В этой статье я сосредоточусь на использовании простых операторов SQL SELECT для подсчета количества строк в таблице, соответствующих определенному условию, с результатами, сгруппированными по определенному столбцу таблицы. Все это базовые понятия SQL , но их смешивание позволяет получать различные и полезные представления данных, хранящихся в реляционной базе данных. Конкретными аспектами SQL-запроса, описанными в этом посте и проиллюстрированными на простых примерах, являются статистическая функция count() , WHERE , GROUP BY и HAVING . Они будут использоваться для создания простого одного запроса SQL, который указывает количество строк в таблице, которые соответствуют различным значениям для данного столбца в этой таблице.
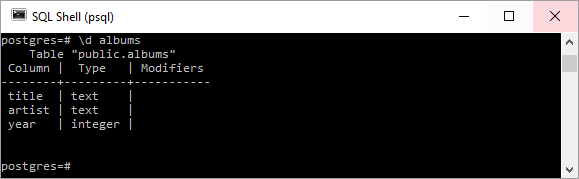
Мне понадобятся некоторые простые данные SQL для демонстрации. Следующий код SQL демонстрирует создание таблицы с именем ALBUMS в базе данных PostgreSQL с последующим использованием операторов INSERT для заполнения этой таблицы.
createAndPopulateAlbums.sql
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
CREATE TABLE albums( title text, artist text, year integer);INSERT INTO albums (title, artist, year) VALUES ('Back in Black', 'AC/DC', 1980);INSERT INTO albums (title, artist, year) VALUES ('Slippery When Wet', 'Bon Jovi', 1986);INSERT INTO albums (title, artist, year) VALUES ('Third Stage', 'Boston', 1986);INSERT INTO albums (title, artist, year) VALUES ('Hysteria', 'Def Leppard', 1987);INSERT INTO albums (title, artist, year) VALUES ('Some Great Reward', 'Depeche Mode', 1984);INSERT INTO albums (title, artist, year) VALUES ('Violator', 'Depeche Mode', 1990);INSERT INTO albums (title, artist, year) VALUES ('Brothers in Arms', 'Dire Straits', 1985);INSERT INTO albums (title, artist, year) VALUES ('Rio', 'Duran Duran', 1982);INSERT INTO albums (title, artist, year) VALUES ('Hotel California', 'Eagles', 1976);INSERT INTO albums (title, artist, year) VALUES ('Rumours', 'Fleetwood Mac', 1977);INSERT INTO albums (title, artist, year) VALUES ('Kick', 'INXS', 1987);INSERT INTO albums (title, artist, year) VALUES ('Appetite for Destruction', 'Guns N'' Roses', 1987);INSERT INTO albums (title, artist, year) VALUES ('Thriller', 'Michael Jackson', 1982);INSERT INTO albums (title, artist, year) VALUES ('Welcome to the Real World', 'Mr. Mister', 1985);INSERT INTO albums (title, artist, year) VALUES ('Never Mind', 'Nirvana', 1991);INSERT INTO albums (title, artist, year) VALUES ('Please', 'Pet Shop Boys', 1986);INSERT INTO albums (title, artist, year) VALUES ('The Dark Side of the Moon', 'Pink Floyd', 1973);INSERT INTO albums (title, artist, year) VALUES ('Look Sharp!', 'Roxette', 1988);INSERT INTO albums (title, artist, year) VALUES ('Songs from the Big Chair', 'Tears for Fears', 1985);INSERT INTO albums (title, artist, year) VALUES ('Synchronicity', 'The Police', 1983);INSERT INTO albums (title, artist, year) VALUES ('Into the Gap', 'Thompson Twins', 1984);INSERT INTO albums (title, artist, year) VALUES ('The Joshua Tree', 'U2', 1987);INSERT INTO albums (title, artist, year) VALUES ('1984', 'Van Halen', 1984); |
Следующие два снимка экрана показывают результаты выполнения этого скрипта в psql :
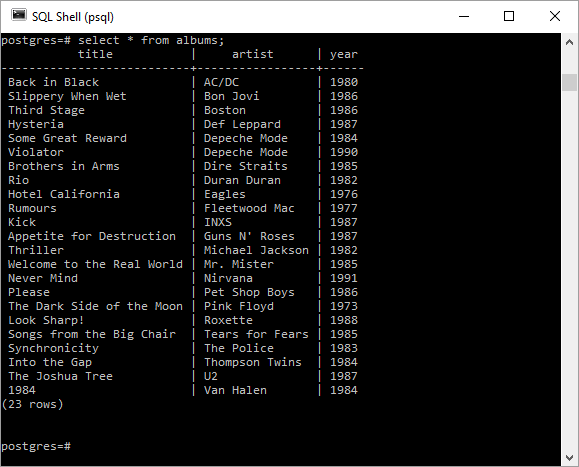
На этом этапе, если я хочу увидеть, сколько альбомов выпускалось за каждый год, я мог бы использовать несколько отдельных операторов SQL-запросов, например:
|
1
2
|
SELECT count(1) FROM albums where year = 1985;SELECT count(1) FROM albums where year = 1987; |
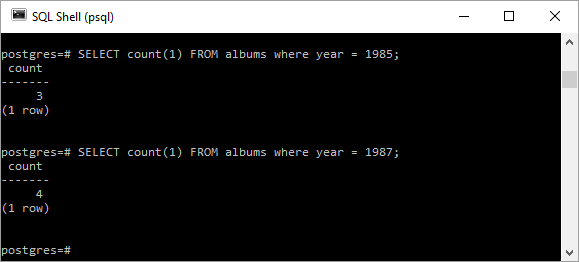
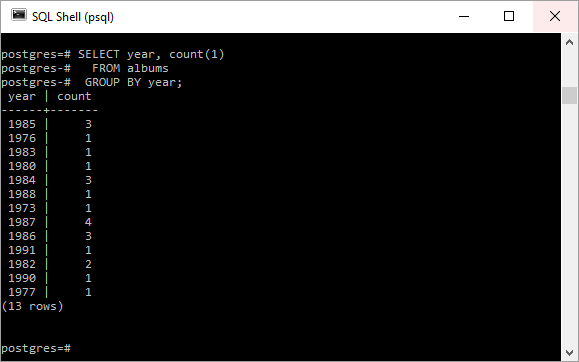
Возможно, было бы желательно увидеть, сколько альбомов было выпущено в каждом году, не требуя отдельного запроса для каждого года. Вот где использование агрегатной функции, такой как count () с предложением GROUP BY , очень удобно. Следующий запрос прост, но использует преимущества GROUP BY для отображения количества каждой «группы» строк, сгруппированных по годам выпуска альбомов.
|
1
2
3
|
SELECT year, count(1) FROM albums GROUP BY year; |
Предложение WHERE может использоваться как обычно, чтобы сузить число возвращаемых строк, указав условие сужения. Например, следующий запрос возвращает альбомы, выпущенные через год после 1988 года.
|
1
2
3
4
|
SELECT year, count(1) FROM albums WHERE year > 1988 GROUP BY year; |
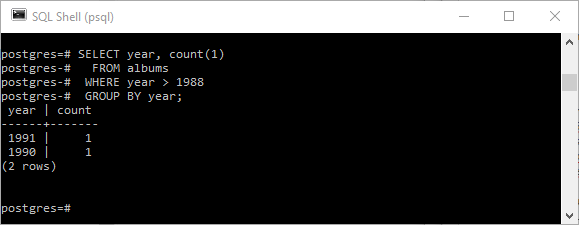
Возможно, мы захотим вернуть только те годы, за которые в нашей таблице находятся несколько альбомов (более одного). Первый наивный подход может быть таким, как показано ниже (не работает, как показано на снимке экрана ниже):
|
1
2
3
4
5
|
-- Bad Code!: Don't do this.SELECT year, count(1) FROM albums WHERE count(1) > 1 GROUP BY year; |
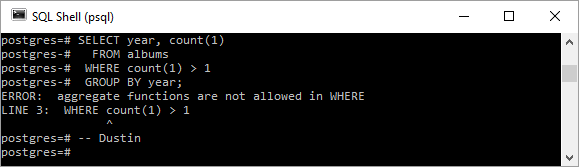
Последний снимок экрана демонстрирует, что «агрегатные функции недопустимы в WHERE». Другими словами, мы не можем использовать count() в WHERE . Здесь предложение HAVING полезно, потому что HAVING сужает результаты аналогично WHERE , но используется с агрегатными функциями и GROUP BY .
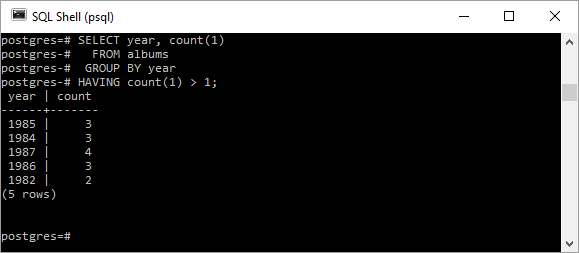
Следующий листинг SQL демонстрирует использование предложения HAVING для выполнения ранее выполненной задачи (перечисление лет, для которых в таблице существует несколько строк альбома):
|
1
2
3
4
|
SELECT year, count(1) FROM albums GROUP BY yearHAVING count(1) > 1; |
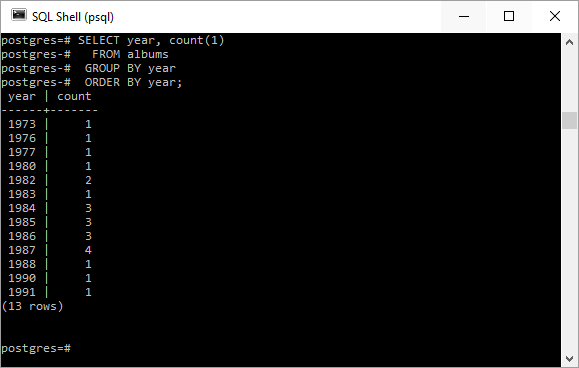
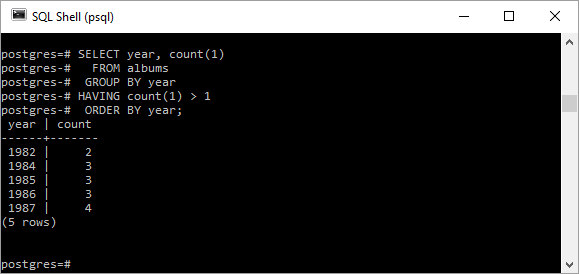
Наконец, я могу захотеть упорядочить результаты так, чтобы они были перечислены в последующих (последующих) годах. Два из SQL-запросов, продемонстрированных ранее, показаны здесь с добавлением ORDER BY .
|
1
2
3
4
|
SELECT year, count(1) FROM albums GROUP BY year ORDER BY year; |
|
1
2
3
4
5
|
SELECT year, count(1) FROM albums GROUP BY yearHAVING count(1) > 1 ORDER BY year; |
SQL стал гораздо более богатым языком, чем когда я впервые начал работать с ним, но базовый SQL, который был доступен в течение многих лет, остается эффективным и полезным. Хотя примеры в этом посте были продемонстрированы с использованием PostgreSQL, эти примеры должны работать на большинстве реляционных баз данных, которые реализуют ANSI SQL.
| Ссылка: | SQL: подсчет групп строк, совместно использующих общие значения столбцов от нашего партнера по JCG Дастина Маркса в блоге Inspired by Actual Events . |