В 2011 году я запустил « 3-минутный тест: что вы знаете о производительности SQL. «Он состоит из пяти вопросов, которые следуют простому шаблону: каждый вопрос показывает пару запрос / индекс и спрашивает, демонстрирует ли он правильную индексацию или нет. До сегодняшнего дня этот тест стал одной из самых популярных функций в Use The Index, Люк, и был выполнен более 28 000 раз.
Запись
На случай, если вам стало любопытно, учтите, что эта статья является спойлером. Возможно, вы захотите пройти тест самостоятельно, прежде чем продолжить.
Хотя тест был создан для образовательных целей, мне было интересно, смогу ли я получить некоторые интересные цифры из этих 28 000 результатов. И я думаю, что мог. Однако при взгляде на эти цифры нужно помнить несколько вещей. Во-первых, викторина использует фактор неожиданности, чтобы привлечь внимание. Это означает, что три вопроса показывают случаи, которые выглядят хорошо, но это не так. Один вопрос делает это наоборот и показывает пример, который может выглядеть опасно, но это не так. Есть только один вопрос, где правильный ответ соответствует первому впечатлению. Другим эффектом, который может повлиять на значимость результатов, является отсутствие репрезентативного отбора участников. Каждый может пройти тест. Вы даже можете сделать это несколько раз и, вероятно, получите лучший результат во второй раз.Просто имейте в виду, что викторина никогда не предназначалась для научных исследований при индексации знаний в данной области. Тем не менее, я думаю, что размер набора данных все еще достаточно хорош, чтобы произвести впечатление.
Ниже я покажу две разные статистики для каждого вопроса. Во-первых, средняя скорость, с которой этот вопрос был правильно ответил. Во-вторых, как эта цифра меняется для пользователей баз данных MySQL, Oracle, PostgreSQL и SQL Server. Другими словами, он говорит, если, например, пользователи MySQL лучше осведомлены об индексации, как пользователи PostgreSQL. Спойлер: Это наоборот. Единственная причина, по которой мне повезло получить эти данные, заключается в том, что в тесте иногда используется специфический синтаксис поставщика. Например, то, что LIMIT в MySQL и PostgreSQL является TOP в SQL Server. Поэтому участники должны сначала выбрать базу данных, чтобы вопросы отображались в собственном синтаксисе этого продукта.
Вопрос 1: Функции в предложении WHERE
Является ли следующий SQL хорошей или плохой практикой с точки зрения производительности?
Поиск по всем строкам 2012 года:
CREATE INDEX tbl_idx ON tbl (date_column); SELECT text, date_column FROM tbl WHERE TO_CHAR(date_column, 'YYYY') = '2012';
Это пример, где код использует функции, специфичные для баз данных Oracle и PostgreSQL. Для MySQL вопрос использует YEAR(date_column)и для SQL Server datepart(yyyy, date_column). Конечно, я мог бы использовать EXTRACT(YEAR date_column), но я думал, что лучше использовать наиболее распространенный синтаксис.
У участников есть следующие варианты:
-
Хорошая практика. Значительного улучшения невозможно.
-
Плохая практика — возможно значительное улучшение.
The correct answer is “bad practice” because the index on date_column cannot be used when searching on something derived from date_column. If you don’t believe that, please have a look at the proof scripts or the explanations shown at the end of the test. They also contain links to the Use The Index, Luke pages explaining it in more detail.
However, if you didn’t know how functions effectively “disable” indexes, you are not alone. Only about two-thirds gave the correct answer. And as for every multiple choice test, there is a certain probably to pick the correct answer by chance. In this cases it’s a 50/50 chance — by no means negligible. I’ve marked this “guessing score” in the figure to emphasize that.

This is one of the most common problems I see in my everyday work. The same problem can also hit you with VARCHAR fields when using UPPER, TRIM or the like. Please keep in mind: whenever you are applying functions on columns in the where clause, an index on the column itself is no longer useful for this query.
Although this result is quite disappointing — I mean it’s just 17% better than guessing — it is no surprise to me. What is a surprise for me is how the result differs amongst the users of different databases.
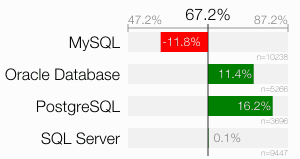
As a matter of fact, MySQL users just score 55% — almost as low as the “guessing score”. PostgreSQL users, on the other hand, get a score of 83%.
An effect that might explain this result is that MySQL doesn’t support function-based indexes while Oracle and PostgreSQL do. Function-based indexes allow you to index expressions like TO_CHAR(date_column, 'YYYY'). Although it is not the recommended solution for this case, the pure existence of this feature might make users of the Oracle and PostgreSQL database more aware of this problem. SQL Server offers a similar feature: although it cannot index expressions directly, you can create a so-called computed column on expressions, which in turn can be indexed.
Although support for function-based indexes might explain why MySQL users underperformed, it is still no excuse. The shown query/index pair is bad — no matter whether the database supports function-based indexes or not. And the major improvement is also possible without function-based indexes:
SELECT text, date_column
FROM tbl
WHERE date_column >= TO_DATE('2012-01-01', 'YYYY-MM-DD')
AND date_column < TO_DATE('2013-01-01', 'YYYY-MM-DD');
The index doesn’t need to be changed. This solution is very flexible because it supports queries for different ranges too — e.g. by week or month. This is the recommended solution.
As a curious guy, I’d love to know how many of the people who correctly answered this question were thinking of the sub-optimal solution to use a function-based index. I’d rate this solution half-correct at best.
Question 2: Indexed Top-N Queries
Is the following SQL good or bad practice from a performance perspective?
To find the most recent row:
CREATE INDEX tbl_idx ON tbl (a, date_column); SELECT id, a, date_column FROM tbl WHERE a = ? ORDER BY date_column DESC LIMIT 1;
Note that the question mark is a placeholder, because I always encourage developers to use bind parameters.
As participant, you have these two options again:
-
Good practice — There is no major improvement possible.
-
Bad practice — There is a major improvement possible.
This is the question that is supposed to look dangerous, but isn’t. Generally, it seems like people believe order by must always sort the data. This index, however, eliminates the need to sort the data entirely so that the query is basically as fast as a unique index lookup. Please find a detailed explanation of this trick here.
The result is very close to the “guessing score” which I interpret as “people don’t have a clue about it.”

This result is particularly sad because I’ve seen people building caching tables, regularly refilled by a cron jobs, to avoid queries like this. Interestingly, the cron job tends to cause performance problems because it is running in rather short intervals to make sure the cache table has fresh data. However, the right index is often the better option in the first place.
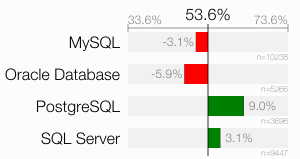
Here I have to mention that the Oracle database needs the most special syntax for this trick. Up till version 12c released in 2013, the Oracle database did not offer a handy shortcut such as LIMIT or TOP. Instead, you have to use the ROWNUM pseudo-column like this:
SELECT *
FROM (
SELECT id, date_column
FROM tbl
WHERE a = :a
ORDER BY date_column DESC
)
WHERE rownum <= 1;
The extra complexity of this query might have pushed Oracle users more heavily towards the wrong answer — actually below guessing score!
Another argument I’m getting in response to this question is that including the ID column in the index would allow an index-only scan. Although this is correct, I don’t consider not doing so a “bad practice” because the query touches only one row anyway. An index-only scan could just avoid a single table access. Obviously there are cases were you need that improvement, but in the general case I’d consider it a premature optimization. But that’s just my opinion. However, following this argument might give us an idea why PostgreSQL users got the best score (again): PostgreSQL did not have index-only scans until version 9.2, which was released in September 2012. As a result, PostgreSQL users could not fall into this trap of thinking an index-only scan can bring major improvements in this case. Undoubtedly, the term “major” is troublesome in this context.
Question 3: Index Column Order
Is the following SQL good or bad practice from a performance perspective?
Two queries, searching by a common column:
CREATE INDEX tbl_idx ON tbl (a, b); SELECT id, a, b FROM tbl WHERE a = ? AND b = ?; SELECT id, a, b FROM tbl WHERE b = ?;
The same options:
-
Good practice — There is no major improvement possible.
-
Bad practice — There is a major improvement possible.
The answer is “bad practice,” because the second query cannot use the index properly. Changing the index column order to (b, a) would, however, allow both queries to use this index in the most efficient way. You can find a full explanation here. Adding a second index on (b) would be a poor solution due to the overhead it adds for no reason. Unfortunately, I don’t know how many would have done that.
The result is disappointing, but in line with my expectations — just 12.5% above guessing score.

This is also a problem I see almost every day. People just don’t understand how multi-column indexes work.
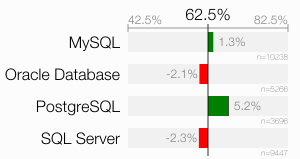
All the per-database results are pretty close together. Maybe because there is no syntactic difference or well-known database features that could have a major influence the answer. Less known features like Oracle’s SKIP SCAN could have a minor impact, of course. Generally, the index-only scan could have a influence too, but it pushes the participants to the “right” answer this time.
After all, this result might just say that users of some databases know more about indexing than others. Interestingly, PostgreSQL users get the best score for the third time.
Question 4: LIKE Searches
Is the following SQL troublesome or bulletproof from a performance perspective?
Searching within a string:
CREATE INDEX tbl_idx ON tbl (text); SELECT id, text FROM tbl WHERE text LIKE '%TERM%';
I’ve phrased the options differently this time:
-
Bulletproof: It will always run fast.
-
Troublesome: There is high risk for performance problems.
And the correct answer is “troublesome” because the LIKE pattern uses a leading wild card. Otherwise, if it would use the pattern 'TERM%', it could use the index very efficiently. Have a look at this visual explanation for details.
The results of this question are promising. Here I feel safe to say most people know that LIKE is not for full-text search.

The segregated results are also within a very narrow corridor:
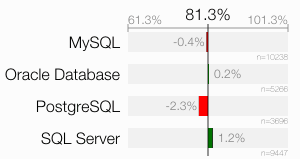
It is, however, strange that PostgreSQL users under performed at this question. A closer look at how the question is presented to PostgreSQL users might give an explanation:
CREATE INDEX tbl_idx ON tbl (text varchar_pattern_ops); SELECT id, text FROM tbl WHERE text LIKE '%TERM%';
Note the addition to the index (varchar_pattern_ops). In PostgreSQL, this special operator class is required to make the index usable for postfix wild card searches (e.g. 'TERM%'). I added this because I aimed to find out if people know about the problem of leading wild cards in LIKE expressions. Without the operator class, there are two reasons why it doesn’t work: (1) the leading wild card; (2) the missing operator class. I though that would be too obvious. Retrospectivley, I believe some participants interpreted this operator class as “magic that makes it work” and thus took the wrong answer.
Question 5a: Index-Only Scan
Question five is a little bit tricky, because PostgreSQL did not support index-only scans when the quiz was created. For that reason, there are two variants of question five: one about index-only scans for users of MySQL, Oracle and SQL Server databases. And another question about index column order for PostgresSQL users. Both results are presented here, but the segregated data is limited for obvious reasons. We start with the question about index-only scans:
How will the change affect query performance?
Current situation, selecting about hundred rows out of a million:
CREATE INDEX tab_idx ON tbl (a, date_column); SELECT date_column, count(*) FROM tbl WHERE a = 123 GROUP BY date_column;Changed query, selecting about ten rows out of a million:
SELECT date_column, count(*) FROM tbl WHERE a = 123 AND b = 42 GROUP BY date_column;
Note the added where clause in the second query.
This question is also special because it offers four options:
-
Query performance will roughly stay the same (+/- 10%)
-
Depends on the data.
-
The query will be much slower (impact >10%)
-
The query will be much faster (impact >10%)
When I created the quiz, I was well aware that 50/50 questions have a tendency to render the score meaningless. This question is a trade-off between keeping the questions easy to gasp and answer (questions 1–4) and giving a more accurate result.
To make it short, the correct answer is “the query will be much slower.” The reason is that the original query could use an index-only scan — that is, the query could be answered only using data from the index without fetching any data from the actual table. The second query, however, needs to check column B too, which is not in the index. Consequently, the database must take some extra effort to fetch the candidate rows from the table to evaluate the expression on B That is, it must fetch at least 100 rows from the table — the number of rows returned by the first query. Due to the group by there are probably more rows to fetch. A quite considerable extra effort that will make the query much slower. A more exhaustive explanation is here.
With that number of options, the overall score drops significantly to about 39% or 14% above guessing score.

Still I think saying that about 39% of participants knew the right answers is wrong. They gave the right answer, but there was still a probability of 25% that they gave the right answer without knowing it.
The segregation by database is quite boring. Conspicuously boring.
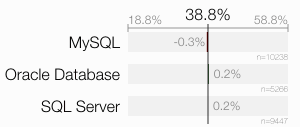
However, with four options, it is also interesting to see how people actually answered.
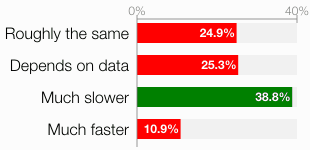
That caught me by surprise. Both options “roughly the same” and “depends on the data” got about 25% — the guessing probably. Does this mean half of the participants were guessing? As it is the last question some participants might have picked a random option just to get through. Quite possible. However, the correct option “much slower” got 38.8% at the cost of the “much faster” option, which got just 10.9%.
My intention with this question was to trap people into the “much faster” option because fetching less data should be faster — except when breaking an index-only scan. The only hypothesis I have for this result is that people might have got the idea that the obvious answer isn’t the correct one. That, however, would mean the 39% score doesn’t prove anything about the knowledge of this phenomenon in the field.
Another effect that I expected to have an impact is that “it is always depending on the data.” Of course there are edge cases where the performance impact might roughly stay the same — e.g., when all inspected rows are in the same table block. However, this is rather unlikely — just because there would be no point in adding the date_column for an index-only scan in the first place.
Question 5b: Index Column Order and Range Operators
This question is only shown to PostgreSQL users.
Is the following SQL good or bad practice from a performance perspective?
Searching for entries in state X, not older than 5 years.
CREATE INDEX tbl_idx ON tbl (date_column, state); SELECT id, date_column, state FROM tbl WHERE date_column >= CURRENT_DATE - INTERVAL '5' YEAR AND state = 'X'; (365 rows)The data distribution is as follows:
SELECT count(*) FROM tbl WHERE date_column >= CURRENT_DATE - INTERVAL '5' YEAR; count ------- 1826 SELECT count(*) FROM tbl WHERE state = 'X'; count ------- 10000
There is an index with two columns and a query that filters on both of them. One filter uses an equals operator, the other a greater than or equal operator. When using each filter individually the query returns many more rows as when combining both filters.
The options are:
-
Good practice — There is no major improvement possible.
-
Bad practice — There is a major improvement possible.
And the correct answer is “bad practice” because the column order in the index is the wrong way around. The general rule is that index columns can be used efficiently from the left hand side as long as they are used with equals operators. Further, one column can be used efficiently with a range operator. However, the first range operator effectively cuts off the index so that further columns cannot be used efficiently anymore. With efficiently I mean as an index access predicate. Please find a visualization here.
With the original index shown above, the query has to fetch 1826 entries from the index (those matching the date_column filter) and check each of them for the value of the state column. If we turn the index column order around, the database can use both filters efficiently (= as access predicate) and directly limit the index access to those 365 rows of interest.
And this is how people answered:

Wait a moment, that’s below the guessing score! It’s not just people don’t know, they believe the wrong thing. However, I must admit that the term “major” is very problematic again. When I run this example, the speed-up I get is just 70%. Not even twice as fast.
Overall Score: How Many Passed the Test?
Looking at each question individually is interesting, but doesn’t tell us how many participants managed to answer all five questions correctly, for example. The following chart has that information.
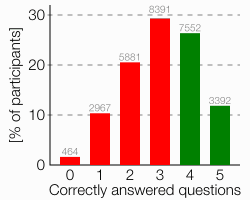
Finally, I’d like to boil this chart down to a single figure: how many participants “passed” the test?
Considering that the test has only five questions, out of which four are 50/50 questions, I think it is fair to say three correct answers isn’t enough to pass the test. Requiring five correct answers would quite obviously be asking for too much. Requiring four correct answers to “pass” the test is therefore the only sensible choice I see. Using this definition, only 38.2% passed the test. The chance to pass the test by guessing is still 12.5%.
If you like this article and want to learn about proper indexing, SQL Performance Explained is for you.
Links
Raw results (.txt.gz, 1.1 MB, explanations included)
To verify my analysis and/or draw your own conclusions. Also includes data that I haven’t used. Especially timestamps that might allow to filter for guessing (e.g. question answered in less than X seconds).
Indexes: The neglected performance all-rounder
Analysis why developers know very little about SQL indexing.