На этот раз это личное. Суперкубок 50 разыгрывается на стадионе Леви в Санта-Кларе — в поле зрения многих самых инновационных технологических компаний мира, включая MapR. Это Суперкубок Силиконовой долины *, поэтому имеет смысл только то, что это будет самый переоцененный случай в истории (по крайней мере, до следующей большой игры).
Большие события с неизвестными результатами привлекают большие деньги. За последние несколько Суперкубков в спортивной книге Лас-Вегаса было разыграно более 100 миллионов долларов. Везде, где есть большие деньги , вполне естественно, что вы найдете большие данные . Мы использовали Apache Spark для анализа результатов игр в НФЛ, применяя машинное обучение, чтобы найти самородок, который, возможно, пропустили диезы в Вегасе.
* В 1985 году в Стэнфорде была организована игра, которая превратилась в псевдо-домашнюю игру для 49ers. Можно утверждать, что этот конкурс был первым Суперкубком «Силиконовой долины», но ведущие предприниматели этого поколения, которые были малышами в то время, могут не согласиться.
Более / менее
Суперкубок известен своими «опорными» ставками, которые включают бросок монеты, длину государственного гимна или цвет Gatorade, брошенного на победившего тренера в последние секунды. Если цель состоит в том, чтобы использовать методы больших данных, чтобы дать нам преимущество, предпочтительно придерживаться основных ставок, поскольку для анализа доступны тысячи игр и результатов.
Двумя основными ставками, по которым доступны данные, являются спред (предел победы, который фаворит должен превысить, чтобы выиграть) и овер / минус. Последний — общее количество очков, набранных обеими командами; если мы сможем проанализировать данные игры и решить, будет ли она похожа на игру с низкими показателями по сравнению с прорывом, основанным на нарушениях, у нас может быть возможность делать ставки. Стоит отметить, что цель установления линии не состоит в том, чтобы предсказать результат — Спортивные книги устанавливают линии так, чтобы с обеих сторон была поставлена равная сумма денег. Вот почему линии будут корректироваться, когда деньги поступают слишком односторонне.
Делать ставки больше / меньше не будет легко. Из приведенного ниже рисунка можно сделать вывод, что, основываясь на тысячах игр с 1990 года, те, кто установил более / менее, делают это очень и очень точно.
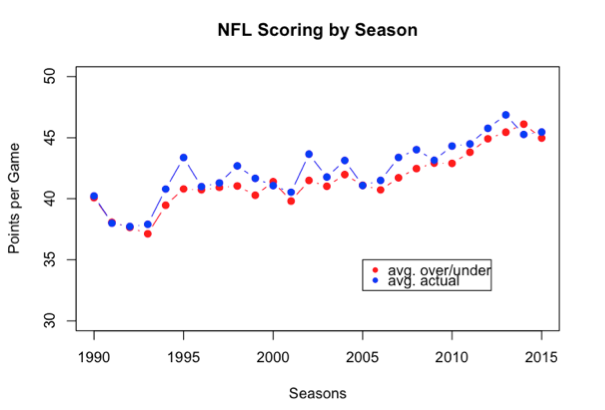
Одним заметным аспектом игр НФЛ является то, что команды постепенно набирают больше очков с 1990 года (общее увеличение на 5 пунктов). Есть много вероятных факторов, которые способствуют этому результату (например, расширение, изменения правил, которые способствуют нарушению и т. Д.), Но также отмечают, что предсказанные очки, набранные (то есть, больше / меньше), отслеживают эту модель почти идеально.
Получение данных в Apache Spark
Хорошей новостью является то, что с 1990 года существует более 6 000 игр, которые мы можем легко проанализировать. Но мы должны ограничиться использованием информации о каждой игре, доступной перед игрой, для прогнозирования результата (иначе это испортит результаты).
Apache Spark — это отличный инструмент с открытым исходным кодом для анализа больших данных, который также хорошо работает за пределами сети. После очистки популярного спортивного справочного сайта для игровых данных скриптом Python данные импортируются в оболочку Spark для некоторого исследовательского анализа. Все данные и код для воспроизведения результатов или изучения самостоятельно находятся здесь.
После загрузки данных игры (включая разброс, поле и погодные условия, а также результаты) в СДР Spark мы можем исследовать каждую игру, начиная с 1990 года, с помощью оболочки Spark, чтобы получить статистику и найти некоторые странности.
Например, вот команда, которая обнаруживает, что игра с самым низким выигрышем была фактически двумя играми, где преступления обеих команд имели всего 3 очка:
|
1
2
3
4
5
6
|
rawFeatures.map{game=> (game._1,game._10) }.sortBy(_._2).take(5).foreach(println)(New York Jets at Washington Redskins - December 11th, 1993,3.0)(Miami Dolphins at Pittsburgh Steelers - November 26th, 2007,3.0)(Indianapolis Colts at New England Patriots - December 6th, 1992,6.0)(Atlanta Falcons at Chicago Bears - October 3rd, 1993,6.0)(New York Jets at New England Patriots - November 28th, 1993,6.0) |
Самой результативной игрой в наборе данных (которая включает в себя регулярный сезон и плей-офф с сезона 1990 года) была игра с 106 очками между Кливлендом и Цинциннати в 2004 году (бенгальцы выиграли 58-48):
|
1
2
3
4
5
6
|
rawFeatures.map{game=> (game._1,game._10) }.sortBy(_._2,false).take(5).foreach(println)(Cleveland Browns at Cincinnati Bengals - November 28th, 2004,106.0)(New York Giants at New Orleans Saints - November 1st, 2015,101.0)(Denver Broncos at Dallas Cowboys - October 6th, 2013,99.0)(Cincinnati Bengals at Cleveland Browns - September 16th, 2007,96.0)(Green Bay Packers at Arizona Cardinals - January 10th, 2010,96.0) |
Мы можем использовать Spark, чтобы найти, что самый высокий спред в игре с 1990 года был 26,5, когда Денвер принимал Джексонвилль в 2013 году (Бронкос выиграл 35-19, но не покрыл спред):
|
1
2
3
4
5
6
|
rawFeatures.map{game=> (game._1,game._8) }.sortBy(_._2,false).take(5).foreach(println)(Jacksonville Jaguars at Denver Broncos - October 13th, 2013,26.5)(Philadelphia Eagles at New England Patriots - November 25th, 2007,24.5)(Cincinnati Bengals at San Francisco 49ers - December 5th, 1993,24.0)(Miami Dolphins at New England Patriots - December 23rd, 2007,22.5)(New York Jets at New England Patriots - December 16th, 2007,20.5) |
Впечатляет то, как часто фактическая оценка выше или ниже, чем выше / ниже (это расщепление 48% / 49%):
|
1
2
3
4
5
6
|
rawFeatures.map{game=> (game._1,game._10-game._9)}.filter(m=> m._2 > 0).countres23: Long = 3249 ### number of games where score > over/underrawFeatures.map{game=> (game._1,game._10-game._9)}.filter(m=> m._2 < 0).countres25: Long = 3317 ### number of games where score < over/underrawFeatures.map{game=> (game._1,game._10-game._9)}.filter(m=> m._2 == 0).countres26: Long = 125 ### a push – where the points scored = over/under |
Этот вид исследования важен для понимания ваших данных, но до сих пор мы не узнали ничего, что не было бы доступно посредством быстрого поиска в Интернете (где вы можете обнаружить, что в 1966 году была еще более высокая оценка — 113 очков!). Нам следует покопаться немного глубже, чтобы увидеть, сможем ли мы найти некоторые идеи, которые могут дать нам преимущество в ставках за / против.
K-ближайший соседний алгоритм
Метод K-Nearest Neighbor (KNN) — это хорошо известный нелинейный алгоритм машинного обучения, в котором поиск всех точек данных выполняется для нахождения K-наиболее похожих точек, а затем результаты из этих K точек объединяются для получения ответ. Чтобы предсказать количество очков, набранных за Суперкубок 50, мы сравним эту игру со всеми играми, начиная с 1990 года. Для ближайших матчей мы посмотрим на количество очков, набранных среди похожих игр, а затем сравним это распределение с положительным / отрицательным устанавливается спортивными книгами.
Вот числовые функции, которые мы будем использовать для поиска «похожих» игр (помните, что мы ограничены общедоступными и доступными до игры данными):

Если мы соберем ту же информацию о Суперкубке (включая прогноз погоды) и трансформируем ее в описанные выше функции, это позволит нам использовать алгоритмы KNN для поиска похожих игр. Все функции были преобразованы в диапазон 0-1, чтобы избежать слишком большого веса переменных с большой дисперсией.
Одна из особенностей, которая имеет тенденцию ограничивать использование KNN, заключается в том, что он не может быть предварительно вычислен в автономном режиме и должен запускаться по требованию. По мере роста числа потенциальных сравнений этот метод становится вычислительно интенсивным. Из-за этого, это очень хороший кандидат для распределенных вычислений Hadoop.
Больше или меньше?
Прогноз для Супер Боул этого года — 60 ° F с влажностью 72% и ветром около 10 миль в час. В игру будут играть на траве, на открытом воздухе, ранний спред составляет 4,5 очка, а значение «больше / меньше» установлено на 45.
Исходя из тенденции роста количества очков в лиге с 1990 года, более ранняя половина очков была признана непригодной для включения в аналогичные игры. Приведенные ниже команды оболочки Spark использовались для расчета евклидова расстояния между прогнозом Суперкубка и играми, сыгранными с 2002 года, а затем для нахождения 50 наиболее похожих игр (также приведены квадрат расстояния и общее количество очков):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
def calcDistance(game:(String, Double, Double, Double, Double, Double, Double, Double, Double, Double, String), test:(String, Double, Double, Double, Double, Double, Double, Double, Double, Double,String)):(Double) = { var distance = 0.0 //(parts(0),time,roof,field,temperature,humidity,wind,spread,overunder,points) distance += math.pow(game._2-test._2,2) distance += math.pow(game._3-test._3,2) distance += math.pow(game._4-test._4,2) distance += math.pow(standardize(game._5,tempStats)-standardize(test._5,tempStats),2) distance += math.pow(game._6/100-test._6/100,2) distance += math.pow(standardize(game._7,windStats)-standardize(test._7,windStats),2) distance += math.pow(standardize(game._8,spreadStats)-standardize(test._8, spreadStats),2) distance += math.pow(standardize(game._9,overStats)-standardize(test._9,overStats),2) (distance)}val distances = rawFeatures.filter(m=> m._5 > -99.0 && m._6> -99.0 && m._7> -99.0 && m._8> -99.0 && m._11.toDouble >2001).map{ game => (game._1,calcDistance(game,parsedTest),game._10)}distances.sortBy(_._2).take(50).foreach(println)(New Orleans Saints at Oakland Raiders - October 24th, 2004,0.0042870560083087,57.0)(Minnesota Vikings at Oakland Raiders - November 16th, 2003,0.0055692573219246,46.0)(Dallas Cowboys at Green Bay Packers - October 24th, 2004,0.005933245943430532,61.0)(Denver Broncos at San Diego Chargers - October 19th, 2009,0.00604229789149342,57.0)(New York Giants at San Francisco 49ers - November 13th, 2011,0.00610927509202,47.0)… |
Самой похожей игрой была битва между Святыми и Рейдерами 24.10.04, в которой было набрано 57 очков. Гистограмма, показывающая распределение очков между всеми 50 играми, показана ниже:
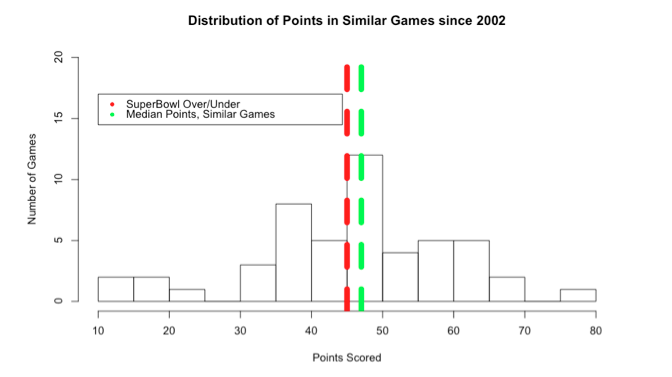
Среднее число очков, набранных среди наиболее похожих 50 игр (т. Е. Зеленая линия), выше, чем положительное / отрицательное значение (т. Е. Красная линия @ 45). Это небольшое свидетельство того, что количество очков в Суперкубке 50 будет выше 45, и мы должны ставить больше. Граница победы может быть небольшой, но в конечном итоге вам будет гораздо лучше, чем подбрасывать монету.
| Ссылка: | Ставьте Супер Боул 50 Like A Boss с Apache Spark от нашего партнера JCG Джозефа Блу в блоге Mapr . |