Иногда предполагалось, что Spring и Spring Boot являются «тяжеловесными», возможно, только потому, что они позволяют приложениям прыгать выше своего веса, предоставляя множество функций для не очень большого количества пользовательского кода. В этой статье мы сконцентрируемся на использовании памяти и спросим, можем ли мы количественно оценить эффект от использования Spring? В частности, мы хотели бы узнать больше о реальных издержках использования Spring по сравнению с другими приложениями JVM. Мы начнем с создания базового приложения с помощью Spring Boot и рассмотрим несколько разных способов его измерения во время работы. Затем мы рассмотрим некоторые точки сравнения: простые приложения Java, приложения, которые используют Spring, но не Spring Boot, приложение, которое использует Spring Boot, но без автоконфигурации, и некоторые примеры приложений Ratpack.
Приложение Vanilla Spring Boot
В качестве основы мы создаем статическое приложение с несколькими веб-файлами и spring.resources.enabled=true. Это идеально подходит для обслуживания статичного контента, возможно, с конечной точкой REST или двумя. Исходный код приложения, которое мы использовали для тестирования, находится на github . Вы можете создать его с помощью mvnwскрипта-обёртки, если у вас есть JDK 1.8 и он находится на вашем пути ( mvnw package). Его можно запустить так:
$ java -Xmx32m -Xss256k -jar target/demo-0.0.1-SNAPSHOT.jarМы добавляем некоторую нагрузку, просто чтобы согреть пулы потоков и заставить все пути кода быть задействованными:
$ ab -n 2000 -c 4 http://localhost:8080/Мы можем немного ограничить потоки в application.properties:
server.tomcat.max-threads: 4но в конце это не имеет большого значения для чисел. Из анализа, приведенного ниже, мы делаем вывод, что при сохранении размера стека, который мы используем, будет сэкономлено не более МБ. Все анализируемые нами веб-приложения Spring Boot имеют одинаковую конфигурацию.
Возможно, нам придется беспокоиться о том, насколько велик путь к классам, чтобы оценить, что происходит с памятью. Несмотря на некоторые заявления в Интернете о том, что память JVM отображает все файлы jar на пути к классам, мы на самом деле не нашли никаких доказательств того, что размер пути к классам влияет на работающее приложение. Для справки, размер jar-зависимостей (не включая JDK) в ванильном образце составляет 18 МБ:
$ jar -tvf target/demo-0.0.1-SNAPSHOT.jar | grep lib/.*.jar | awk '{tot+=$1;} END {print tot}'
18893563Это включает в себя Spring Boot Web и приводы Actuator, а также 3 или 4 веб-файла для статических ресурсов и локатор веб-файла. Абсолютно минимальное приложение Spring Boot, включая Spring и некоторые журналы, но ни один веб-сервер не будет занимать около 5 МБ файлов
Инструменты JVM
Для измерения использования памяти в JVM есть несколько инструментов. Вы можете получить довольно много полезной информации из JConsole или JVisualVM (с помощью плагина JConsole, чтобы вы могли просматривать MBeans).
Использование кучи для нашего ванильного приложения — это зуб пилы, ограниченный сверху размером кучи, а ниже объемом памяти, используемым в состоянии покоя. Среднее значение составляет примерно 25 МБ для приложения под нагрузкой (и 22 МБ после ручного ГХ). JConsole также сообщает об использовании 50 МБ памяти без кучи (то же самое, что вы получаете от java.lang:type=MemoryMBean). Использование без кучи распадается на Metaspace: 32 МБ, сжатое пространство классов: 4 МБ, кэш кода: 13 МБ (эти числа можно получить из java.lang:type=MemoryPool,name=*MBeans). Существует 6200 классов и 25 потоков, в том числе несколько, которые добавляются инструментом мониторинга, который мы используем для их измерения.
Вот график использования кучи из неподвижного приложения под нагрузкой,
за которым следует ручная сборка мусора (двойной ник в
середине) и новое равновесие с меньшим использованием кучи.
Некоторые инструменты в JVM, кроме JConsole, также могут быть
интересны. Во-первых, это jpsполезно для получения
идентификатора процесса приложения, которое вы хотите проверить с помощью других инструментов:
$ jps
4289 Jps
4330 demo-0.0.1-SNAPSHOT.jarТогда у нас есть jmapгистограмма:
$ jmap -histo 4330 | head
num #instances #bytes class name
----------------------------------------------
1: 5241 6885088 [B
2: 21233 1458200 [C
3: 2548 1038112 [I
4: 20970 503280 java.lang.String
5: 6023 459832 [Ljava.lang.Object;
6: 13167 421344 java.util.HashMap$Node
7: 3386 380320 java.lang.ClassЭти данные имеют ограниченное использование, потому что вы не можете отследить «большие» объекты до их владельцев. Для этого вам нужен более полнофункциональный профилировщик, например, YourKit. YourKit выполняет агрегацию за вас и представляет список (хотя детали того, как это происходит, довольно неясны).
Статистика jmapзагрузчика классов может также показывать, и у нее есть способ проверить загрузчики классов в приложении. Он должен работать от имени пользователя root:
$ sudo ~/Programs/jdk1.8.0/bin/jmap -clstats 4330
Attaching to process ID 4330, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.60-b23
finding class loader instances ..done.
computing per loader stat ..done.
please wait.. computing liveness....................................liveness analysis may be inaccurate ...
class_loader classes bytes parent_loader alive? type
<bootstrap>21233609965 null live<internal>
0x00000000f4b0d730114760x00000000f495c890deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
0x00000000f5a26120114830x00000000f495c890deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
0x00000000f52ba3a811472 null deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
0x00000000f5a3052018800x00000000f495c890deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
0x00000000f495c890397263629020x00000000f495c8f0deadorg/springframework/boot/loader/LaunchedURLClassLoader@0x0000000100060828
0x00000000f5b639b0114730x00000000f495c890deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
0x00000000f4b80a30114730x00000000f495c890deadsun/reflect/DelegatingClassLoader@0x0000000100009df8
...
total = 93630010405986 N/A alive=1, dead=92 N/AСуществует множество «мертвых» записей, но есть также предупреждение о том, что информация о живучести не является точной. Ручной GC не избавляется от них.
Инструменты памяти ядра
Можно подумать, что операционная система Linux обеспечит достаточно глубокое понимание запущенного процесса, и это так, но процессы Java, как известно, трудно анализировать. Эта популярная ссылка SO говорит о некоторых проблемах в целом. Давайте посмотрим на некоторые из доступных инструментов и посмотрим, что они говорят нам о нашем приложении.
Прежде всего, это старый добрый psинструмент (инструмент, который вы используете для просмотра процессов в командной строке). Вы можете получить много той же информации от top. Вот наш процесс подачи заявления:
$ ps -au
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
dsyer 4330 2.4 2.1 2829092 169948 pts/5 Sl 18:03 0:37 java -Xmx32m -Xss256k -jar target/demo-0.0.1-SNAPSHOT.jar
...Значения RSS (Resident Set Size) находятся в диапазоне 150-190 МБ в соответствии с ps. Существует инструмент под названием, smemкоторый должен дать более дезинфицированный вид и точно отразить не разделяемую память, но значения там (например, PSS) не так уж отличаются. Интересно, что значения PSS для не-JVM процесса обычно * значительно * ниже, чем RSS, тогда как для JVM они сравнимы. JVM очень завидует своей памяти.
Инструмент более низкого уровня pmap, где мы можем посмотреть на
распределение памяти, назначенное процессу. Числа от pmap, кажется, не
имеют большого смысла либо:
$ pmap 4330
0000000000400000 4K r-x-- java
0000000000600000 4K rw--- java
000000000184c000 132K rw--- [ anon ]
00000000fe000000 36736K rw--- [ anon ]
00000001003e0000 1044608K ----- [ anon ]
...
00007ffe2de90000 8K r-x-- [ anon ]
ffffffffff600000 4K r-x-- [ anon ]
total 3224668Kто есть более 3 ГБ для процесса, который, как мы знаем, использует только 80 МБ. Просто подсчет записей «—–» дает вам почти все 3 ГБ. По крайней мере, это согласуется с номерами VSZ ps, но не очень полезно для управления мощностью.
Кто-то заметил, что значения RSS были точными на его компьютере, что интересно. Они определенно не работают для меня (Ubuntu 14.04 на Lenovo Thinkpad). Кроме того, вот еще одна интересная статья о статистике памяти JVM в Linux .
Масштабировать процессы
Хорошая проверка того, сколько памяти фактически используется процессом, состоит в том, чтобы продолжать запускать их больше, пока операционная система не начнет разрушаться. Например, чтобы запустить 40 одинаковых ванильных процессов:
$ for f in {8080..8119}; do (java -Xmx32m -Xss256k -jar target/demo-0.0.1-SNAPSHOT.jar --server.port=$f 2>&1 > target/$f.log &); doneВсе они конкурируют за ресурсы памяти, поэтому для их запуска требуется некоторое время, что вполне справедливо. Как только они все начинают, они обслуживают свои домашние страницы довольно эффективно (задержка 51 мс по дрянной локальной сети на 99-м процентиле). После того, как они запущены, остановка и запуск одного из процессов происходит относительно быстро (несколько секунд, а не несколько минут).
Числа VSZ за psпределами шкалы (как и ожидалось). Номера RSS тоже выглядят высоко:
$ ps -au
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
dsyer 27429 2.4 2.1 2829092 169948 pts/5 Sl 18:03 0:37 java -Xmx32m -Xss256k -jar target/demo-0.0.1-SNAPSHOT.jar --server.port=8081
dsyer 27431 3.0 2.2 2829092 180956 pts/5 Sl 18:03 0:45 java -Xmx32m -Xss256k -jar target/demo-0.0.1-SNAPSHOT.jar --server.port=8082
...Значения RSS по-прежнему находятся в диапазоне 150-190 МБ. Если бы все 40 процессов независимо использовали это большое количество памяти, которое составляло бы 6,8 ГБ, что вырвало бы мой 8 ГБ ноутбук из воды. Он работает нормально, поэтому большая часть этого значения RSS на самом деле не зависит от других процессов.
Пропорциональный общий размер (PSS), smemвозможно, лучше оценивает фактическое использование памяти, но на самом деле он не отличается от значений RSS:
$ smem
PID User Command Swap USS PSS RSS
...
27435 dsyer java -Xmx32m -Xss256k -jar 0 142340 142648 155516
27449 dsyer java -Xmx32m -Xss256k -jar 0 142452 142758 155568
...
27441 dsyer java -Xmx32m -Xss256k -jar 0 175156 175479 188796
27451 dsyer java -Xmx32m -Xss256k -jar 0 175256 175579 188900
27463 dsyer java -Xmx32m -Xss256k -jar 0 179592 179915 193224 Мы можем выдвинуть гипотезу о том, что, возможно, число PSS по-прежнему сильно завышено в общей доступной только для чтения памяти (например, сопоставленные файлы JAR).
40 процессов в значительной степени заполнили доступную память на моем ноутбуке (3,6 ГБ до запуска приложений), и происходило некоторое подкачка, но не так много. Мы можем превратить это в оценку размера процесса: 3,6 ГБ / 40 = 90 МБ. Недалеко от оценки JConsole.
Java-приложение «Ничего не делай»
В качестве полезного сравнения давайте создадим действительно базовое Java-приложение, которое остается в живых при запуске, чтобы мы могли измерить потребление памяти:
public class Main throws Exception {
public static void main (String[] args) {
System.in.read();
}
}Результаты: куча 6 МБ, не куча 14 МБ (кэш-память кода 4 МБ, сжатое пространство классов 1 МБ, Metaspace 9 МБ), 1500 классов. Вряд ли какие-либо классы загружены, так что нет ничего удивительного.
Spring Boot App — Ничего не делай
Теперь предположим, что мы делаем то же самое, но также загружаем контекст приложения Spring:
@SpringBootApplication
public class MainApplication implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
System.in.read();
}
public static void main(String[] args) throws Exception {
SpringApplication.run(MainApplication.class, args);
}
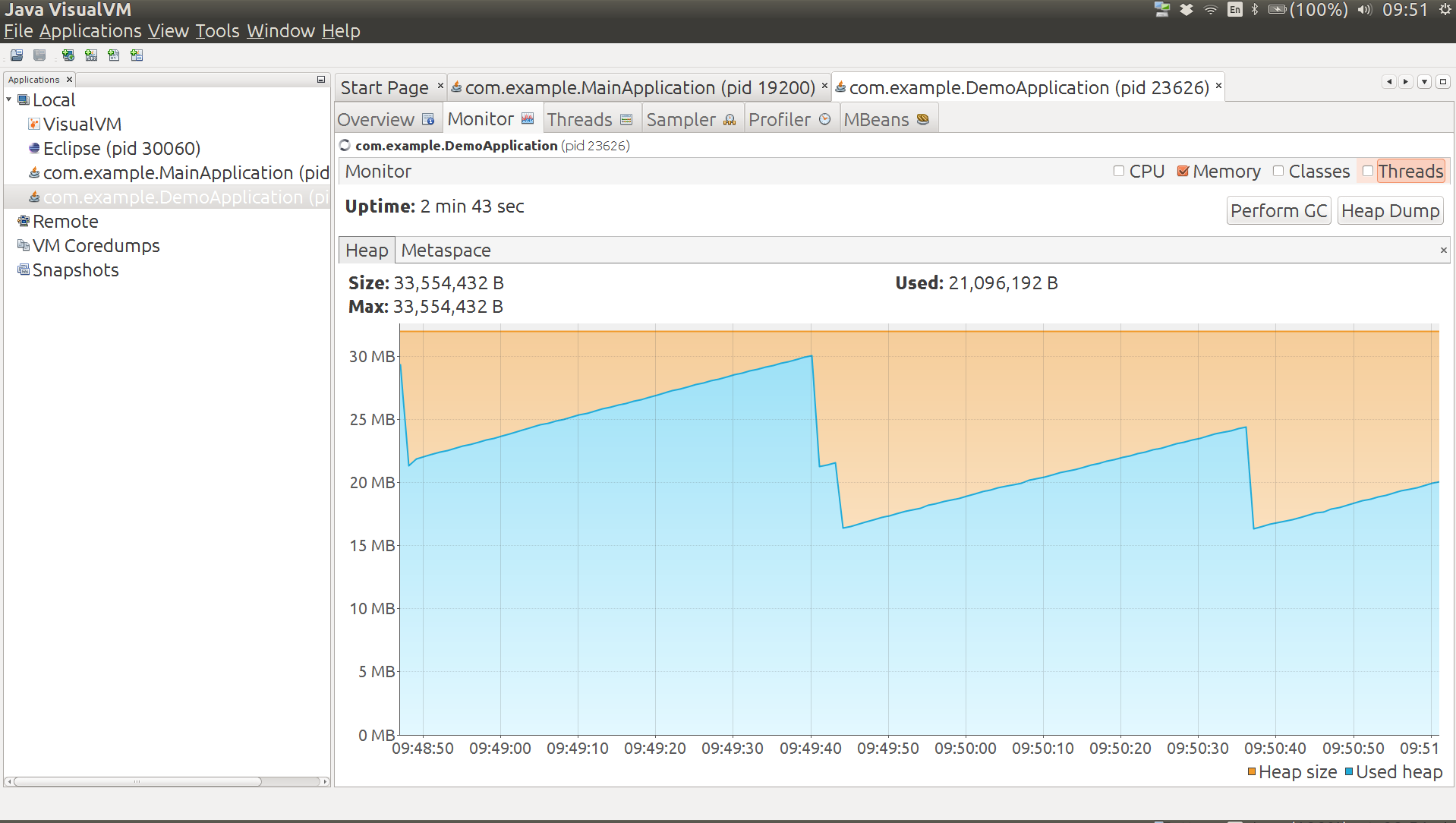
}Куча 12 МБ (но после ручного GC уменьшается до 6 МБ), не кучи 26 МБ (кэш-память кода 7 МБ, сжатое пространство классов 2 МБ, Metaspace 17 МБ), 3200 классов. На графике ниже показано использование кучи от запуска приложения до конечного состояния. Большая капля в середине — это ручной GC, и вы можете видеть, что после этого приложение стабилизируется на другом пильном зубе.
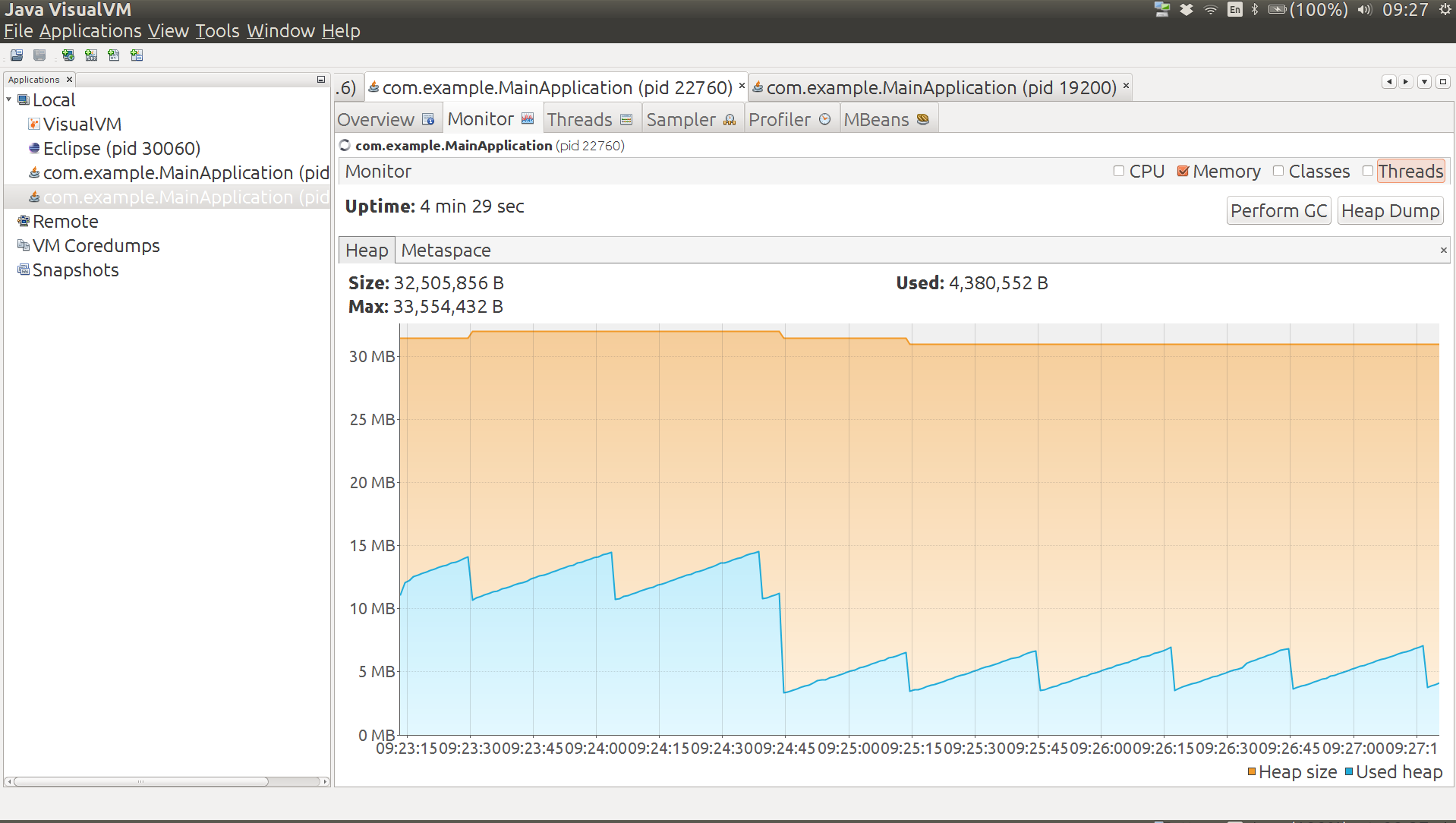
Добавляет ли Spring Boot (в отличие от Spring) много накладных расходов в это приложение? Для начала, мы можем проверить это, удалив @SpringBootApplicationаннотацию. Это означает, что мы загружаем контекст, но не выполняем автоконфигурацию. Результат: куча 11 МБ (уменьшается до 5 МБ после ручного ГХ), 22 МБ без кучи (кэш-память 5 МБ, сжатое пространство классов 2 МБ, Metaspace 15 МБ), 2700 классов. Премиум автоконфигурации Spring Boot, измеренный таким образом, составляет около 1 МБ кучи и 4 МБ без кучи.
Идя дальше, мы можем создать контекст приложения Spring вручную, вообще не используя код Spring Boot. При этом использование кучи снижается до 10 МБ (уменьшается до 5 МБ после ручного GC), без использования кучи до 20 МБ (кэш-память 5 МБ, сжатое пространство классов 2 МБ, Metaspace 13 МБ), 2400 классов. Общий объем Spring Boot, измеренный таким образом, составляет менее 2 МБ кучи и около 6 МБ памяти без кучи.
Ratpack Groovy App
Простое приложение Ratpack Groovy можно создать с помощью лентяев :
$ lazybones create ratpack .
$ ./gradlew build
$ unzip build/distributions/ratpack.zip
$ JAVA_OPTS='-Xmx32m -Xss256k' ./ratpack/bin/ratpack$ ls -l build/distributions/ratpack/lib/*.jar | awk '{tot+=$5;} END {print tot}'
16277607Используемая куча довольно низкая для начала (13 МБ), со временем она увеличивается до 22 МБ. Metaspace составляет около 34 МБ. JConsole сообщает об использовании без кучи 43 МБ. Есть 31 темы.
Java-приложение Ratpack
Вот действительно простое статическое приложение:
import ratpack.server.BaseDir;
import ratpack.server.RatpackServer;
public class DemoApplication {
public static void main(String[] args) throws Exception {
RatpackServer.start(s -> s
.serverConfig(c -> c.baseDir(BaseDir.find()))
.handlers(chain -> chain
.all(ctx -> ctx.render("root handler!"))
)
);
}
}Он загружается примерно в 16 МБ кучи, 28 МБ без кучи в виде фляги Spring Boot. Как обычное приложение Gradle, оно немного легче в куче (кешированные файлы не нужны), но использует ту же память без кучи. Есть 30 тем. Интересно, что нет объекта размером более 300 КБ, в то время как наши приложения Spring Boot с Tomcat обычно имеют 10 или более объектов выше этого уровня.
Вариации в приложении Vanilla
Запуск из разобранной банки сбрасывает до 6 МБ кучи (разница заключается в том, что данные кэша хранятся в лаунчере). Также делает запуск немного быстрее: менее 5 с по сравнению с 7 с, когда память ограничена толстой флягой.
Укороченная версия приложения без статических ресурсов или веб-файлов работает с кучей 23 МБ и 41 МБ без кучи в виде развернутого архива (запускается менее чем за 3 секунды). Использование без кучи разбивается на метапространство: 35 МБ, сжатое пространство классов: 4 МБ, кэш-память кода: 4 МБ. Spring ReflectionUtilsпрыгает к вершине диаграммы памяти в YourKit с Spring 4.2.3 (2-й только для Tomcat NioEndpoint). Они ReflectionUtilsдолжны уменьшаться под давлением памяти, но на практике это не происходит, поэтому Spring 4.2.4 очищает кеши после запуска контекста, что приводит к некоторой экономии памяти (примерно до 20 МБ кучи). DefaultListableBeanFactoryопускается до 3-го места и почти вдвое меньше, чем было с цепочкой ресурсов (локатор webjars), но больше не будет уменьшаться без удаления дополнительных функций.
In turns out that the NioEndpoint has a 1MB “oom parachute” that it holds onto until it detects an OutOfMemoryError. You can customize it to zero and forgo the parachute to save an extra MB of heap, e.g:
@SpringBootApplication
public class SlimApplication implements EmbeddedServletContainerCustomizer {
@Override
public void customize(ConfigurableEmbeddedServletContainer container) {
if (container instanceof TomcatEmbeddedServletContainerFactory) {
TomcatEmbeddedServletContainerFactory tomcat = (TomcatEmbeddedServletContainerFactory) container;
tomcat.addConnectorCustomizers(connector -> {
ProtocolHandler handler = connector.getProtocolHandler();
if (handler instanceof Http11NioProtocol) {
Http11NioProtocol http = (Http11NioProtocol) handler;
http.getEndpoint().setOomParachute(0);
}
});
}
}
...
}Using Jetty instead of Tomcat makes no difference whatsoever to the overall memory or heap, even though the NioEndpoint is high on the “Biggest objects” list in YourKit (takes about 1MB), and there is no corresponding blip for Jetty. It also doesn’t start up any quicker.
As an example of a “real” Spring Boot app, Zipkin (Java) runs fine with with -Xmx32m -Xss256k, at least for short periods. It settles with a heap of about 24MB and non-heap about 55MB.
The spring-cloud-stream sample sink (with Redis transport) also runs fine with -Xmx32m -Xss256k and similar memory usage profile (i.e. roughly 80MB total). The actuator endpoints are active but don’t do much to the memory profile. Slightly slower startup maybe.
Tomcat Container
Instead of using the emedded container in Spring Boot, what if we deploy a traditional war file to a Tomcat container?
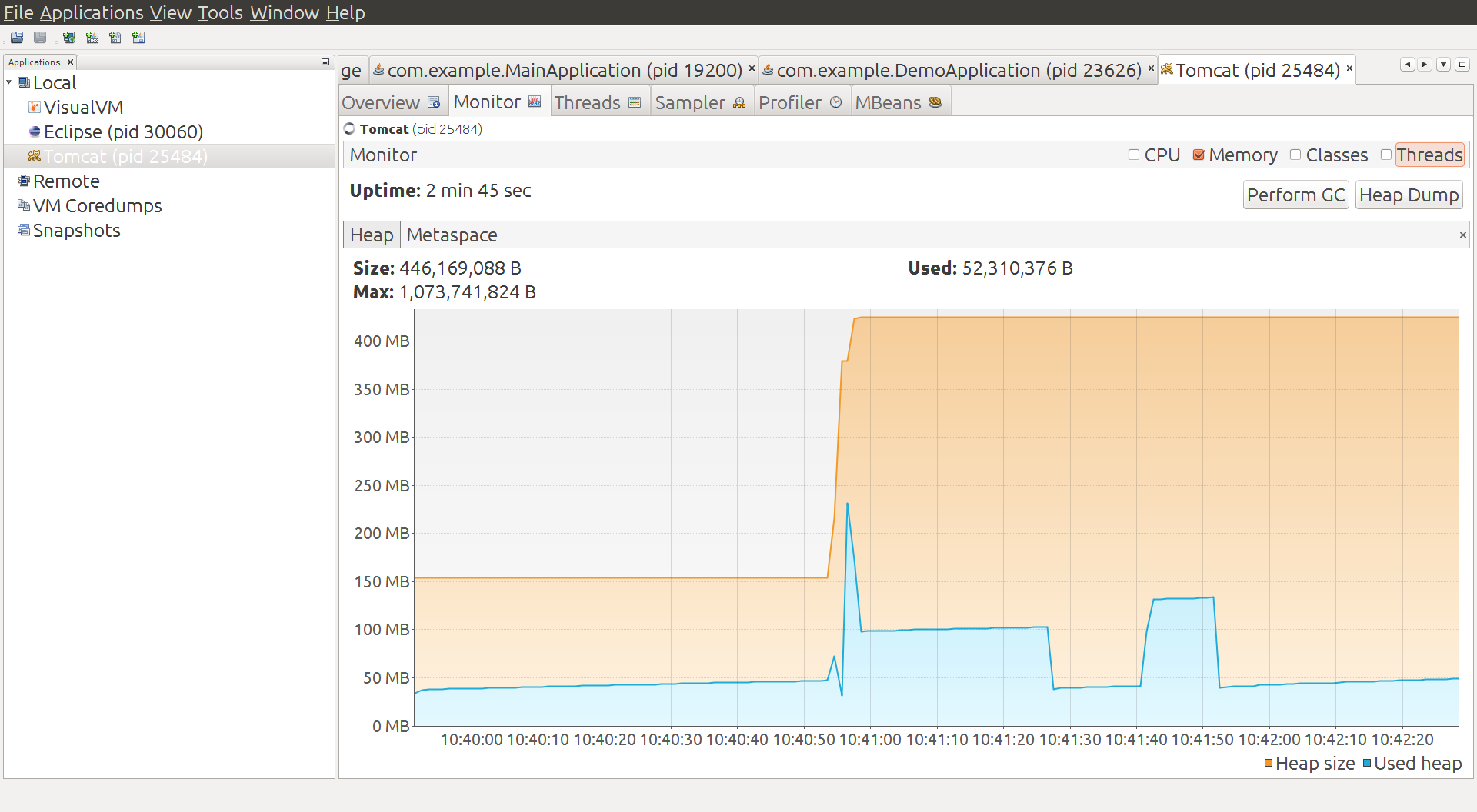
The container starts and warms up a bit and uses of order 50MB heap, and 40MB non-heap. Then we deploy a war of the vanilla Spring Boot app, and there’s a spike in heap usage, which settles down to about 100MB. We do a manual GC and it drops down to below 50MB, and then add some load and it jumps up to about 140MB. A manual GC drops it back down to below 50MB. So we have no reason to believe this app is really using much if any additional heap compared to the container. It uses some when under load, but it can always reclaim it under GC pressure.
Metaspace, however tells a different story, it goes up from 14MB to 41MB in the single app under load. Total non-heap usage is reported at 59MB in the final state.
Deploy Another Application
If we add another copy of the same application to the Tomcat container, trough heap consumption goes up a bit (above 50MB) and metaspace is up to 55MB. Under load heap usage jumps to 250MB or so, but always seems to be reclaimable.
Then we add some more apps. With six apps deployed the metaspace is up to 115MB and total non-heap to 161MB. This is consistent with what we saw for a single app: each one costs us about 20MB non-heap memory. Heap usage hits 400MB under load, so this doesn’t go up proportionally (however it is being managed from above, so maybe that’s not surprising). The trough of heap usage is up to about 130MB, so the cumulative effect of adding apps on the heap is visible there (about 15MB per app).
When we constrain Tomcat to the same amount of heap that the six apps would have in our vanilla embedded launch (-Xmx192m) the heap under load is more or less at its limit (190MB), and the trough after a manual GC is 118MB. Non-heap memory is reported as 154MB. The heap trough and non-heap usage is not identical but consistent with the unconstrained Tomcat instance (which actually had a 1GB heap). Compared to the embedded containers the total memory usage, including the full heap, is a bit smaller because some of the non-heap memory is apparently shared between apps (344MB compared to 492MB). For more realistic apps that require more heap themselves the difference will not be proportionally as big (50MB out of 8GB is negligible). Also any app that manages its own thread pool (not uncommon in real life Spring applications) will incur an additional non-heap memory penalty for the threads it needs.
Rule of Thumb Process Sizes
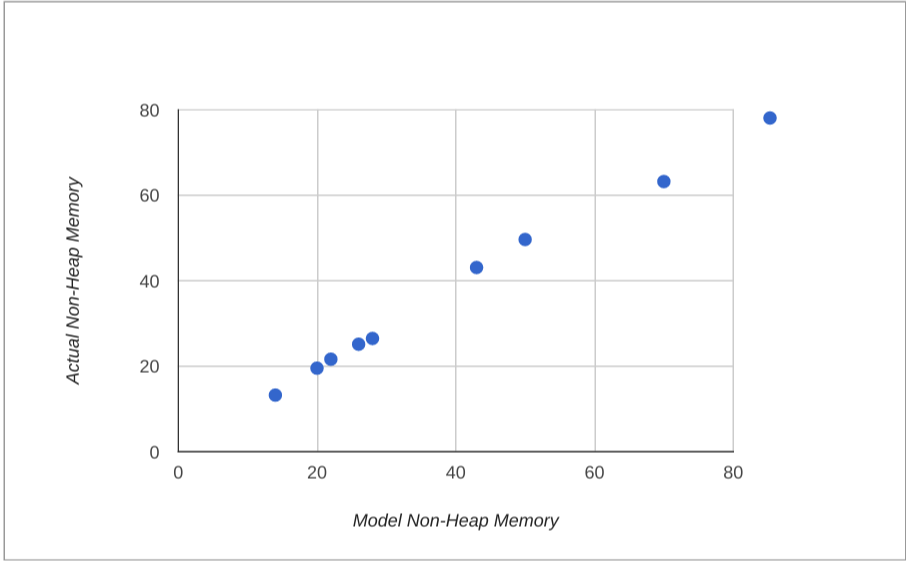
A very rough estimate for actual memory usage would be the heap size plus 20 times the stack size (for the 20 threads typical in a servlet container), plus a bit, so maybe 40MB per process in our vanilla app. That estimate is a bit low, given the JConsole numbers (50MB plus the heap, or 82MB). We can observe, though, that the non-heap usage in our apps is roughly proportional to the number of classes loaded. Once you correct for the stack size the correlation improves, so a better rule of thumb might be one that is proportional to the number of classes loaded:
memory = heap + non-heap
non-heap = threads x stack + classes x 7/1000
The vanilla app loads about 6000 classes and the do nothing Java main loads about 1500. The estimate is accurate for the vanilla app and the do nothing Java app.
Adding Spring Cloud Eureka discovery only loads about another 1500 classes, and uses about 40 threads, so it should use a bit more non-heap memory, but not a lot (and indeed it does use about 70MB with 256KB stacks, where the rule of thumb would predict 63MB).
The performance of this model for the apps we measured is shown below:
Summary of Data
Application Heap (MB) Non Heap (MB) Threads Classes Vanilla 22 50 25 6200 Plain Java 6 14 11 1500 Spring Boot 6 26 11 3200 No Actuator 5 22 11 2700 Spring Only 5 20 11 2400 Eureka Client 80* 70 40 7600 Ratpack Groovy 22 43 24 5300 Ratpack Java 16 28 22 3000
* Only the Eureka client has a larger heap: all the others are set
explicitly to -Xmx32m.
Conclusions
The effect Spring Boot on its own has on a Java application is to use a bit more heap and non-heap memory, mostly because of extra classes it has to load. The difference can be quantified as roughly an extra 2MB heap and 12MB non-heap. In a real application that might consume many times as much for actual business purposes this is pretty insignificant. The difference between vanilla Spring and Spring Boot is a few MB total (neither here nor there really). The Spring Boot team have only just started measuring things in this level of detail so we can probably expect optimizations in the future anyway. When we compare memory usage for apps deployed in a single Tomcat container with the same apps deployed as independent processes, not surprisingly the single container packs the apps more densely in memory. The penalty for a standalone process is mainly related to non-heap usage though, which adds up to maybe 30MB per app when the number of apps is much larger than the number of containers (and less otherwise). We wouldn’t expect this to increase as apps use more heap, so in most real apps it is not significant. The benefits of deploying an app as an independent process following the twelve-factor and Cloud Native principles outweigh the cost of using a bit more memory in our opinion. As a final note, we observe that the native tools in the operating system are not nearly as good as the ones provided by the JVM, when you want to inspect a process and find out about its memory usage.