В прошлом году я столкнулся с библиотекой обнаружения аномалий в Твиттере, но у меня еще не было причин использовать ее для тестового прогона, поэтому, приведя данные о частоте своего поста в блог в форму, я подумал, что было бы интересно прогнать ее по алгоритму.
Я хотел посмотреть, обнаружит ли он какие-то периоды времени, когда количество постов значительно различалось — у меня нет действия, которое я собираюсь предпринять, основываясь на результатах, это любопытство больше всего на свете!
Сначала нам нужно установить библиотеку. Это не на CRAN, поэтому нам нужно использовать devtools для его установки из репозитория github:
|
1
2
3
|
install.packages("devtools")devtools::install_github("twitter/AnomalyDetection")library(AnomalyDetection) |
Ожидаемый формат данных — два столбца: один содержит метку времени, а другой — счетчик. например, используя фрейм данных raw_data, который находится в области действия при добавлении библиотеки:
|
1
2
3
4
5
6
7
8
9
|
> library(dplyr)> raw_data %>% head() timestamp count1 1980-09-25 14:01:00 182.4782 1980-09-25 14:02:00 176.2313 1980-09-25 14:03:00 183.9174 1980-09-25 14:04:00 177.7985 1980-09-25 14:05:00 165.4696 1980-09-25 14:06:00 181.878 |
В нашем случае временные метки будут датой начала недели и подсчитывают количество постов на этой неделе. Но сначала давайте попрактикуемся в вызове функции аномалий с использованием стандартных данных:
|
1
2
|
res = AnomalyDetectionTs(raw_data, max_anoms=0.02, direction='both', plot=TRUE)res$plot |
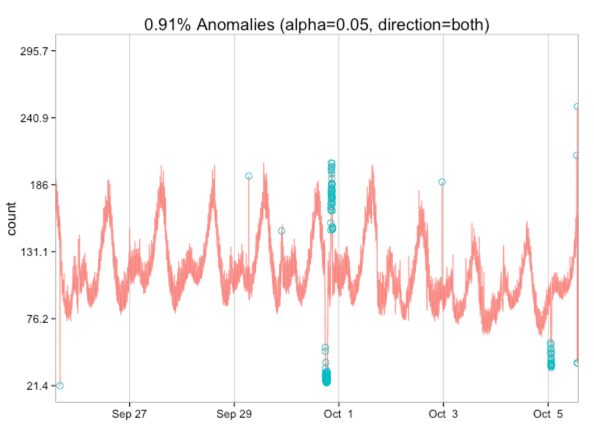
Из этой визуализации мы узнаем, что следует ожидать выявления как высоких, так и низких выбросов. Давайте попробуем с данными публикации поста в блоге.
Нам нужно привести данные в форму, поэтому мы начнем с подсчета количества сообщений в блоге по паре (неделя, год):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
> df %>% sample_n(5) title date1425 Coding: Copy/Paste then refactor 2009-10-31 07:54:31783 Neo4j 2.0.0-M06 -> 2.0.0-RC1: Working with path expressions 2013-11-23 10:30:41960 R: Removing for loops 2015-04-18 23:53:20966 R: dplyr - Error in (list: invalid subscript type 'double' 2015-04-27 22:34:43343 Parsing XML from the unix terminal/shell 2011-09-03 23:42:11 > byWeek = df %>% mutate(year = year(date), week = week(date)) %>% group_by(week, year) %>% summarise(n = n()) %>% ungroup() %>% arrange(desc(n)) > byWeek %>% sample_n(5)Source: local data frame [5 x 3] week year n1 44 2009 62 37 2011 43 39 2012 34 7 2013 45 6 2010 6 |
Отлично. Следующим шагом является перевод этого фрейма данных в один, содержащий дату, представляющую начало этой недели, и количество постов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
> data = byWeek %>% mutate(start_of_week = calculate_start_of_week(week, year)) %>% filter(start_of_week > ymd("2008-07-01")) %>% select(start_of_week, n) > data %>% sample_n(5)Source: local data frame [5 x 2] start_of_week n1 2010-09-10 42 2013-04-09 43 2010-04-30 64 2012-03-11 35 2014-12-03 3 |
Теперь мы готовы подключить его к функции обнаружения аномалий:
|
1
2
3
4
5
|
res = AnomalyDetectionTs(data, max_anoms=0.02, direction='both', plot=TRUE)res$plot |
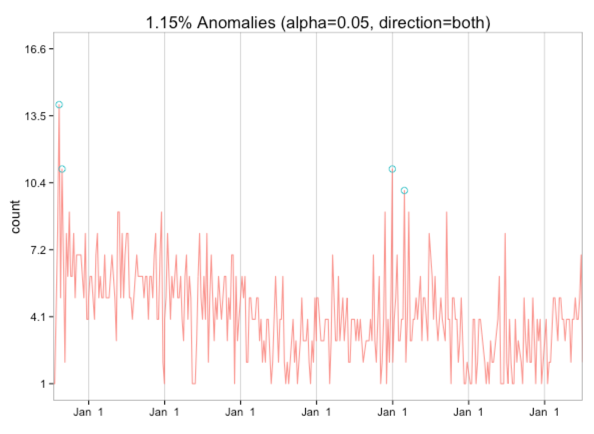
Интересно, что у меня, похоже, нет каких-либо аномалий низкого уровня — была пара действительно частых недель, когда я впервые начал писать, и я думаю, что одна из других недель содержит канун Нового года, когда мне было особенно скучно!
Если мы сгруппируем по месяцам, то только самый первый месяц выделяется как выброс:
|
01
02
03
04
05
06
07
08
09
10
|
data = byMonth %>% mutate(start_of_month = ymd(paste(year, month, 1, sep="-"))) %>% filter(start_of_month > ymd("2008-07-01")) %>% select(start_of_month, n)res = AnomalyDetectionTs(data, max_anoms=0.02, direction='both', #longterm = TRUE, plot=TRUE)res$plot |
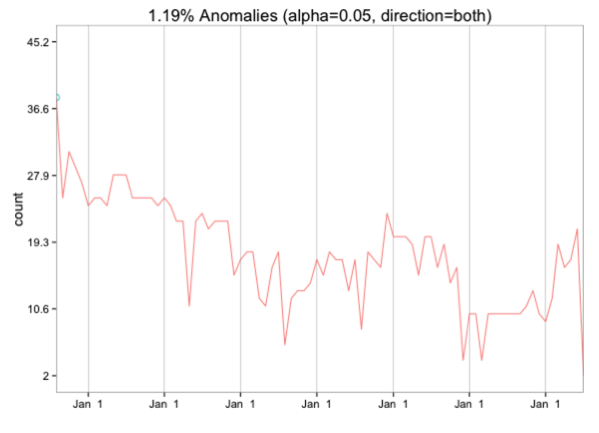
Я не уверен, что еще нужно сделать для обнаружения аномалий, но если у вас есть какие-либо идеи, пожалуйста, дайте мне знать!
| Ссылка: | Р: Обнаружение аномалии частоты сообщений в блоге от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |