, потому что процессор правильно предварительно выбирает все данные впереди.
Более того, поскольку мы всегда читаем одно 32-битное слово за другим, мы можем использовать векторные единицы процессора для загрузки данных (и, возможно, процесс будет позже). Фиолетовые стрелки показывают, как это можно сделать с помощью векторных нагрузок SSE, которые одновременно захватывают 128-битные фрагменты (четыре 32-битных слова). В реальном коде это может быть сделано либо с помощью встроенных функций, либо с помощью автоматического векторизатора компилятора (как мы скоро увидим в реальном примере кода).
Сравните это с доступом к этим основным данным строки по одному столбцу за раз, итерируя по каждому столбцу перед переходом к следующему:
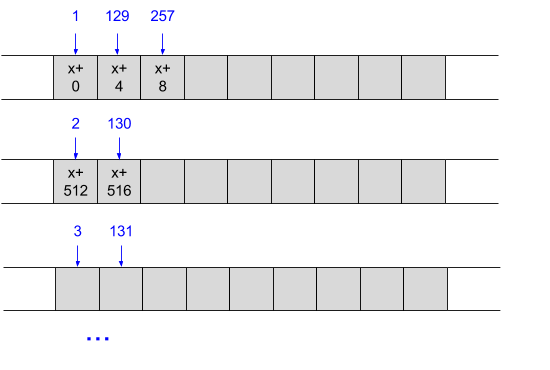
Здесь мы теряем пространственную локальность, если только массив не очень узкий. Если столбцов мало, в кэше могут быть найдены последовательные строки . Тем не менее, в более типичных приложениях массивы большие, и когда происходит доступ № 2, вполне вероятно, что память, к которой он обращается, нигде не будет найдена в кэше. Неудивительно, что мы также теряем векторные единицы, поскольку доступ не осуществляется к последовательной памяти.
Но что делать, если вашему алгоритму необходим доступ к данным столбец за столбцом, а не строка за строкой? Очень простой! Это именно то, для чего предназначен макет колонки. В случае данных с основными столбцами этот шаблон доступа затронет все те же архитектурные области, которые мы видели при последовательном доступе к данным с основными строками.
Диаграммы выше должны быть достаточно убедительными, но давайте сделаем некоторые реальные измерения, чтобы увидеть, насколько драматичны эти эффекты.
Полный код теста доступен здесь , поэтому я просто покажу несколько выбранных фрагментов. Начнем с базового типа матрицы, размещенного в линейной памяти:
// A simple Matrix of unsigned integers laid out row-major in a 1D array. M is
// number of rows, N is number of columns.
struct Matrix {
unsigned* data = nullptr;
size_t M = 0, N = 0;
};Матрица использует макет основной строки: доступ к ее элементам осуществляется с помощью этого выражения C:
x.data[row * x.N + col]Вот функция, которая добавляет две такие матрицы вместе, используя «плохой» шаблон доступа — итерацию по строкам в каждом столбце перед переходом к следующему столбцу. Паттер доступа очень легко обнаружить, глядя на код на C — внутренний цикл — это быстро меняющийся индекс, и в данном случае это строки:
void AddMatrixByCol(Matrix& y, const Matrix& x) {
assert(y.M == x.M);
assert(y.N == x.N);
for (size_t col = 0; col < y.N; ++col) {
for (size_t row = 0; row < y.M; ++row) {
y.data[row * y.N + col] += x.data[row * x.N + col];
}
}
}И вот версия, которая использует лучший шаблон, итерируя по столбцам в каждой строке перед переходом к следующей строке:
void AddMatrixByRow(Matrix& y, const Matrix& x) {
assert(y.M == x.M);
assert(y.N == x.N);
for (size_t row = 0; row < y.M; ++row) {
for (size_t col = 0; col < y.N; ++col) {
y.data[row * y.N + col] += x.data[row * x.N + col];
}
}
}Как соотносятся две модели доступа? Исходя из обсуждения в этой статье, мы ожидаем, что шаблон доступа по строкам будет быстрее. Но насколько быстрее? И какую роль играет векторизация против эффективного использования кеша?
Чтобы попробовать это, я запустил шаблоны доступа для матриц разных размеров и добавил вариант шаблона по строкам, где векторизация отключена. Вот результаты; вертикальные полосы представляют полосу пропускания — сколько миллиардов элементов (32-битных слов) было обработано (добавлено) данной функцией.
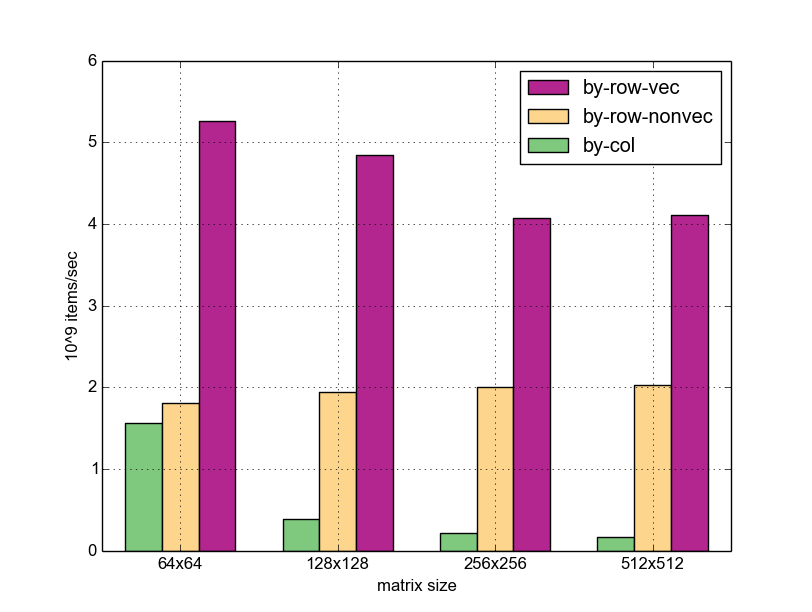
Некоторые наблюдения:
- Для размеров матрицы выше 64×64 доступ по строкам значительно быстрее, чем по столбцам (6-8x, в зависимости от размера). В случае 64×64, я полагаю, происходит то, что обе матрицы помещаются в кэш-память L1 объемом 32 КБ моей машины, поэтому шаблон по столбцам действительно может найти следующую строку в кэше. Для больших размеров матрицы больше не помещаются в L1, поэтому версия по столбцам должна часто переходить в L2.
- Векторизованная версия превосходит не векторизованную версию в 2-3 раза во всех случаях. На больших матрицах ускорение немного меньше; Я думаю, это потому, что при разрешении 256×256 и выше матрицы больше не помещаются в L2 (у моей машины 256KB) и требуется более медленный доступ к памяти. Таким образом, процессор тратит немного больше времени на ожидание памяти в среднем.
- Общее ускорение векторизованного доступа по строкам по сравнению с доступом по столбцам огромно — до 25x для больших матриц.
Я должен признать, что, хотя я ожидал, что построчный доступ будет быстрее, я не ожидал, что он будет намного быстрее. Очевидно, что выбор правильного шаблона доступа для структуры памяти данных абсолютно необходим для производительности приложения.
Резюме
В этой статье рассматривается проблема размещения многомерных массивов под разными углами. Основной вывод: узнайте, как выложены ваши данные, и получите к ним соответствующий доступ. В языках программирования на основе C, хотя макет по умолчанию для двумерных массивов является основным по строкам, когда мы используем указатели для динамически размещаемых данных, мы можем выбирать любой макет, который нам нравится. В конце концов, многомерные массивы — это просто логическая абстракция над линейной системой хранения.
Из-за чудес современной архитектуры ЦП выбор «правильного» способа доступа к многомерным данным может привести к колоссальному ускорению; следовательно, это то, о чем всегда следует помнить программисту при работе с большими многомерными наборами данных.
Взято из черновика n1570 стандарта С11. Раньше термин «слово» четко ассоциировался с 16-битным объектом в прошлом («двойное слово» означало 32 бита и т. Д.), Но в наши дни он слишком перегружен. В различных онлайн-ссылках вы найдете слово от 16 до 64 бит, в зависимости от архитектуры процессора. Так что я намеренно обойду путаницу, явно упомянув размер слова в битах. См. Репозиторий тестов для получения полной информации, включая атрибуты функций и флаги компилятора. Особая благодарность Надаву Ротему за то, что он помог мне продумать проблему, которая у меня изначально возникла из-за того, что g ++ игнорировал мой атрибут no-tree-vectorize при вставке функции в тест.Я выключил встраивание, чтобы исправить это.