Вступление
Это вторая часть нашего учебника временных рядов MongoDB, и этот пост будет посвящен настройке производительности. В моем предыдущем посте я познакомил вас с требованиями к нашему виртуальному проекту.
Короче говоря, у нас есть 50 миллионов временных событий, охватывающих период с 1 января 2012 года по 1 января 2013 года, со следующей структурой:
|
1
2
3
4
5
|
{ "_id" : ObjectId("52cb898bed4bd6c24ae06a9e"), "created_on" : ISODate("2012-11-02T01:23:54.010Z") "value" : 0.19186609564349055} |
Мы хотели бы объединить минимальное, максимальное и среднее значение, а также количество записей для следующих дискретных временных выборок:
- все секунды в минуту
- все минуты в часе
- все часы дня
Вот как выглядит наш базовый тестовый скрипт:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
var testFromDates = [ new Date(Date.UTC(2012, 5, 10, 11, 25, 59)), new Date(Date.UTC(2012, 7, 23, 2, 15, 07)), new Date(Date.UTC(2012, 9, 25, 7, 18, 46)), new Date(Date.UTC(2012, 1, 27, 18, 45, 23)), new Date(Date.UTC(2012, 11, 12, 14, 59, 13))];function testFromDatesAggregation(matchDeltaMillis, groupDeltaMillis, type, enablePrintResult) { var aggregationTotalDuration = 0; var aggregationAndFetchTotalDuration = 0; testFromDates.forEach(function(testFromDate) { var timeInterval = calibrateTimeInterval(testFromDate, matchDeltaMillis); var fromDate = timeInterval.fromDate; var toDate = timeInterval.toDate; var duration = aggregateData(fromDate, toDate, groupDeltaMillis, enablePrintResult); aggregationTotalDuration += duration.aggregationDuration; aggregationAndFetchTotalDuration += duration.aggregationAndFetchDuration; }); print(type + " aggregation took:" + aggregationTotalDuration/testFromDates.length + "s"); if(enablePrintResult) { print(type + " aggregation and fetch took:" + aggregationAndFetchTotalDuration/testFromDates.length + "s"); }} |
И вот как мы собираемся протестировать наши три варианта использования:
|
1
2
3
|
testFromDatesAggregation(ONE_MINUTE_MILLIS, ONE_SECOND_MILLIS, 'One minute seconds');testFromDatesAggregation(ONE_HOUR_MILLIS, ONE_MINUTE_MILLIS, 'One hour minutes');testFromDatesAggregation(ONE_DAY_MILLIS, ONE_HOUR_MILLIS, 'One year days'); |
Мы используем пять стартовых временных меток, и они используются для расчета текущего интервала времени тестирования по заданной временной детализации.
Первая отметка времени (например, T1) — Вс 10 июня 2012 14:25:59 GMT + 0300 (GTB Daylight Time) и связанные интервалы времени при тестировании:
- все секунды в минуту:
[Вс 10 июня 2012 14:25:00 GMT + 0300 (по Гринвичу летнее время)
, Вс 10 июня 2012 14:26:00 GMT + 0300 (по Гринвичу летнее время)) - все минуты в часе:
[Вс 10 июня 2012 14:00:00 по Гринвичу + 0300 (по Гринвичскому времени)
, Вс 10 июня 2012 15:00:00 по Гринвичу + 0300 (по Гринвичу летнее время)) - все часы дня:
[Вс 10 июня 2012 03:00:00 GMT + 0300 (по Гринвичу летнее время)
, Понедельник, 11 июня 2012 г., 03:00:00 по Гринвичу + 0300 (по Гринвичскому времени)
Холодное тестирование базы данных
Первые тесты будут выполняться на только что запущенном экземпляре MongoDB. Таким образом, между каждым тестом мы собираемся перезапустить базу данных, чтобы никакой индекс не загружался предварительно.
| Тип | секунд в минуту | минут в час | часов в день |
|---|---|---|---|
| T1 | 0.02s | 0.097s | 1.771s |
| T2 | 0,01 с | 0.089s | 1.366s |
| T3 | 0.02s | 0.089s | 1.216s |
| T4 | 0,01 с | 0.084s | 1.135s |
| T4 | 0.02s | 0.082s | 1.078s |
| Средний | 0.016s | 0.088s | 1.3132s |
Мы собираемся использовать эти результаты в качестве справочного материала для следующих методов оптимизации, которые я собираюсь представить вам.
Теплое тестирование базы данных
Индексы и данные прогрева являются распространенным методом, который используется как для систем управления базами данных SQL, так и для NoSQL. MongoDB предлагает сенсорную команду для этой цели. Но это не волшебная палочка, вы не используете ее вслепую в надежде оставить позади все проблемы с производительностью. Неправильное использование и производительность вашей базы данных резко упадет, поэтому убедитесь, что вы понимаете свои данные и их использование
Команда touch позволяет нам указать, что мы хотим предварительно загрузить:
- данные
- индексы
- и данные и индексы
Нам нужно проанализировать размер наших данных и то, как мы собираемся их запрашивать, чтобы получить максимальную выгоду от предварительной загрузки данных.
Размер данных
MongoDB полностью оборудован для анализа ваших данных. Гнездо, мы собираемся проанализировать нашу коллекцию событий времени, используя следующие команды:
|
1
2
3
4
5
6
|
> db.randomData.dataSize()3200000032> db.randomData.totalIndexSize()2717890448> db.randomData.totalSize()7133702032 |
Размер данных составляет около 3 ГБ, а общий размер — почти 7 ГБ. Если я решу предварительно загрузить все данные и индексы, я достигну предела 8 ГБ ОЗУ текущей рабочей станции, на которой я запускаю тесты. Это приведет к обмену, и производительность снизится.
Делать больше вреда, чем пользы
Чтобы повторить этот сценарий, я собираюсь перезапустить сервер MongoDB и выполнить следующую команду:
|
1
|
db.runCommand({ touch: "randomData", data: true, index: true }); |
Я включил эту команду в файл сценария, чтобы увидеть, сколько нужно для загрузки всех данных в первый раз.
|
1
2
3
4
|
D:\wrk\vladmihalcea\vladmihalcea.wordpress.com\mongodb-facts\aggregator\timeseries>mongo random touch_index_data.jsMongoDB shell version: 2.4.6connecting to: randomTouch {data: true, index: true} took 15.897s |
Теперь давайте снова запустим наши тесты и посмотрим, что мы получим в этот раз:
| Тип | секунд в минуту | минут в час | часов в день |
|---|---|---|---|
| T1 | 0.016s | 0.359s | 5.694s |
| T2 | 0 | 0.343s | 5.336s |
| T3 | 0.015s | 0.375s | 5.179s |
| T4 | 0,01 с | 0.359s | 5.351s |
| T4 | 0.016s | 0.343s | 5.366s |
| Средний | 0.009s | 0.355s | 5.385s |
Производительность резко упала, и я хотел включить этот вариант использования, чтобы вы поняли, что оптимизация — это серьезный бизнес. Вы действительно должны понимать, что происходит, иначе вы можете принести больше вреда, чем пользы.
Это снимок использования памяти для этого конкретного случая использования:
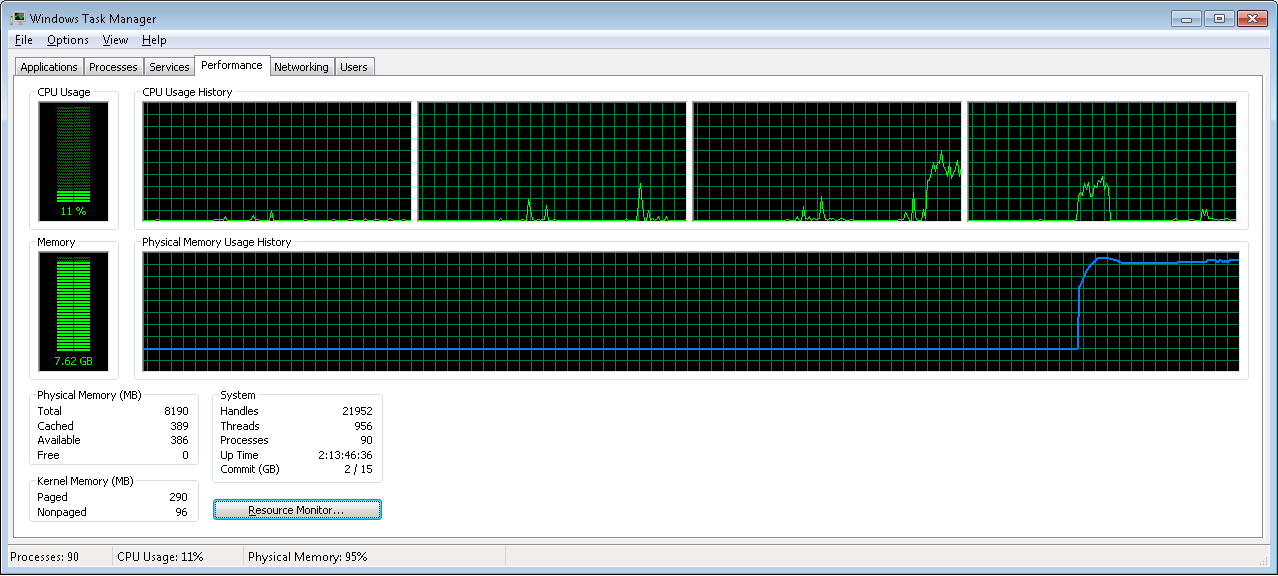
Чтобы узнать больше об этой теме, я рекомендую потратить некоторое время на чтение внутренней работы хранилища MongoDB .
Только предварительная загрузка данных
Как я уже говорил ранее, вам нужно знать обе доступные методы оптимизации в зависимости от вашего конкретного использования данных. В нашем проекте, как я объяснил в моем предыдущем посте , мы используем индекс только во время фазы матча. Во время выборки данных мы также загружаем значения, которые не индексируются. Поскольку размер данных полностью умещается в ОЗУ, мы можем выбрать только предварительную загрузку данных, оставляя индексы в стороне.
Это хороший вызов, учитывая наши текущие индексы коллекции:
|
1
2
3
4
|
"indexSizes" : { "_id_" : 1460021024, "created_on_1" : 1257869424} |
Индекс _id нам вообще не нужен, и для нашего конкретного варианта использования его загрузка фактически снижает производительность. Итак, на этот раз мы загружаем только данные.
|
1
|
db.runCommand({ touch: "randomData", data: true, index: false }); |
|
1
2
3
4
|
D:\wrk\vladmihalcea\vladmihalcea.wordpress.com\mongodb-facts\aggregator\timeseries>mongo random touch_data.jMongoDB shell version: 2.4.6connecting to: randomTouch {data: true} took 14.025s |
Повторный запуск всех тестов дает следующие результаты:
| Тип | секунд в минуту | минут в час | часов в день |
|---|---|---|---|
| T1 | 0 | 0.047s | 1.014s |
| T2 | 0 | 0.047s | 0.968s |
| T3 | 0.016s | 0.047s | 1.045s |
| T4 | 0 | 0.047s | 0.983s |
| T4 | 0 | 0.046s | 0.951s |
| Средний | 0.003s | 0.046s | 0.992s |
Это лучше, поскольку мы видим улучшения для всех трех запросов с временным интервалом. Но это не лучшее, что мы можем получить, поскольку мы можем улучшить его еще больше.
Мы можем предварительно загрузить весь рабочий набор в фоновом процессе, и это определенно должно улучшить все наши агрегаты.
Предварительная загрузка рабочего набора
Для этого я написал следующий скрипт:
|
1
2
3
4
5
6
|
load(pwd() + "/../../util/date_util.js");load(pwd() + "/aggregate_base_report.js");var minDate = new Date(Date.UTC(2012, 0, 1, 0, 0, 0, 0));var maxDate = new Date(Date.UTC(2013, 0, 1, 0, 0, 0, 0));var one_year_millis = (maxDate.getTime() - minDate.getTime());aggregateData(minDate, maxDate, ONE_DAY_MILLIS); |
Это будет собирать данные за год и объединять их для каждого дня года:
|
1
2
3
4
5
6
|
D:\wrk\vladmihalcea\vladmihalcea.wordpress.com\mongodb-facts\aggregator\timeseries>mongo random aggregate_year_report.jsMongoDB shell version: 2.4.6connecting to: randomAggregating from Sun Jan 01 2012 02:00:00 GMT+0200 (GTB Standard Time) to Tue Jan 01 2013 02:00:00 GMT+0200 (GTB Standard Time)Aggregation took:299.666sFetched :366 documents. |
Повторный запуск всех тестов дает наилучшие результаты:
| Тип | секунд в минуту | минут в час | часов в день |
|---|---|---|---|
| T1 | 0 | 0.032s | 0.905s |
| T2 | 0 | 0.046s | 0.858s |
| T3 | 0 | 0.047s | 0.952s |
| T4 | 0 | 0.031s | 0.873s |
| T4 | 0 | 0.047s | 0.858s |
| Средний | 0 | 0.040s | 0.889s |
Давайте проверим наш текущий объем памяти рабочего набора .
|
1
2
3
4
5
6
7
8
|
db.serverStatus( { workingSet: 1 } );..."workingSet" : { "note" : "thisIsAnEstimate", "pagesInMemory" : 1130387, "computationTimeMicros" : 253497, "overSeconds" : 723} |
Это приблизительная оценка, и каждая страница памяти имеет размер около 4 КБ, поэтому наш примерный рабочий набор составляет около 4 КБ * 1130387 = 4521548 КБ = 4,31 ГБ, что гарантирует, что текущий рабочий набор соответствует нашей ОЗУ.
Этот случай также подтверждается использованием памяти для предварительной загрузки рабочего набора и всех тестовых прогонов:
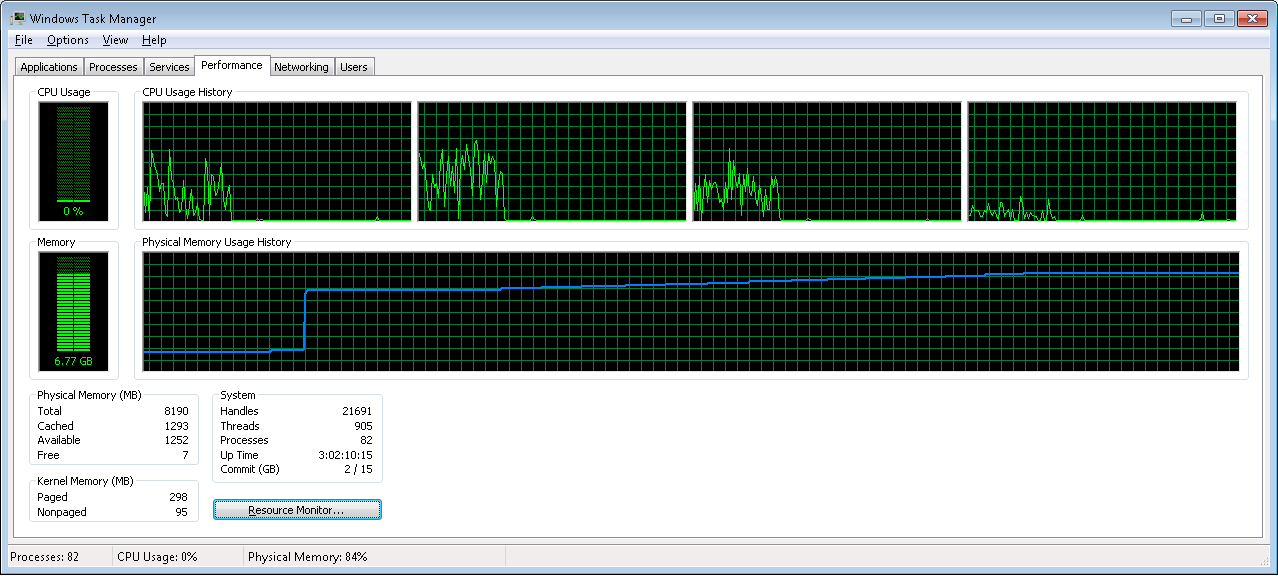
Вывод
Сравнивая текущие результаты по минутам в час с моим предыдущим, мы можем видеть улучшение уже в пять раз, но мы еще не закончили с этим. Эта простая оптимизация уменьшила разрыв между моими предыдущими результатами (0.209 с) и JOOQ Oracle (0.02 с), хотя их результат все же немного лучше.
Мы пришли к выводу, что текущая структура работает против нас для больших наборов данных. Мой следующий пост представит вам улучшенную модель сжатых данных, которая позволит нам хранить больше документов на один осколок.
- Код доступен на GitHub .