Мы очень рады объявить о серии гостевых постов в блоге jOOQ Мануэля Бернхардта . В этой серии блогов Мануэль расскажет о мотивах так называемых реактивных технологий и после представления концепций фьючерсов и актеров использует их для доступа к реляционной базе данных в сочетании с jOOQ.
 Мануэль Бернхардт (Manuel Bernhardt ) — независимый консультант по программному обеспечению со страстью к созданию веб-систем, как внутренних, так и внешних. Он является автором «Реактивных веб-приложений» (Мэннинг) и начал работать со Scala, Akka и Play Framework в 2010 году, проведя много времени с Java. Он живет в Вене, где он является соорганизатором местной группы пользователей Scala . Он с энтузиазмом относится к технологиям, основанным на Scala, и к активному сообществу, и ищет способы распространения их использования в отрасли. С 6 лет он также занимается подводным плаванием и не может привыкнуть к отсутствию моря в Австрии.
Мануэль Бернхардт (Manuel Bernhardt ) — независимый консультант по программному обеспечению со страстью к созданию веб-систем, как внутренних, так и внешних. Он является автором «Реактивных веб-приложений» (Мэннинг) и начал работать со Scala, Akka и Play Framework в 2010 году, проведя много времени с Java. Он живет в Вене, где он является соорганизатором местной группы пользователей Scala . Он с энтузиазмом относится к технологиям, основанным на Scala, и к активному сообществу, и ищет способы распространения их использования в отрасли. С 6 лет он также занимается подводным плаванием и не может привыкнуть к отсутствию моря в Австрии.
Эта серия разделена на три части, которые мы опубликуем в следующем месяце:
- Часть 1. Введение в Futures, «Почему асинхронно», настройка пула соединений
- Часть 2: Введение в актеров
- Часть 3: Использование jOOQ со Scala, Futures и Actors
Реактивная?
Концепция реактивных приложений становится все более популярной в наши дни, и есть вероятность, что вы уже слышали об этом где-то в Интернете. Если нет, то вы можете прочитать Reactive Manifesto или, возможно, мы согласимся со следующим простым его резюме: в двух словах, Reactive Applications — это приложения, которые:
- оптимально использовать вычислительные ресурсы (с точки зрения использования процессора и памяти), используя методы асинхронного программирования
- знать, как справляться с неудачами, грациозно деградируя, а не просто рушиться и становясь недоступным для своих пользователей
- может адаптироваться к интенсивным рабочим нагрузкам, масштабируя на нескольких машинах / узлах по мере увеличения нагрузки (и уменьшая обратно)
Реактивные Приложения не существуют просто в диком, нетронутом зеленом поле. В какой-то момент им нужно будет хранить данные и получать к ним доступ, чтобы сделать что-то значимое, и есть вероятность, что данные окажутся в реляционной базе данных.
Задержка и доступ к базе данных
Когда приложение чаще обращается к базе данных, сервер базы данных не будет работать на том же сервере, что и приложение. Если вам не повезло, возможно, даже сервер (или набор серверов), на котором размещено приложение, находится в другом центре обработки данных, чем сервер базы данных. Вот что это означает с точки зрения задержки :
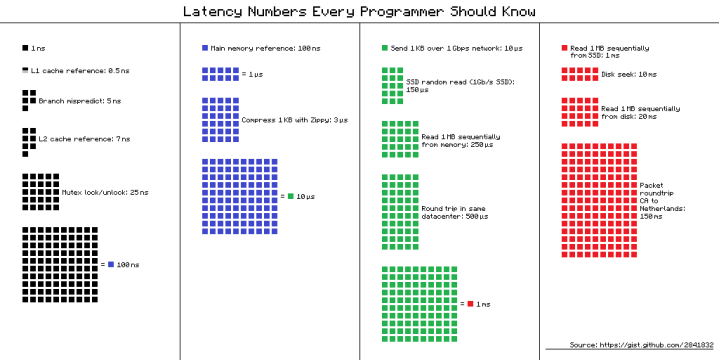
Скажем, у вас есть приложение, которое выполняет простой запрос SELECT на своей главной странице (давайте не будем спорить, является ли это хорошей идеей здесь). Если ваши серверы приложений и баз данных находятся в одном и том же центре обработки данных, вы видите задержку порядка 500 мкс (в зависимости от того, сколько данных возвращается). Теперь сравните это со всем, что ваш процессор мог сделать за это время (все эти зеленые и черные квадраты на рисунке выше), и помните об этом — мы вернемся к этому через минуту.
Стоимость ниток
Предположим, что вы выполняете запрос страницы приветствия синхронно (именно это делает JDBC) и ждете, пока результат вернется из базы данных. В течение всего этого времени вы будете монополизировать поток, который ожидает возвращения результата. Поток Java, который просто существует (вообще ничего не делая), может занять до 1 МБ динамической памяти, поэтому, если вы используете многопоточный сервер, который будет выделять один поток на пользователя (я смотрю на вас, Tomcat), то это в ваших же интересах иметь достаточное количество памяти, доступной для вашего приложения, чтобы оно все еще работало, когда оно включено в Hacker News (1 МБ / параллельный пользователь).
Реактивные приложения, такие как созданные на платформе Play Framework, используют сервер, который следует модели четного сервера : вместо того, чтобы следовать мантре «один пользователь, один поток», он будет обрабатывать запросы как набор событий (доступ к базе данных будет одно из этих событий) и выполните его через цикл событий:
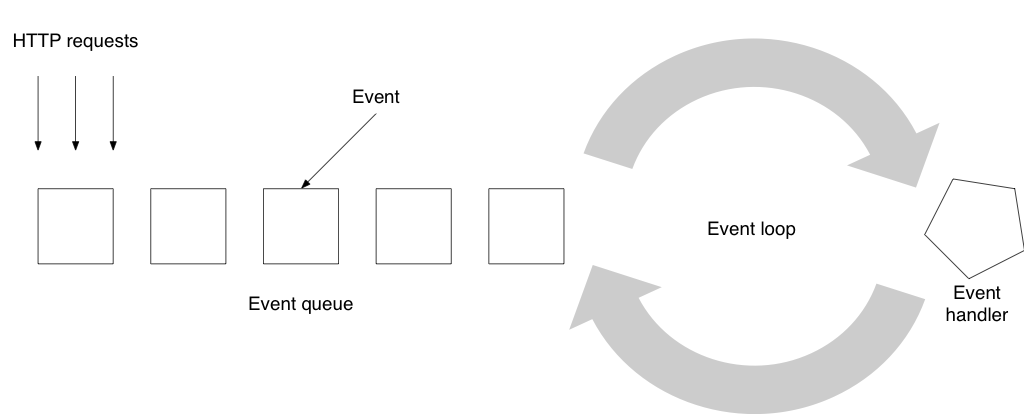
Такой сервер не будет использовать много потоков. Например, конфигурация Play Framework по умолчанию заключается в создании одного потока на ядро ЦП с максимум 24 потоками в пуле. И все же этот тип серверной модели может обрабатывать гораздо больше параллельных запросов, чем многопоточная модель с тем же аппаратным обеспечением. Хитрость, как выясняется, заключается в том, чтобы передать поток другим событиям, когда задача должна сделать некоторое ожидание — или другими словами: программировать в асинхронном режиме.
Болезненное асинхронное программирование
Асинхронное программирование не является чем-то новым, и парадигмы программирования для его решения существуют с 70-х годов и с тех пор постепенно развивались. И все же асинхронное программирование — это не обязательно то, что возвращает счастливые воспоминания большинству разработчиков. Давайте рассмотрим несколько типичных инструментов и их недостатки.
Callbacks
Некоторые языки (я смотрю на вас, Javascript) застряли в 70-х годах с обратными вызовами как их единственным инструментом для асинхронного программирования до недавнего времени (ECMAScript 6 представил Promises). Это также известно как программирование рождественской елки :

Хо Хо Хо .
Потоки
Как разработчик Java, слово асинхронный может не обязательно иметь очень положительное значение и часто ассоциируется с печально известным synchronized ключевым словом:
Работать с потоками в Java сложно, особенно при использовании изменяемого состояния — гораздо удобнее позволить базовому серверу приложений абстрагировать все асинхронные компоненты и не беспокоиться об этом, верно? К сожалению, как мы только что видели, это довольно дорого с точки зрения производительности.
И я имею в виду, просто посмотрите на эту трассировку стека:
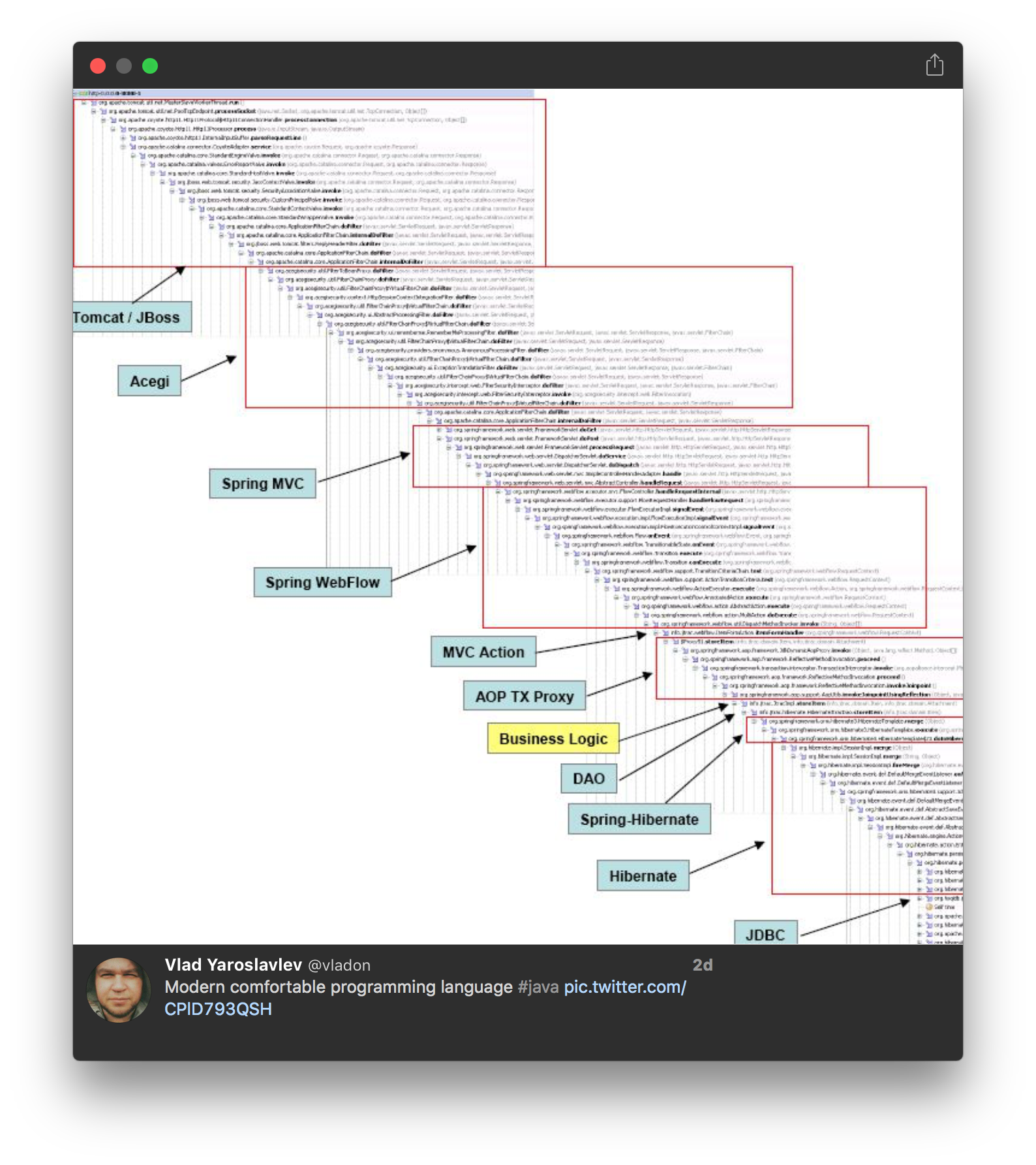
С одной стороны, многопоточные серверы для асинхронного программирования — это то же самое, что Hibernate для SQL — неплотная абстракция, которая в долгосрочной перспективе дорого обойдется. И как только вы осознаете это, часто становится слишком поздно, и вы попадаете в ловушку своей абстракции, всеми силами борясь с ней, чтобы повысить производительность. В то время как для доступа к базе данных относительно легко отказаться от абстракции (просто используйте простой SQL или, что еще лучше, jOOQ ), для асинхронного программирования лучшие инструменты только начинают набирать популярность.
Давайте обратимся к модели программирования, которая берет свое начало в функциональном программировании: Futures.
Фьючерсы: SQL асинхронного программирования
Будущее, которое можно найти в Scala, использует методы функционального программирования, которые использовались десятилетиями, чтобы снова сделать асинхронное программирование приятным.
Будущие основы
scala.concurrent.Future[T] можно рассматривать как блок, который в конечном итоге будет содержать значение типа T случае успеха. Если это не удастся, Throwable в начале сбоя будет сохранен. Говорят, что будущее успешно выполнено, если ожидаемое вычисление дало результат или не удалось, если во время вычисления произошла ошибка. В любом случае, как только Будущее завершено, оно считается завершенным .
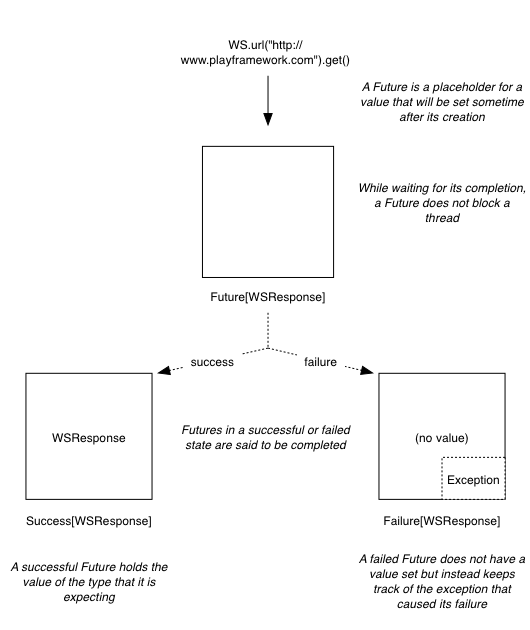
Как только Future объявлен, он начнет работать, что означает, что вычисление, которое он пытается выполнить, будет выполняться асинхронно. Например, мы можем использовать библиотеку WS Play Framework для выполнения запроса GET к веб-сайту Play Framework:
|
1
2
|
val response: Future[WSResponse] = |
Этот звонок немедленно вернется и позволит нам продолжать делать другие вещи. В какой-то момент в будущем вызов мог быть выполнен, и в этом случае мы могли бы получить доступ к результату, чтобы что-то с ним сделать. В отличие от Java java.util.concurrent.Future<V> который позволяет проверять, выполнено ли Future или заблокировано при получении его с помощью метода get() , Scuture’s Future позволяет указать, что делать с результатом выполнения.
Преобразование фьючерсов
Управлять содержимым коробки также легко, и нам не нужно ждать, пока результат будет доступен, чтобы сделать это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
val response: Future[WSResponse] =val siteOnline: Future[Boolean] = response.map { r => r.status == 200 }siteOnline.foreach { isOnline => if(isOnline) { println("The Play site is up") } else { println("The Play site is down") }} |
В этом примере мы превращаем наше Future[WSResponse] в Future[Boolean] , проверяя состояние ответа. Важно понимать, что этот код не будет блокироваться в любой момент: только когда ответ будет доступен, поток будет доступен для обработки ответа и выполнения кода внутри функции map .
Восстановление неудачных фьючерсов
Восстановление после сбоя также достаточно удобно:
|
1
2
3
4
5
6
7
8
9
|
val response: Future[WSResponse] =val siteAvailable: Future[Option[Boolean]] = response.map { r => Some(r.status == 200) } recover { case ce: java.net.ConnectException => None } |
В самом конце Будущего мы вызываем метод recover который будет иметь дело с определенным типом исключения и ограничит ущерб. В этом примере мы только обрабатываем неудачный случай java.net.ConnectException , возвращая значение None .
Составление фьючерсов
Отличительной чертой Futures является их сочетаемость. Очень типичный вариант использования при создании рабочих процессов асинхронного программирования — объединение результатов нескольких параллельных операций. Фьючерсы (и Scala) делают это довольно легко:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
def siteAvailable(url: String): Future[Boolean] = WS.url(url).get().map { r => r.status == 200}val playSiteAvailable =val playGithubAvailable =val allSitesAvailable: Future[Boolean] = for { siteAvailable <- playSiteAvailable githubAvailable <- playGithubAvailable} yield (siteAvailable && githubAvailable) |
allSitesAvailable Future allSitesAvailable с использованием для понимания, которое будет ждать, пока оба Futures не будут завершены. Два Futures playSiteAvailable и playGithubAvailable начнут работать, как только они будут объявлены, и для понимания они составят их вместе. И если один из этих Фьючерсов потерпит неудачу, результирующий Future[Boolean] получится напрямую (без ожидания завершения другого Future).
Это первая часть этой серии. В следующем посте мы рассмотрим другой инструмент для реактивного программирования, а затем, наконец, как использовать эти инструменты в комбинации для доступа к реляционной базе данных в реактивном режиме.
Читать дальше
Следите за обновлениями, так как мы вскоре опубликуем части 2 и 3 как часть этой серии:
- Часть 1. Введение в Futures, «Почему асинхронно», настройка пула соединений
- Часть 2: Введение в актеров
- Часть 3: Использование jOOQ со Scala, Futures и Actors
| Ссылка: | Реактивный доступ к базе данных — часть 1. Почему «Async» от нашего партнера по JCG Лукаса Эдера из блога JAVA, SQL и JOOQ . |