Я работал в Spark-сервере Apache Gora в качестве своего проекта GSoC 2015 и закончил его. В этом посте я объясню, как это работает и как его использовать. Прежде всего, я предлагаю вам прочитать мои предыдущие посты о моем принятии GSoC 2015: http://furkankamaci.com/gsoc-2015-acceptance-for-apache-gora/ и Apache Gora: http: //www.javacodegeeks. com / 2015/08 / in-memory-data-model-and-persistence-for-big-data.html, если вы их еще не прочитали.
Apache Gora предоставляет модель данных в памяти и постоянство для больших данных. Gora поддерживает сохранение в хранилищах столбцов, хранилищах значений ключей, хранилищах документов и RDBMS, а также анализ данных с помощью расширенной поддержки Apache Hadoop MapReduce. Грубо говоря, Gora — это мощный проект, который может работать как Hibernate из мира NoSQL, и на нем можно запускать задания Map / Reduce. Даже Spark настолько мощен по сравнению с Map / Reduce, который в настоящее время поддерживает Gora; не было никакого Spark-бэкенда для Горы, и мой проект GSoC нацелен на это.
Я буду следовать примеру анализа логов, чтобы объяснить реализацию бэкэнда Spark во время моего поста. Он будет использовать логи сервера Apache, которые хранятся в хранилище данных. Я предлагаю вам скачать и скомпилировать исходный код Gora ( https://github.com/apache/gora ) и прочитать учебник Gora ( http://gora.apache.org/current/tutorial.html ), чтобы найти и сохранить пример журнала. Вы можете использовать его встроенные скрипты на Gora, чтобы сохранить пример данных.
Поскольку мы используем Apache Gora, мы можем использовать Hbase, Solr, MongoDB и т. Д. (Для полного списка: http://gora.apache.org/ ) в качестве хранилища данных. Gora запустит ваш код независимо от того, какое хранилище данных вы используете. В этом примере я сохраню пример набора журналов сервера Apache в Hbase ( версия: 1.0.1.1 ), прочту их оттуда, запустю на нем коды Spark и запишу результат в Solr ( версия: 4.10.3 ) ,
Во-первых, запустите хранилище данных для чтения значения. Я начну Hbase как хранилище постоянных данных:
|
1
2
|
furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/start-hbase.shstarting master, logging to /home/furkan/apps/hbase-1.0.1.1/bin/../logs/hbase-furkan-master-kamaci.out |
Пример Persist входит в Hbase (перед этой командой вы должны были распаковать access.log.tar.gz ):
|
1
|
furkan@kamaci:~/projects/gora$ ./bin/gora logmanager -parse gora-tutorial/src/main/resources/access.log |
После запуска команды parse запустите команду оболочки hbase:
|
1
2
3
4
5
|
furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/hbase shell2015-08-31 00:20:16,026 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableHBase Shell; enter 'help<RETURN>' for list of supported commands.Type "exit<RETURN>" to leave the HBase ShellVersion 1.0.1.1, re1dbf4df30d214fca14908df71d038081577ea46, Sun May 17 12:34:26 PDT 2015 |
и запустите команду списка . Вы должны увидеть вывод ниже, если до этого на вашей базе данных не было таблиц:
|
1
2
3
4
5
|
hbase(main):025:0> listTABLEAccessLog1 row(s) in 0.0150 seconds=> ["AccessLog"] |
Проверьте, есть ли какие-либо данные в таблице:
|
01
02
03
04
05
06
07
08
09
10
11
|
hbase(main):026:0> scan 'AccessLog', {LIMIT=>1}ROW COLUMN+CELL\x00\x00\x00\x00\x00\x00\x00\x00 column=common:ip, timestamp=1440970360966, value=88.240.129.183\x00\x00\x00\x00\x00\x00\x00\x00 column=common:timestamp, timestamp=1440970360966, value=\x00\x00\x01\x1F\xF1\xAElP\x00\x00\x00\x00\x00\x00\x00\x00 column=common:url, timestamp=1440970360966, value=/index.php?a=1__wwv40pdxdpo&k=218978\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpMethod, timestamp=1440970360966, value=GET\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpStatusCode, timestamp=1440970360966, value=\x00\x00\x00\xC8\x00\x00\x00\x00\x00\x00\x00\x00 column=http:responseSize, timestamp=1440970360966, value=\x00\x00\x00+\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:referrer, timestamp=1440970360966, value=http://www.buldinle.com/index.php?a=1__WWV40pdxdpo&k=218978\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:userAgent, timestamp=1440970360966, value=Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)1 row(s) in 0.0810 seconds |
Чтобы записать результат в Solr, создайте ядро без схемы с именем Metrics . Чтобы сделать это легко, вы можете переименовать ядро по умолчанию для collection1 в Metrics, которое находится в папке solr-4.10.3 / example / example-schemaless / solr, и отредактировать /home/furkan/Desktop/solr-4.10.3/example/example- schemaless / solr / Metrics / core.properties as:
|
1
|
name=Metrics |
Затем запустите команду запуска для Solr:
|
1
|
furkan@kamaci:~/Desktop/solr-4.10.3/example$ java -Dsolr.solr.home=example-schemaless/solr/ -jar start.jar |
Давайте начнем пример. Читайте данные из Hbase, генерируйте метрики и записывайте результаты в Solr с помощью Spark через Gora. Вот как инициализировать входящие и исходящие хранилища данных:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public int run(String[] args) throws Exception {DataStore<Long, Pageview> inStore;DataStore<String, MetricDatum> outStore;Configuration hadoopConf = new Configuration();if (args.length > 0) {String dataStoreClass = args[0];inStore = DataStoreFactory.getDataStore(dataStoreClass, Long.class, Pageview.class, hadoopConf);if (args.length > 1) {dataStoreClass = args[1];}outStore = DataStoreFactory.getDataStore(dataStoreClass, String.class, MetricDatum.class, hadoopConf);} else {inStore = DataStoreFactory.getDataStore(Long.class, Pageview.class, hadoopConf);outStore = DataStoreFactory.getDataStore(String.class, MetricDatum.class, hadoopConf);}...} |
Передайте классы ключей и значений хранилища входных данных и создайте экземпляр GoraSparkEngine :
|
1
2
|
GoraSparkEngine<Long, Pageview> goraSparkEngine = new GoraSparkEngine<>(Long.class,Pageview.class); |
Создайте JavaSparkContext. Зарегистрируйте класс значений хранилища входных данных как класс Kryo:
|
1
2
3
4
5
6
|
SparkConf sparkConf = new SparkConf().setAppName("Gora Spark Integration Application").setMaster("local");Class[] c = new Class[1];c[0] = inStore.getPersistentClass();sparkConf.registerKryoClasses(c);JavaSparkContext sc = new JavaSparkContext(sparkConf); |
Вы можете получить JavaPairRDD из хранилища входных данных:
|
1
|
JavaPairRDD<Long, Pageview> goraRDD = goraSparkEngine.initialize(sc, inStore); |
Когда вы получите его, вы можете работать над ним так же, как если бы вы писали код для Spark! Например:
|
1
2
|
long count = goraRDD.count();System.out.println("Total Log Count: " + count); |
Вот мои функции для отображения и сокращения фаз для этого примера:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
/** The number of milliseconds in a day */private static final long DAY_MILIS = 1000 * 60 * 60 * 24;/*** map function used in calculation*/private static Function<Pageview, Tuple2<Tuple2<String, Long>, Long>> mapFunc = new Function<Pageview, Tuple2<Tuple2<String, Long>, Long>>() {@Overridepublic Tuple2<Tuple2<String, Long>, Long> call(Pageview pageview)throws Exception {String url = pageview.getUrl().toString();Long day = getDay(pageview.getTimestamp());Tuple2<String, Long> keyTuple = new Tuple2<>(url, day);return new Tuple2<>(keyTuple, 1L);}}; |
|
1
2
3
4
5
6
7
8
9
|
/*** reduce function used in calculation*/private static Function2<Long, Long, Long> redFunc = new Function2<Long, Long, Long>() {@Overridepublic Long call(Long aLong, Long aLong2) throws Exception {return aLong + aLong2;}}; |
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
/*** metric function used after map phase*/private static PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum> metricFunc = new PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum>() {@Overridepublic Tuple2<String, MetricDatum> call(Tuple2<Tuple2<String, Long>, Long> tuple2LongTuple2) throws Exception {String dimension = tuple2LongTuple2._1()._1();long timestamp = tuple2LongTuple2._1()._2();MetricDatum metricDatum = new MetricDatum();metricDatum.setMetricDimension(dimension);metricDatum.setTimestamp(timestamp);String key = metricDatum.getMetricDimension().toString();key += "_" + Long.toString(timestamp);metricDatum.setMetric(tuple2LongTuple2._2());return new Tuple2<>(key, metricDatum);}}; |
|
1
2
3
4
5
6
7
|
/*** Rolls up the given timestamp to the day cardinality, so that data can be* aggregated daily*/private static long getDay(long timeStamp) {return (timeStamp / DAY_MILIS) * DAY_MILIS;} |
Вот как запустить map и сократить функции на существующем JavaPairRDD :
|
1
2
3
4
|
JavaRDD<Tuple2<Tuple2<String, Long>, Long>> mappedGoraRdd = goraRDD.values().map(mapFunc);JavaPairRDD<String, MetricDatum> reducedGoraRdd = JavaPairRDD.fromJavaRDD(mappedGoraRdd).reduceByKey(redFunc).mapToPair(metricFunc); |
Если вы хотите сохранить результат в хранилище выходных данных (в нашем примере это Solr), вы должны сделать это следующим образом:
|
1
2
|
Configuration sparkHadoopConf = goraSparkEngine.generateOutputConf(outStore);reducedGoraRdd.saveAsNewAPIHadoopDataset(sparkHadoopConf); |
Вот и все! Проверьте Solr, чтобы увидеть результаты:
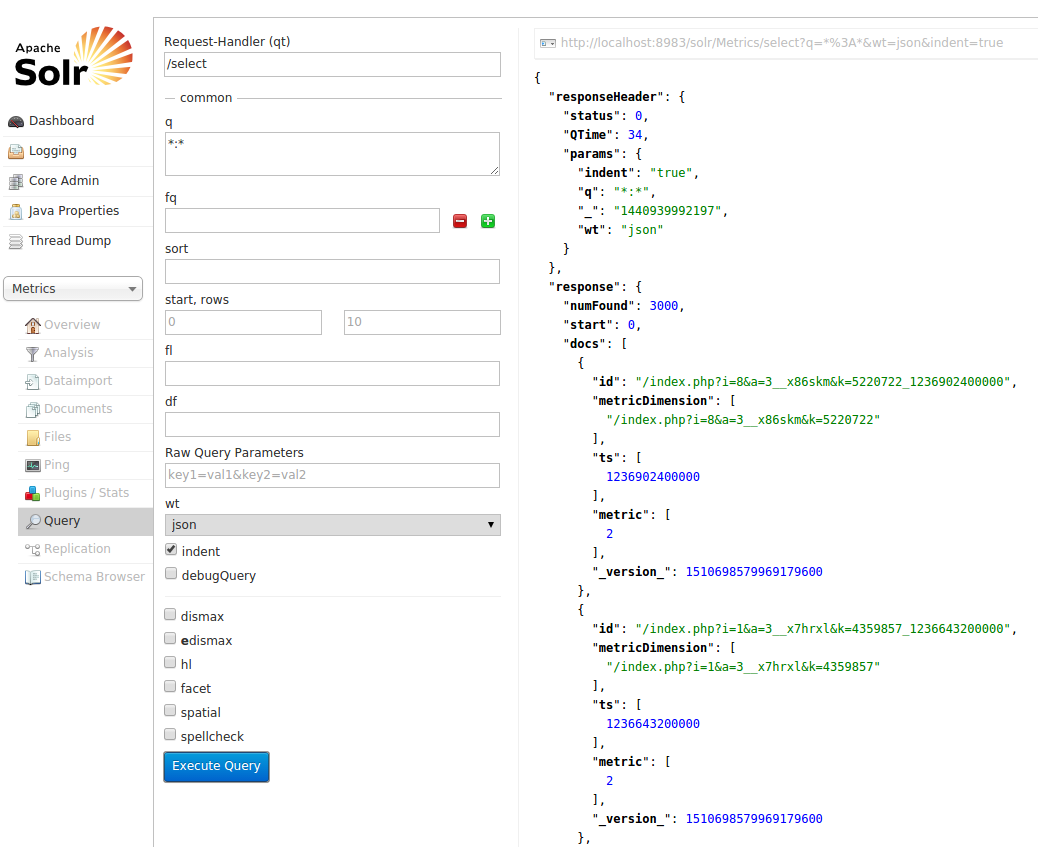
Вы можете видеть, что можно читать данные из хранилища данных (например, Hbase), запускать на нем коды Spark (отображать / уменьшать) и записывать результаты в то же или другое хранилище данных (например, Solr). GoraSparkEngine дает возможность Spark Backend Apache Gora, и я думаю, что это сделает Gora намного более мощным.
| Ссылка: | Spark Backend для Apache Gora от нашего партнера JCG Фуркана Камачи в блоге FURKAN KAMACI . |