В рамках анализа журналов я хотел узнать даты выпуска Neo4j, которые доступны из заметок о выпуске, и решил попробовать библиотеку rvest scrap Hadley Wickham, которую он выпустил в конце 2014 года.
rvest основан на красивой парочке Python, которая стала моей любимой библиотекой, поэтому я не нашел ее слишком трудной для подбора.
Для начала нам нужно скачать заметки о выпуске локально, чтобы нам не приходилось переходить по сети, когда мы выполняем анализ:
|
1
2
|
|
Мы хотим проанализировать эти страницы и вернуть строки, которые содержат номера версий и даты выпуска. HTML выглядит так:
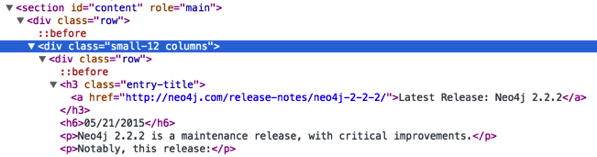
Мы можем получить строки с помощью следующего кода:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
library(rvest)library(dplyr) page1 <- html("release-notes.html")page2 <- html("release-notes2.html") rows = c(page1 %>% html_nodes("div.small-12 div.row"), page2 %>% html_nodes("div.small-12 div.row") ) > rows %>% head(1)[[1]]<div class="row"> <h3 class="entry-title"><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Latest Release: Neo4j 2.2.2</a></h3> <h6>05/21/2015</h6> <p>Neo4j 2.2.2 is a maintenance release, with critical improvements.</p> <p>Notably, this release:</p> <ul><li>Provides support for running Neo4j on Oracle and OpenJDK Java 8 runtimes</li> <li>Resolves an issue that prevented the Neo4j Browser from loading in the latest Chrome release (43.0.2357.65).</li> <li>Corrects the behavior of the <code>:sysinfo</code> (aka <code>:play sysinfo</code>) browser directive.</li> <li>Improves the <a href="http://neo4j.com/docs/2.2.2/import-tool.html">import tool</a> handling of values containing newlines, and adds support f...</li></ul><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Read full notes →</a> </div> |
Теперь нам нужно пройтись по строкам и выбрать только версию и дату выпуска. Для этого я написал следующую функцию и удалил лишний текст, который нам не интересен:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
generate_releases = function(rows) { releases = data.frame() for(row in rows) { version = row %>% html_node("h3.entry-title") date = row %>% html_node("h6") if(!is.null(version) && !is.null(date)) { version = version %>% html_text() version = gsub("Latest Release: ", "", version) version = gsub("Neo4j ", "", version) releases = rbind(releases, data.frame(version = version, date = date %>% html_text())) } } return(releases)} > generate_releases(rows) version date1 2.2.2 05/21/20152 2.2.1 04/14/20153 2.1.8 04/01/20154 2.2.0 03/25/20155 2.1.7 02/03/20156 2.1.6 11/25/20147 1.9.9 10/13/20148 2.1.5 09/30/20149 2.1.4 09/04/201410 2.1.3 07/28/201411 2.0.4 07/08/201412 1.9.8 06/19/201413 2.1.2 06/11/201414 2.0.3 04/30/201415 2.0.1 02/04/201416 2.0.2 04/15/201417 1.9.7 04/11/201418 1.9.6 02/03/201419 2.0 12/11/201320 1.9.5 11/11/201321 1.9.4 09/19/201322 1.9.3 08/30/201323 1.9.2 07/16/201324 1.9.1 06/24/201325 1.9 05/13/201326 1.8.3 // |
Наконец, я хотел преобразовать столбец ‘date’ в формат даты R и избавиться от строки 1.8.3, поскольку она не содержит дату. lubridate — моя библиотека goto для манипулирования датами в R, поэтому мы будем использовать ее здесь:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
library(lubridate) > generate_releases(rows) %>% mutate(date = mdy(date)) %>% filter(!is.na(date)) version date1 2.2.2 2015-05-212 2.2.1 2015-04-143 2.1.8 2015-04-014 2.2.0 2015-03-255 2.1.7 2015-02-036 2.1.6 2014-11-257 1.9.9 2014-10-138 2.1.5 2014-09-309 2.1.4 2014-09-0410 2.1.3 2014-07-2811 2.0.4 2014-07-0812 1.9.8 2014-06-1913 2.1.2 2014-06-1114 2.0.3 2014-04-3015 2.0.1 2014-02-0416 2.0.2 2014-04-1517 1.9.7 2014-04-1118 1.9.6 2014-02-0319 2.0 2013-12-1120 1.9.5 2013-11-1121 1.9.4 2013-09-1922 1.9.3 2013-08-3023 1.9.2 2013-07-1624 1.9.1 2013-06-2425 1.9 2013-05-13 |
Затем мы могли легко увидеть, сколько релизов было за год:
|
01
02
03
04
05
06
07
08
09
10
11
|
releasesByDate = generate_releases(rows) %>% mutate(date = mdy(date)) %>% filter(!is.na(date)) > releasesByDate %>% mutate(year = year(date)) %>% count(year)Source: local data frame [3 x 2] year n1 2013 72 2014 133 2015 5 |
Или по месяцам:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
> releasesByDate %>% mutate(month = month(date)) %>% count(month)Source: local data frame [11 x 2] month n1 2 32 3 13 4 54 5 25 6 36 7 37 8 18 9 39 10 110 11 211 12 1 |
До этого быстрого взлома я всегда обращался к Ruby или Python всякий раз, когда хотел очистить набор данных, но похоже, что rvest делает R подходящим вариантом для этого типа работы. Хорошие времена!
| Ссылка: | R: Scraping Neo4j с релизом rvest от нашего партнера JCG Марка Нидхэма в блоге Марка Нидхэма . |