Недавно я наткнулся на отличную статью, написанную Стианом Хаклевым, в которой он описывает то, что ему хотелось бы, чтобы ему сказали, прежде чем начинать с R , одна из которых заключается в том, чтобы очистить все данные в коде, который я решил попробовать.
Моя цель — оставить необработанные данные полностью неизменными и выполнить все преобразования в коде, которые можно запустить в любой момент.
Пока я пишу сценарии, я часто прыгаю, выборочно выполняя отдельные строки или блоки кода, выполняя команды для проверки данных в REPL (чтение-оценка-печать-цикл, где каждая команда выполняется, как только вы введите enter, на картинке выше это панель справа) и т. д.
Но я стараюсь убедиться, что когда я закончу, скрипт сам по себе будет работать.
Я думал, что набор данных Google Trends будет интересным, чтобы поиграть с ним, поскольку он дает вам CSV, содержащий несколько разных битов данных, которые меня интересуют только «интерес с течением времени».
Не очень легко автоматизировать загрузку CSV-файла, поэтому я сделал это вручную и автоматизировал все с этого момента.
Первым шагом было чтение файла CSV и изучение некоторых строк, чтобы увидеть, что в нем содержится:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
> library(dplyr) > googleTrends = read.csv("/Users/markneedham/Downloads/report.csv", row.names=NULL) > googleTrends %>% head()## row.names Web.Search.interest..neo4j## 1 Worldwide; 2004 - present ## 2 Interest over time ## 3 Week neo4j## 4 2004-01-04 - 2004-01-10 0## 5 2004-01-11 - 2004-01-17 0## 6 2004-01-18 - 2004-01-24 0 > googleTrends %>% sample_n(10)## row.names Web.Search.interest..neo4j## 109 2006-01-08 - 2006-01-14 0## 113 2006-02-05 - 2006-02-11 0## 267 2009-01-18 - 2009-01-24 0## 199 2007-09-30 - 2007-10-06 0## 522 2013-12-08 - 2013-12-14 88## 265 2009-01-04 - 2009-01-10 0## 285 2009-05-24 - 2009-05-30 0## 318 2010-01-10 - 2010-01-16 0## 495 2013-06-02 - 2013-06-08 79## 28 2004-06-20 - 2004-06-26 0 > googleTrends %>% tail()## row.names Web.Search.interest..neo4j## 658 neo4j example Breakout## 659 neo4j graph database Breakout## 660 neo4j java Breakout## 661 neo4j node Breakout## 662 neo4j rest Breakout## 663 neo4j tutorial Breakout |
Мы хотим сохранить только те строки, которые содержат (неделя, проценты) пары, поэтому первое, что мы сделаем, это переименуем столбцы:
|
1
|
names(googleTrends) = c("week", "score") |
Теперь мы хотим удалить строки, которые не содержат пар (неделя, процент). Самый простой способ сделать это — найти строки, которые не содержат значений даты в столбце «неделя».
Сначала нам нужно разделить даты начала и окончания в этом столбце с помощью функции strsplit .
Я обнаружил, что гораздо проще применить функцию к каждой строке отдельно, чем передавать список значений, поэтому я создал фиктивный столбец с номером строки, чтобы я мог это сделать (уловка, которую показал мне Антониос ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
> googleTrends %>% mutate(ind = row_number()) %>% group_by(ind) %>% mutate(dates = strsplit(week, " - "), start = dates[[1]][1] %>% strptime("%Y-%m-%d") %>% as.character(), end = dates[[1]][2] %>% strptime("%Y-%m-%d") %>% as.character()) %>% head()## Source: local data frame [6 x 6]## Groups: ind## ## week score ind dates start end## 1 Worldwide; 2004 - present 1 1 <chr[2]> NA NA## 2 Interest over time 1 2 <chr[1]> NA NA## 3 Week 90 3 <chr[1]> NA NA## 4 2004-01-04 - 2004-01-10 3 4 <chr[2]> 2004-01-04 2004-01-10## 5 2004-01-11 - 2004-01-17 3 5 <chr[2]> 2004-01-11 2004-01-17## 6 2004-01-18 - 2004-01-24 3 6 <chr[2]> 2004-01-18 2004-01-24 |
Теперь нам нужно избавиться от строк, которые имеют значение NA для «start» или «end»:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
> googleTrends %>% mutate(ind = row_number()) %>% group_by(ind) %>% mutate(dates = strsplit(week, " - "), start = dates[[1]][1] %>% strptime("%Y-%m-%d") %>% as.character(), end = dates[[1]][2] %>% strptime("%Y-%m-%d") %>% as.character()) %>% filter(!is.na(start) | !is.na(end)) %>% head()## Source: local data frame [6 x 6]## Groups: ind## ## week score ind dates start end## 1 2004-01-04 - 2004-01-10 3 4 <chr[2]> 2004-01-04 2004-01-10## 2 2004-01-11 - 2004-01-17 3 5 <chr[2]> 2004-01-11 2004-01-17## 3 2004-01-18 - 2004-01-24 3 6 <chr[2]> 2004-01-18 2004-01-24## 4 2004-01-25 - 2004-01-31 3 7 <chr[2]> 2004-01-25 2004-01-31## 5 2004-02-01 - 2004-02-07 3 8 <chr[2]> 2004-02-01 2004-02-07## 6 2004-02-08 - 2004-02-14 3 9 <chr[2]> 2004-02-08 2004-02-14 |
Далее мы избавимся от «недели», «инд» и «даты», так как они нам больше не понадобятся:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
> cleanGoogleTrends = googleTrends %>% mutate(ind = row_number()) %>% group_by(ind) %>% mutate(dates = strsplit(week, " - "), start = dates[[1]][1] %>% strptime("%Y-%m-%d") %>% as.character(), end = dates[[1]][2] %>% strptime("%Y-%m-%d") %>% as.character()) %>% filter(!is.na(start) | !is.na(end)) %>% ungroup() %>% select(-c(ind, dates, week)) > cleanGoogleTrends %>% head()## Source: local data frame [6 x 3]## ## score start end## 1 3 2004-01-04 2004-01-10## 2 3 2004-01-11 2004-01-17## 3 3 2004-01-18 2004-01-24## 4 3 2004-01-25 2004-01-31## 5 3 2004-02-01 2004-02-07## 6 3 2004-02-08 2004-02-14 > cleanGoogleTrends %>% sample_n(10)## Source: local data frame [10 x 3]## ## score start end## 1 8 2010-09-26 2010-10-02## 2 73 2013-11-17 2013-11-23## 3 52 2012-07-01 2012-07-07## 4 3 2005-06-19 2005-06-25## 5 3 2004-12-12 2004-12-18## 6 3 2009-09-06 2009-09-12## 7 71 2014-09-14 2014-09-20## 8 3 2004-12-26 2005-01-01## 9 62 2013-03-03 2013-03-09## 10 3 2006-03-19 2006-03-25 > cleanGoogleTrends %>% tail()## Source: local data frame [6 x 3]## ## score start end## 1 80 2014-10-19 2014-10-25## 2 80 2014-10-26 2014-11-01## 3 84 2014-11-02 2014-11-08## 4 81 2014-11-09 2014-11-15## 5 83 2014-11-16 2014-11-22## 6 2 2014-11-23 2014-11-29 |
Хорошо, теперь мы готовы к сюжету. Это была моя первая попытка:
|
1
2
3
4
|
> library(ggplot2)> ggplot(aes(x = start, y = score), data = cleanGoogleTrends) + geom_line(size = 0.5)## geom_path: Each group consist of only one observation. Do you need to adjust the group aesthetic? |
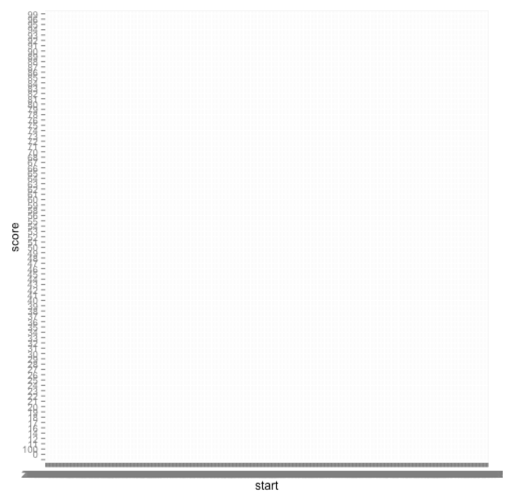
Как видите, не слишком удачно! Первая ошибка, которую я сделал, не говорит ggplot, что столбец ‘start’ является датой, и поэтому он может использовать этот порядок при построении графика:
|
1
2
3
|
> cleanGoogleTrends = cleanGoogleTrends %>% mutate(start = as.Date(start))> ggplot(aes(x = start, y = score), data = cleanGoogleTrends) + geom_line(size = 0.5) |
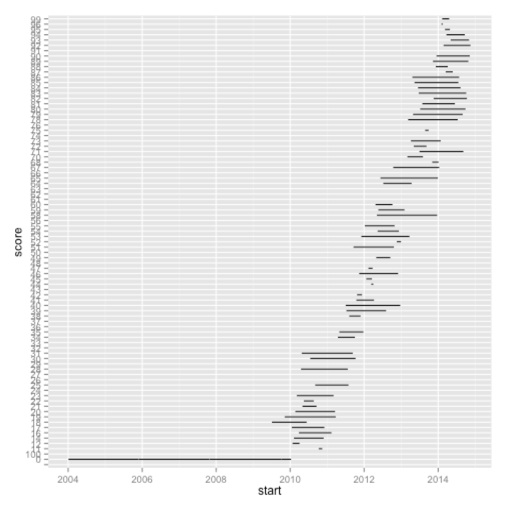
Моя следующая ошибка заключается в том, что «оценка» не рассматривается как непрерывная переменная, и поэтому мы получаем очень странную диаграмму. Мы можем видеть это, если мы вызываем функцию класса :
|
1
2
|
> class(cleanGoogleTrends$score)## [1] "factor" |
Давайте исправим это и построим график снова:
|
1
2
3
|
> cleanGoogleTrends = cleanGoogleTrends %>% mutate(score = as.numeric(score))> ggplot(aes(x = start, y = score), data = cleanGoogleTrends) + geom_line(size = 0.5) |
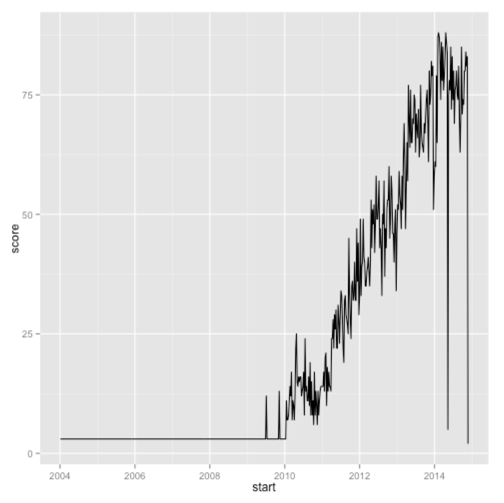
Это намного лучше, но в баллах по неделям довольно много шума, который мы можем немного сгладить, построив вместо этого скользящее среднее за последние 4 недели :
|
1
2
3
4
5
6
7
|
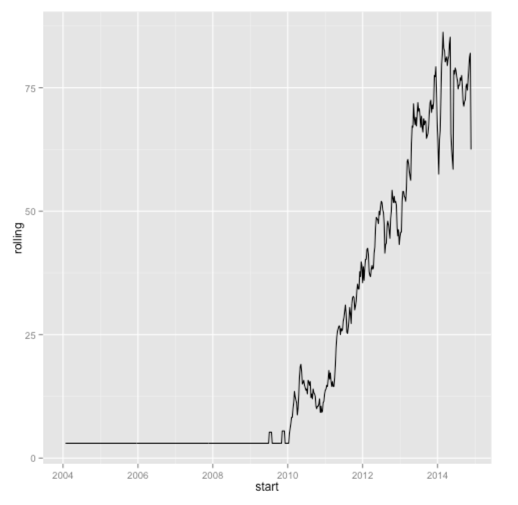
> library(zoo)> cleanGoogleTrends = cleanGoogleTrends %>% mutate(rolling = rollmean(score, 4, fill = NA, align=c("right")), start = as.Date(start)) > ggplot(aes(x = start, y = rolling), data = cleanGoogleTrends) + geom_line(size = 0.5) |
Вот полный код, если вы хотите воспроизвести:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
library(dplyr)library(zoo)library(ggplot2) googleTrends = read.csv("/Users/markneedham/Downloads/report.csv", row.names=NULL)names(googleTrends) = c("week", "score") cleanGoogleTrends = googleTrends %>% mutate(ind = row_number()) %>% group_by(ind) %>% mutate(dates = strsplit(week, " - "), start = dates[[1]][1] %>% strptime("%Y-%m-%d") %>% as.character(), end = dates[[1]][2] %>% strptime("%Y-%m-%d") %>% as.character()) %>% filter(!is.na(start) | !is.na(end)) %>% ungroup() %>% select(-c(ind, dates, week)) %>% mutate(start = as.Date(start), score = as.numeric(score), rolling = rollmean(score, 4, fill = NA, align=c("right"))) ggplot(aes(x = start, y = rolling), data = cleanGoogleTrends) + geom_line(size = 0.5) |
Мой следующий шаг — сопоставить оценки Google Trends с моим набором данных о встречах, чтобы увидеть, есть ли какие-нибудь интересные корреляции.
Кроме того, я использовал knitr при составлении этого поста — он отлично работает для проверки того, что вы включили все шаги и что он действительно работает!
| Ссылка: | Р: Очистка и отображение данных Google Trends от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |