Ранее я писал о линейной модели, которую я создал, чтобы предсказать, сколько людей ответит «да» на событие встречи, и, обнаружив, что между какой-либо из моих независимых переменных и RSVP не было большой корреляции, я немного застрял.
По счастливой случайности, я столкнулся с Антониосом на встрече месяц назад, и он предложил взглянуть на то, что я пробовал до сих пор, и дать мне несколько советов о том, как развиваться.
Первое, на что он указал, это то, что все мои функции были связаны с датой и временем, и что я должен попытаться сгенерировать некоторые другие функции. Он предложил мне начать со следующего:
- информация об организаторах (количественная оценка популярности организаторов, сколько человек у них работает)
- информация о месте проведения (сколько людей туда поместится, как далеко от центра города)
- количество твитов на событие, за X дней до события
Я много читал на форумах Kaggle о том, что разработка функций является наиболее важной частью построения статистических моделей, но она не поняла, что это значит, пока Антониос не указал на это.
Первое, что я решил сделать, — это ввести данные для всех лондонских собраний по NoSQL, а не только по Neo4j, чтобы дать себе немного больше данных для работы.
Членство в группах
Сделав это, из визуального осмотра стало ясно, что группы встреч с большинством участников (например, Data Science London, Big Data London), похоже, получили наибольшую явку.
Я подумал, что было бы интересно посмотреть, какова взаимосвязь между членством в группе и RSVP, так что это была первая новая функция, которую я добавил.
Я сгенерировал эту функцию с помощью комбинации запроса Neo4j и кода R, в результате чего этот кадр данных был представлен в виде файла CSV .
Мы можем быстро просмотреть его, чтобы увидеть некоторые события и членство в группе в то время:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
> df = read.csv("/tmp/membersWithGroupCounts.csv")> df$eventTime = as.POSIXct(df$eventTime)> df %>% sample_n(10) %>% select(event.name, g.name, eventTime, groupMembers, rsvps) event.name g.name eventTime groupMembers rsvps23 Scoring Models, Apache Drill for querying structured & unstructured data Data Science London 2014-09-18 18:30:00 3466 159421 London Office Hours London MongoDB User Group 2012-08-22 17:00:00 468 6304 MongoDB University Study Group London Meet up London MongoDB User Group 2014-07-16 17:00:00 1256 2343 December Meetup London ElasticSearch User Group 2014-12-10 18:30:00 721 126222 Intro to Graphs Neo4j - London User Group 2014-09-03 18:30:00 1453 39207 Intro to Machine Learning with Scikit-Learn Women in Data 2014-11-11 18:15:00 574 41168 NoSQL panel and LevelDB + Node.js London NoSQL 2014-04-15 18:30:00 183 51443 London Office Hours London MongoDB User Group 2012-11-29 17:00:00 590 379 Apache Cassandra 1.2 with Jonathan Ellis Cassandra London 2013-03-06 19:00:00 399 95362 Span conference Span: scalable and distributed computing 2014-10-28 09:00:00 67 13 |
Одной вещью, которую я нашел трудной, было нахождение особенностей, определенных для события — я не уверен, насколько это важно. Я создал функции для места или группы гораздо проще.
Сначала давайте посмотрим, есть ли на самом деле какая-либо корреляция между этими двумя переменными, составив их график:
|
1
2
|
ggplot(aes(x = groupMembers, y = rsvps), data = df) + geom_point() |
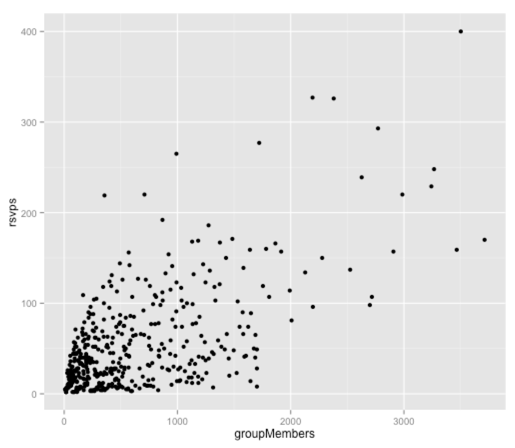
Похоже, что есть положительная корреляция между этими двумя переменными, но давайте создадим линейную модель с одной переменной, чтобы увидеть, как объясняется большая часть изменений:
|
1
2
3
4
|
> fit = lm(rsvps ~ groupMembers, data = df)> fit$coef (Intercept) groupMembers 20.03579637 0.05382738 |
Наше линейное модельное уравнение поэтому:
rsvps = 20,03579637 + 0,05382738 (группа членов)
Давайте посмотрим, насколько хорошо коррелируют наши прогнозируемые RSVP и фактические RSVP:
|
1
2
3
|
> df$predictedRSVPs = predict(fit, df)> with(df, cor(rsvps, predictedRSVPs))[1] 0.6263096 |
Не так уж плохо! Между этими переменными существует довольно сильная корреляция, хотя она не идеальна.
Часы в день
В моей первой модели я рассматривал время как категориальную переменную, но Антониос отметил, что зачастую легче понять взаимосвязь между переменными, если они являются непрерывными, поэтому я преобразовал время события следующим образом:
|
1
|
df$hoursIntoDay = as.numeric(df$eventTime - trunc(df$eventTime, "day"), units="hours") |
Давайте посмотрим, как это соотносится с подсчетом RSVP:
|
1
2
|
ggplot(aes(x = hoursIntoDay, y = rsvps), data = df) + geom_point() |
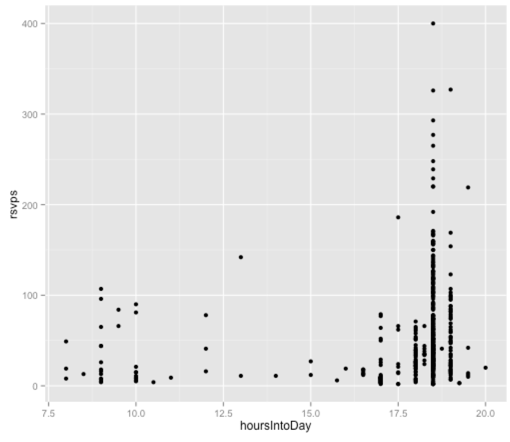
Здесь немного сложнее увидеть тенденцию, так как есть довольно отдельные моменты, когда происходят события, и большинство начинается в 6.30 или 7.00. Тем не менее, давайте построим линейную модель только с этой переменной:
|
1
2
3
4
5
6
7
8
|
> fit = lm(rsvps ~ hoursIntoDay, data = df)> fit$coef (Intercept) hoursIntoDay -18.79895 4.12984> > df$predictedRSVPs = predict(fit, df)> with(df, cor(rsvps, predictedRSVPs))[1] 0.181472 |
Расстояние от центра Лондона
Затем я попробовал функцию, основанную на расположении места проведения мероприятий. Предполагалось, что если место будет ближе к центру Лондона, люди будут чаще посещать.
Чтобы рассчитать это расстояние, я использовал функцию distHaversine из пакета geosphere, как показано в предыдущем сообщении в блоге .
Давайте посмотрим на график для этой переменной:
|
1
2
|
ggplot(aes(x = distanceFromCentre, y = rsvps), data = df) + geom_point() |
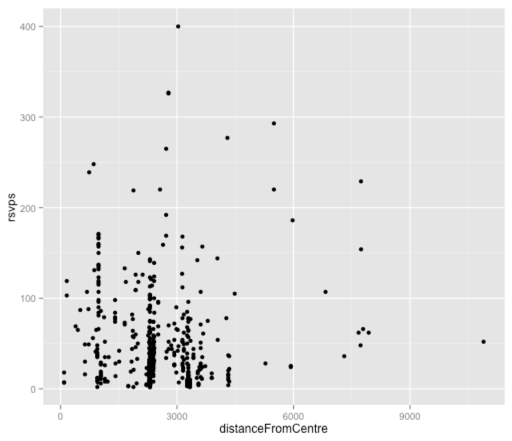
Трудно сказать многое из этого сюжета, в основном потому, что большинство точек сгруппированы вокруг отметки 2500 метров, которая представляет объекты Shoreditch. Давайте подключим его к линейной модели и посмотрим, что мы придумаем:
|
1
2
3
4
5
6
7
8
|
> fit = lm(rsvps ~ distanceFromCentre, data = df)> fit$coef (Intercept) distanceFromCentre 57.243646619 -0.001310492> > df$predictedRSVPs = predict(fit, df)> with(df, cor(rsvps, predictedRSVPs))[1] 0.02999708 |
Интересно, что здесь почти нет корреляции, что меня удивило. Я попытался объединить эту переменную в модели с несколькими переменными, но она все еще не оказала большого влияния, поэтому я думаю, что мы пока оставим эту переменную.
Это то же самое, что я сделал в данный момент, и, несмотря на то, что я потратил на это немало времени, я до сих пор не очень-то объяснил разницу в скорости передачи RSVP!
Мне удалось определить некоторые способы, с помощью которых я смог придумать новые функции, чтобы попробовать их:
- Прочитайте, что делают другие люди, например, у меня есть некоторые идеи для переменных лагов (например, сколько людей пошло на вашу предыдущую встречу), прочитав об этой линейной модели бейсбола
- Поговорите с другими людьми о вашей модели — у них часто бывают идеи, о которых вы даже не думаете, что слишком глубоко вникли в проблему.
- Посмотрите, какие данные у вас уже есть, попробуйте включить их и посмотрите, к чему это приведет
Следующее направление, которое я начал изучать, — это тематическое моделирование, поскольку у меня есть гипотеза о том, что люди проводят RSVP для мероприятий, основанных на содержании переговоров, но я не уверен в том, как лучше это сделать.
Мои нынешние мысли — извлечь некоторые темы / термины, следуя примеру из главы 6 « Машинного обучения для хакеров» .
| Ссылка: | Р: Представление разработки линейной модели от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |