Около 3 месяцев назад я опубликовал одну статью, в которой объясняется наш подход и подход к созданию облачного приложения . Из этой статьи я постепенно поделюсь нашим практическим дизайном, чтобы решить эту проблему.
Как упоминалось ранее, нашей конечной целью является создание приложения для анализа больших данных Saas , которое будет развернуто на серверах AWS . Для достижения этой цели нам необходимо создать распределенные системы сканирования, индексации и обучения. 
В этой статье основное внимание уделяется построению распределенной системы сканирования. Необычное название для этой системы будет Black Widow .
Требования
Как обычно, начнем с бизнес-требований к системе. Наша цель — создать масштабируемую систему сканирования, которая может быть развернута в облаке. Система должна функционировать в ненадежной сети с высокой задержкой и может автоматически восстанавливаться после частичного аппаратного или сетевого сбоя.
В первом выпуске система может сканировать из 3 видов источников: Datasift , Twitter API и Rss. Данные, отсканированные назад, называются
Комментарий Сканеры Rss предполагают читать общедоступные источники, такие как веб-сайт или блог. Это бесплатно. DataSift и Twitter предоставляют собственные API для доступа к своему потоковому сервису. Datasift выставляет счет своим пользователям по количеству комментариев и сложности CSLD (язык определения потоков курирования, их собственный язык запросов). Twitter, с другой стороны, предлагает бесплатную потоковую передачу Twitter Sampler.
Чтобы контролировать затраты, нам необходимо внедрить механизм ограничения количества комментариев, просматриваемых из коммерческого источника, такого как Datasift. Поскольку Datasift предоставил комментарий в Твиттере, можно получить один комментарий из разных источников. На данный момент мы не пытались устранить и принять это как дублирование данных. Однако эту проблему можно устранить вручную с помощью конфигурации пользователя (избегайте одновременного выбора Twitter и Datasift Twitter).
Для дальнейшего расширения система должна иметь возможность связать связанные комментарии с беседой.
Пища для размышлений
Централизованная архитектура
Наша первая мысль при получении требования — построить сканирование на узлах, которое мы назвали Spawn, и разрешить хаб, который мы назвали Black Widow, управлять совместной работой между узлами. Эта идея была быстро принята членами команды, поскольку она позволяет системе хорошо масштабироваться, когда концентратор выполняет ограниченную работу.
Как и любая другая централизованная система, «Черная вдова» страдает единственной проблемой точки отказа . Чтобы облегчить эту проблему, мы позволяем узлу функционировать независимо в течение короткого периода времени после потери соединения с Black Widow. Это даст команде поддержки передышку для запуска резервного сервера.
Еще одна «горловина» системы — хранение данных. Что касается объема просматриваемых данных (легко достигающих нескольких тысяч записей в секунду), то NoSQL является очевидным выбором для хранения просканированных комментариев. У нас есть опыт работы с Lucene и MongoDB . Однако после исследований и небольших экспериментов мы выбрали Cassandra в качестве базы данных NoSQL .
С учетом этих нескольких мыслей мы визуализируем распределенную систему сканирования, которая будет построена по этому прототипу:
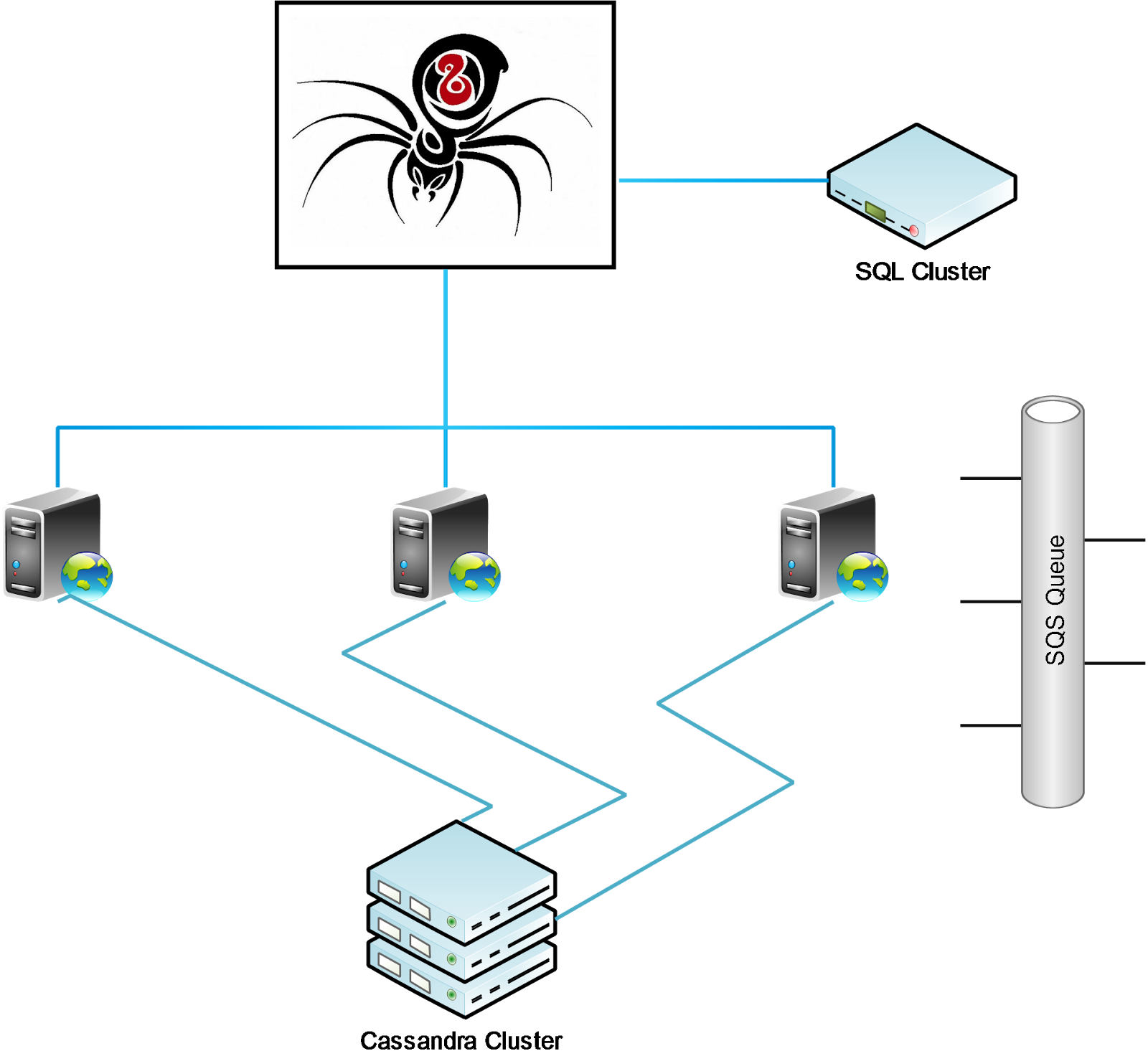
На приведенной выше схеме Black Widow или концентратор — единственный сервер, имеющий доступ к системе баз данных SQL. Здесь мы храним конфигурацию для сканирования. Следовательно, все Спавны или сканирующие узлы полностью не сохраняют состояния. Он просто просыпается, регистрируется в Black Widow и выполняет назначенные задания. После получения комментариев Spawn сохраняет его в кластере Cassandra, а также отправляет его в некоторые очереди для дальнейшей обработки.
Мозговой штурм возможных проблем
Чтобы объяснить дизайн нетехническим людям, нам нравится связывать бизнес-требования с аналогичной проблемой в реальной жизни, чтобы ее было легче понять. Подобной проблемой, которую мы выберем, будет сотрудничество усилий волонтеров.
Представьте, что нам нужно много подготовиться к предстоящему олимпийскому чемпионату и принять решение о наборе добровольцев по всему миру для помощи. Мы не знаем волонтеров, но волонтеры знают нашу электронную почту, поэтому они могут связаться с нами для регистрации. Только тогда мы узнаем их электронные письма и можем отправлять им задания по электронной почте. Мы не хотели бы посылать одно задание двум добровольцам или оставляли некоторые задания без присмотра. Мы хотим распределить задачи равномерно, чтобы добровольцы не страдали слишком сильно.
Из-за стоимости мы не будем связываться с ними по мобильному телефону. Однако, поскольку электронная почта менее надежна, при отправке задач волонтерам мы запрашиваем подтверждение. Задание считается назначенным только тогда, когда волонтер ответил с подтверждением.
В приведенном выше примере добровольцы представляют узлы Spawn, а сообщения электронной почты — ненадежную сеть с высокой задержкой. Вот некоторые проблемы, которые нам нужно решить:
1 / Отказ узла
Для этой проблемы лучше всего регулярно проверять. Если волонтер перестанет отвечать на обычную электронную почту проверки выполнения, задание следует переназначить кому-либо еще.
2 / Оптимизация назначения задач
Некоторые задачи связаны между собой. Поэтому назначение связанных задач одному и тому же человеку может помочь сократить общие усилия. Это также происходит с нашим сканированием, потому что в некоторых конфигурациях сканирования есть похожие условия поиска, объединение их в группы для совместного использования потокового канала поможет уменьшить итоговый счет.
Еще одной проблемой является справедливость или возможность равномерно распределять количество работ среди волонтеров. Самая простая стратегия, которую мы можем придумать, это Round Robin, но с небольшим изменением, запоминая ранние задания. Поэтому, если задача очень похожа на задачу, которую мы назначили ранее, ее можно пропустить из выбора «Круглый Робин» и напрямую назначить тому же добровольцу.
3 / хаб не работает
Если по каким-либо причинам наш почтовый сервер не работает и мы больше не можем связываться с волонтерами, лучше позволить волонтерам прекратить работу по назначению задач. Основной проблемой здесь является чрезмерное превышение затрат или потраченные впустую усилия. Однако немедленное прекращение работы является слишком поспешным, поскольку временная проблема инфраструктуры может вызвать проблемы со связью.
Следовательно, нам нужно найти разумное количество времени для того, чтобы узел продолжал функционировать после отсоединения от концентратора.
4 / Контроль затрат
Из-за требований бизнеса нам необходимо реализовать два вида контроля затрат. Во-первых, это общее количество комментариев, просмотренных каждым сканером, а во-вторых, общее количество комментариев, просмотренных всеми сканерами, принадлежащих одному и тому же пользователю.
Здесь мы обсуждаем лучший подход к осуществлению контроля над расходами. Очень просто ввести ограничение для каждого сканера. Мы можем просто передать этот лимит узлу Spawn, и он автоматически остановит сканер при достижении лимита.
Однако для лимита на пользователя это не так просто, и у нас есть два возможных подхода. Для более простого выбора мы можем отправить все сканеры одного пользователя на один и тот же узел. Затем, как и в предыдущей проблеме, узел Spawn знает количество собранных комментариев и останавливает все сканеры при достижении лимита. Этот подход прост, но он ограничивает возможность равномерного распределения заданий между узлами. Альтернативный подход состоит в том, чтобы позволить всем узлам получать и обновлять глобальный счетчик. Этот подход создает огромный сетевой трафик внутри и добавляет значительную задержку времени обработки комментариев.
На данный момент мы временно выбираем глобальный встречный подход. Это можно рассмотреть еще раз, если производительность становится огромной проблемой.
5 / Развертывание в облаке
Как и любое другое облачное приложение, мы не можем слишком доверять сети или инфраструктуре. Вот как мы приводим наше приложение в соответствие с контрольным списком, упомянутым в предыдущей статье:
- Stateless : Наш узел вызова не имеет состояния, а концентратор — нет. Поэтому в нашем проекте узлы выполняют реальную работу, а концентратор только объединяет усилия.
- Идемпотентность : Мы реализуем hashCode и равные методы для каждой конфигурации сканера. Мы сохраняем конфигурации гусеничных лент на карте или в наборе. Таким образом, конфигурацию искателя можно отправить несколько раз без каких-либо других побочных эффектов. Более того, наш подход выбора узла гарантирует, что задание будет отправлено на тот же узел.
- Объект доступа к данным . Мы применяем фильтр JsonIgnore к каждому объекту модели, чтобы убедиться, что конфиденциальные данные не передаются по сети.
- Безопасная игра : мы реализуем API проверки работоспособности для каждого узла и самого хаба. Первый уровень поддержки будет немедленно уведомлен, когда что-то не так произошло.
6 / Восстановление
Мы стараемся излечить систему от частичного сбоя. Существует несколько типов ошибок, которые мы можем устранить:
- Ошибка концентратора : узел регистрируется в концентраторе при запуске. С этого момента это является односторонней связью, когда только концентратор отправляет задания на узел, а также запрашивает обновление статуса. Узел считается отключенным, если ему не удалось получить какой-либо контакт от концентратора в течение заранее определенного периода. Если узел отключен, он очистит все конфигурации заданий и снова начнет регистрироваться в концентраторе. Если инцидент вызван сбоем концентратора, новый концентратор извлечет конфигурации сканирования из базы данных и снова начнет распределение заданий. Все существующие задания на узлах Spawn будут очищены, когда узел Spawn перейдет в отдельный режим.
- Отказ узла : если концентратор не может опросить узел, он выполнит полный сброс, удалив все рабочие задания и перераспределив его с начала снова на рабочие узлы. Этот процесс перераспределения помогает обеспечить оптимизированное распределение.
- Сбой задания : при отправке и опросе концентратора происходит два вида сбоев. Если задание не выполнено в процессе опроса, но узел Spawn все еще работает хорошо, Black Widow может переназначить задание тому же узлу снова. То же самое можно сделать, если отправка задания не удалась.
Реализация
Источник данных и подписчик
На начальном этапе каждый сканер может открыть свой собственный канал для извлечения данных, но это больше не имеет смысла при дальнейшей проверке. Для Rss мы можем отсканировать все URL-адреса один раз и найти ключевые слова, которые могут принадлежать нескольким сканерам. Для Twitter он поддерживает до 200 поисковых терминов для одного запроса. Поэтому мы можем открыть один канал, который обслуживает несколько сканеров. Для Datasift это довольно редко, но из-за человеческой ошибки или везения возможно наличие сканеров с одинаковыми поисковыми запросами.
Эта ситуация заставила нас разделить сканер на две сущности: подписчик и источник данных. Подписчик отвечает за использование комментариев, а источник данных отвечает за сканирование комментариев. При таком дизайне, если есть два сканера с похожими ключевыми словами, будет создан один источник данных для обслуживания двух подписчиков, каждый из которых обрабатывает комментарии по-своему.
Источник данных будет создан тогда и только тогда, когда подобного источника данных не существует. Он начинает работать, когда первый подписчик подписывается на него, и удаляется, когда последний подписчик отказывается от него. С помощью Black Widow для отправки похожих подписчиков на один и тот же узел мы можем минимизировать количество созданных источников данных и косвенно минимизировать стоимость сканирования.
Структура данных
Наибольшую озабоченность в отношении структуры данных представляет проблема безопасности потоков. В узле Spawn мы должны хранить всех работающих подписчиков и источники данных в памяти. Есть несколько сценариев, которые нам нужно изменить или получить доступ к этим данным:
- Когда абонент достигает предела, он автоматически отписывается от источника данных, что может привести к деактивации источника данных.
- Когда Черная Вдова отправляет нового подписчика на узлы Spawn.
- Когда Black Widow отправит запрос на отписку от существующего абонента.
- API проверки работоспособности предоставляет доступ ко всем работающим подписчикам и источникам данных.
- Черная вдова регулярно опрашивает статус каждого назначенного абонента.
- Узел Spawn регулярно проверяет и отключает подписчиков-сирот (подписчик, которого не опрашивает Black Widow).
Другая проблема структуры данных — идемпотентность операций. Любая из вышеперечисленных операций может отсутствовать или дублироваться. Чтобы справиться с этой проблемой, вот наш подход
- Реализуйте hashCode и метод equals для каждого подписчика и источника данных.
- Мы выбираем Set или Map для хранения коллекции подписчиков и источников данных. Для записей с идентичным хеш-кодом Map заменит запись при новой вставке, но Set пропустит новую запись. Следовательно, если мы используем Set , нам нужно убедиться, что новые записи могут заменить старые записи.
- Мы используем синхронизированный в коде доступа к данным.
- Если узел Spawn получает нового подписчика, похожего на существующего подписчика, он сравнивает и предпочитает обновить существующего подписчика вместо замены. Это позволяет избежать процесса отмены подписки и подписки идентичных подписчиков, что может прерывать потоковую передачу источника данных.
Маршрутизация
Как упоминалось ранее, нам нужно найти механизм маршрутизации, который служит двум целям:
- Распределите задания равномерно между узлами Spawn.
- Направляйте похожие задания на одни и те же узлы.
Мы решили эту проблему, создав уникальное представление каждого запроса с именем uuid . После этого мы можем использовать простую модульную функцию, чтобы узнать примечание к маршруту:
|
1
2
3
4
|
int size = activeBwsNodes.size();int hashCode = uuid.hashCode();int index = hashCode % size;assignedNode = activeBwsNodes.get(index); |
При такой реализации подписчики с одинаковым uuid всегда будут отправляться на один и тот же узел, и каждый узел имеет равные шансы быть выбранным для обслуживания абонента.
Вся эта практика может быть испорчена, когда есть изменения в коллекции активных узлов Spawn. Таким образом, Black Widow должна очистить все запущенные задания и переназначить их при каждом изменении узла. Однако, изменение узла должно быть довольно редким в производственной среде.
Рукопожатие
Ниже приведена схема последовательности сотрудничества Black Widow и Node:
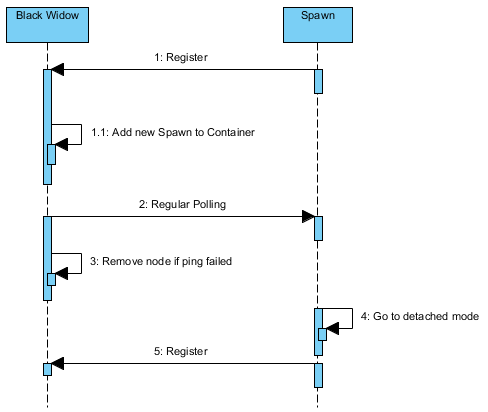
Черная Вдова не знает узла Спауна. Он ждет, пока узел Spawn зарегистрирует себя в Черной Вдове. Оттуда Black Widow несет ответственность за опрос узла для поддержания связи. Если Black Widow не сможет опросить узел, он удалит узел из своего контейнера. Сиротский узел в конечном итоге перейдет в автономный режим, поскольку он больше не опрашивается. В этом режиме узел Spawn очистит существующие задания и попытается снова зарегистрироваться.
Следующая диаграмма — жизненный цикл подписчика:
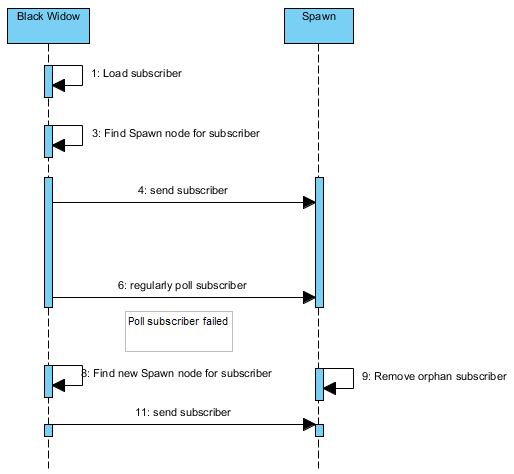
Как и выше, Black Widow отвечает за опрос подписчиков, отправляемых на узел Spawn. Если Black Widow больше не опрашивает подписчика, то узел Spawn будет считать подписчика сиротой и удалить его. Эта практика помогает устранить угрозу запуска узла Spawn устаревшего абонента.
В Black Widow при сбое опроса абонента он пытается получить новый узел для назначения задания. Если узел Spawn подписчика по-прежнему доступен, вполне вероятно, что то же самое задание будет снова отправлено на тот же узел из-за нашего механизма маршрутизации, который мы использовали.
Мониторинг
При счастливом сценарии все подписчики работают, Black Widow опрашивает, и больше ничего не происходит. Однако это вряд ли произойдет в реальной жизни. Время от времени в узлах Black Widow и Spawn будут происходить изменения, вызванные различными событиями.
Для Black Widow будут изменения при следующих обстоятельствах:
- Абонентский лимит попаданий
- Найден новый подписчик
- Существующий подписчик отключен пользователем
- Опрос абонента не проходит
- Сбой узла опроса Spawn
Для обработки изменений инструмент мониторинга Black Widow предлагает две службы: полная перезагрузка и мягкая перезагрузка. «Жесткая перезагрузка» происходит при смене узла, а «Мягкая перезагрузка» — при смене подписчика. Процесс Hard Reload забирает все запущенные задания, перераспределяет с начала по доступным узлам. Процесс Soft Reload удаляет устаревшие задания, назначает новые задания и переназначает невыполненные задания.
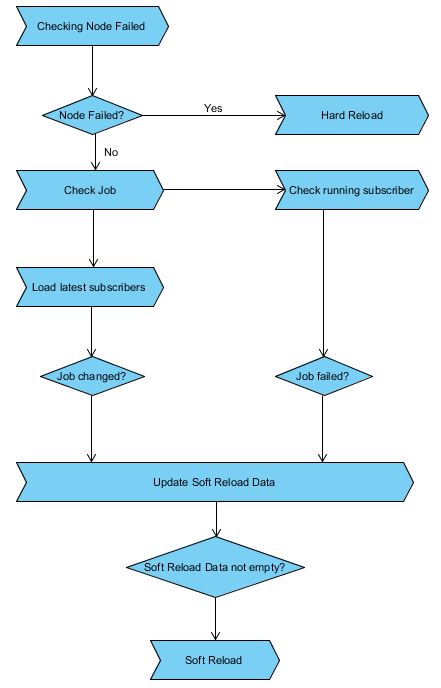
По сравнению с Black Widow, мониторинг узла Spawn проще. Двумя основными проблемами являются поддержание связи с Black Widow и удаление подписчиков-сирот.
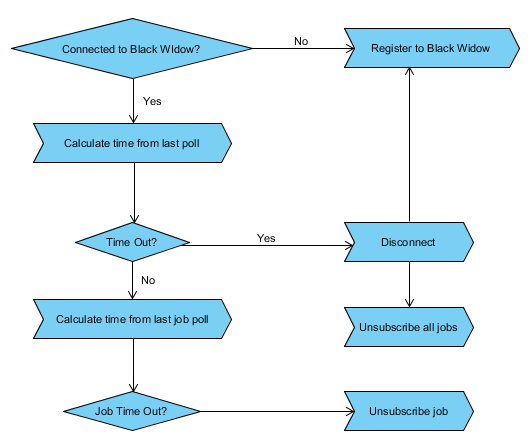
Стратегия развертывания
Стратегия развертывания проста. Нам нужно вызвать Черную Вдову и хотя бы один узел Спауна. Узел Spawn должен знать URL Черной Вдовы. После этого API проверки работоспособности будет использовать количество подписчиков на узел. Мы можем интегрировать проверку работоспособности с AWS API, чтобы автоматически вызывать новый узел Spawn, если существующие узлы перегружены. В образе узла Spawn приложение Spawn должно быть запущено как сервис. Точно так же, когда узлы не используются, мы можем отключить избыточные узлы Spawn.
Черная вдова нуждается в особом отношении из-за ее важности. Если Black Widow дает сбой, мы можем перезапустить приложение. Это приведет к тому, что все существующие задания на узлах Spawn станут бесхозными, и все узлы Spawn перейдут в отдельный режим. Постепенно все узлы очистятся и попытаются зарегистрироваться снова. При конфигурации по умолчанию весь процесс перезапуска происходит в течение 15 минут.
Угрозы и возможное улучшение
При выборе централизованной архитектуры мы знаем, что «Черная вдова» — это самый большой риск для системы. В то время как сбой узла Spawn вызывает только незначительное прерывание у затронутых подписчиков, сбой Black Widow, наконец, приводит к перезапуску узлов Spawn, что займет гораздо больше времени для восстановления.
Более того, даже система может восстановиться с частичной, все еще будет прерывание обслуживания в процессе восстановления. Поэтому, если запросы на опрос не выполняются слишком часто из-за нестабильной инфраструктуры, операция будет сильно затруднена.
Масштабируемость является еще одной проблемой для централизованной архитектуры. У нас не было конкретного количества максимальных узлов Спауна, с которыми может справиться Черная Вдова. Теоретически, это должно быть очень высоким, потому что Black Widow выполняет только незначительную обработку, большая часть ее усилий направлена на отправку HTTP-запросов Возможно, что сеть является основным ограничивающим фактором для этой архитектуры. Из-за этого мы позволяем Черной Вдове опрашивать узлы, а не узлы, опрашивающие Черную Вдову (другие люди делают это, например, Hadoop). При таком подходе Черная Вдова может работать в своем темпе, а не под давлением узлов Спауна.
Один из первых вопросов, который мы получили, заключается в том, является ли это проблемой Map Reduce, и ответ — Нет. Каждый подписчик в нашей распределенной системе сканирования обрабатывает свои собственные комментарии и не сообщает о результатах обратно в Black Widow. Вот почему мы не используем такой продукт Map Reduce, как Hadoop . Наш монитор основан на бизнес-логике, а не только на мониторинге инфраструктуры, поэтому мы решили строить себя с использованием таких инструментов мониторинга, как Zoo Keeper или AKKA .
Для дальнейшего улучшения лучше отказаться от централизованной архитектуры, поскольку несколько концентраторов взаимодействуют друг с другом. Это не должно быть слишком сложно при условии, что Black Widow получает доступ к базе данных только при загрузке подписчика. Поэтому мы можем разрезать данные и позволить каждой Черной Вдове загрузить их часть.
Другим моментом, который заставляет меня чувствовать себя довольно неудовлетворенным, является проверка глобального счетчика для ограничения пользователей. Поскольку проверка выполнялась при каждом сканируемом комментарии, это значительно увеличивает внутренний сетевой трафик и ограничивает масштабируемость системы. Лучшей стратегией должно быть разделение квот на основе скорости обработки. Black Widow может регулировать и перераспределять квоты для каждого подписчика (на разных узлах).
| Ссылка: | Распределенное сканирование от нашего партнера по JCG Тони Нгуена в блоге уголок разработчиков . |