Недавно я наткнулся на интересную запись в блоге Джулии Эванс, показывающую, как генерировать больший набор точек данных путем выборки небольшого набора точек данных, которые мы фактически используем с помощью начальной загрузки . Все примеры Джулии написаны на Python, поэтому я подумал, что было бы интересно перевести их на R.
Мы выполняем начальную загрузку, чтобы смоделировать количество неявок на рейс, чтобы мы могли определить, на сколько мест мы можем забронировать самолет.
Мы начинаем с небольшой выборки неявок и исходим из предположения, что можно скинуть кого-нибудь с рейса в 5% случаев. Давайте выясним, сколько людей будет для нашего начального образца:
|
1
2
3
4
|
> data = c(0, 1, 3, 2, 8, 2, 3, 4)> quantile(data, 0.05) 5% 0.35 |
0,35 человек! Это не особенно полезный результат, поэтому мы собираемся пересчитать исходный набор данных 10000 раз, взяв 5% -й файл каждый раз, и посмотрим, получится ли что-нибудь получше:
Мы собираемся использовать функцию sample с заменой для генерации наших повторных выборок :
|
1
2
3
4
|
> sample(data, replace = TRUE)[1] 0 3 2 8 8 0 8 0> sample(data, replace = TRUE)[1] 2 2 4 3 4 4 2 2 |
Теперь давайте напишем функцию, которая сделает это несколько раз:
|
01
02
03
04
05
06
07
08
09
10
|
library(ggplot) bootstrap_5th_percentile = function(data, n_bootstraps) { return(sapply(1:n_bootstraps, function(iteration) quantile(sample(data, replace = TRUE), 0.05)))} values = bootstrap_5th_percentile(data, 10000) ggplot(aes(x = value), data = data.frame(value = values)) + geom_histogram(binwidth=0.25) |
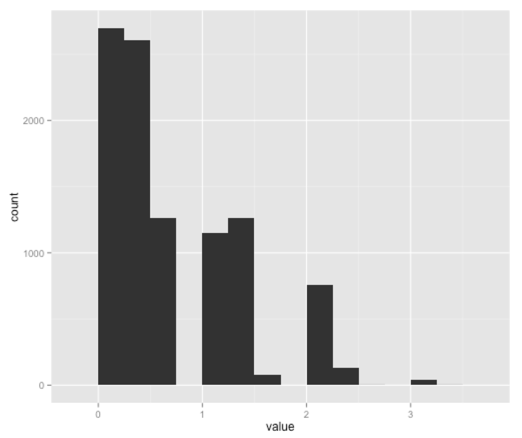
Таким образом, эта визуализация говорит нам, что мы можем перепродать 0-2 человека, но мы не знаем точного числа.
Давайте попробуем то же самое упражнение, но с большим набором начальных данных, состоящим из 1000 значений, а не просто 8. Сначала мы сгенерируем распределение (со средним значением 5 и стандартным отклонением 2) и визуализируем его:
|
1
2
3
4
5
|
library(dplyr) df = data.frame(value = rnorm(1000,5, 2))df = df %>% filter(value >= 0) %>% mutate(value = as.integer(round(value)))ggplot(aes(x = value), data = df) + geom_histogram(binwidth=1) |

Наш дистрибутив, кажется, имеет гораздо больше значений около 4 и 5, тогда как версия Python имеет более плоский дистрибутив — я не уверен, почему это так, если у вас есть какие-либо идеи, дайте мне знать. В любом случае, давайте проверим 5% ile для этого набора данных:
|
1
2
3
|
> quantile(df$value, 0.05)5% 2 |
Здорово! Теперь, по крайней мере, у нас есть целочисленное значение, а не 0.35, которое мы получили ранее. Наконец, давайте сделаем небольшую загрузку нашего нового дистрибутива и посмотрим, что мы получим на 5%:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
resampled = bootstrap_5th_percentile(df$value, 10000)byValue = data.frame(value = resampled) %>% count(value) > byValueSource: local data frame [3 x 2] value n1 1.0 32 1.7 23 2.0 9995 ggplot(aes(x = value, y = n), data = byValue) + geom_bar(stat = "identity") |
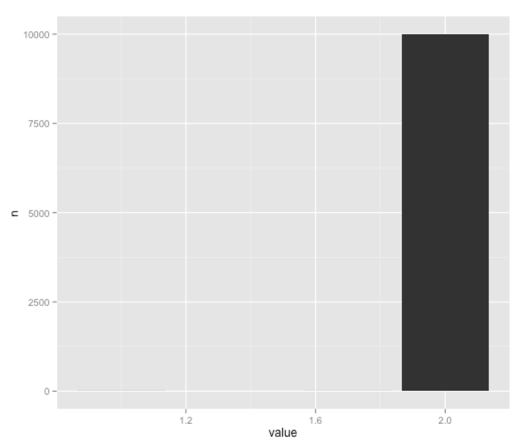
«2» — безусловно самый популярный 5% -й файл здесь, хотя кажется, что он в большей степени ориентирован на это значение, чем с версией Джулии на Python, что, как я полагаю, связано с тем, что мы, по-видимому, выбрали несколько иной дистрибутив.
| Ссылка: | R: Загрузите доверительные интервалы от нашего партнера JCG Марка Нидхэма в блоге Марка Нидхэма . |