Недавно я столкнулся с очень интересным вопросом о переполнении стека неназванным пользователем . Вопрос был в том, чтобы сгенерировать таблицу следующей формы в Oracle, используя табличную функцию:
|
1
2
3
4
5
6
|
Description COUNT-------------------TEST1 10 TEST2 15TEST3 25TEST4 50 |
Логика, которая должна быть реализована для столбца COUNT, заключается в следующем:
- ТЕСТ 1: количество работников, чья соляная стоимость <10000
- ТЕСТ2: количество сотрудников, чей отдел> 10
- ТЕСТ3: количество сотрудников, чей штат> (SYSDATE-60)
- TEST4: количество сотрудников, чья оценка = 1
Вызов принят!
Для этого упражнения предположим следующую таблицу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
CREATE TABLE employees ( id NUMBER(18) NOT NULL PRIMARY KEY, sal NUMBER(18, 2) NOT NULL, dept NUMBER(18) NOT NULL, hiredate DATE NOT NULL, grade NUMBER(18) NOT NULL);INSERT INTO employees VALUES (1, 10000, 1, SYSDATE , 1);INSERT INTO employees VALUES (2, 9000, 5, SYSDATE - 10, 1);INSERT INTO employees VALUES (3, 11000, 13, SYSDATE - 30, 2);INSERT INTO employees VALUES (4, 10000, 12, SYSDATE - 80, 2);INSERT INTO employees VALUES (5, 8000, 7, SYSDATE - 90, 1); |
Как рассчитать значения COUNT
На первом шаге мы рассмотрим, как наилучшим образом рассчитать значения COUNT. Самый простой способ — вычислить значения в отдельных столбцах, а не в строках. Новички в SQL, вероятно, прибегнут к каноническому решению с использованием вложенных команд SELECT, что очень плохо по причинам производительности:
|
01
02
03
04
05
06
07
08
09
10
|
SELECT (SELECT COUNT(*) FROM employees WHERE sal < 10000) AS test1, (SELECT COUNT(*) FROM employees WHERE dept > 10) AS test2, (SELECT COUNT(*) FROM employees WHERE hiredate > (SYSDATE - 60)) AS test3, (SELECT COUNT(*) FROM employees WHERE grade = 1) AS test4FROM dual; |
Почему запрос не оптимален? Существует четыре доступа к таблицам, чтобы найти все данные:
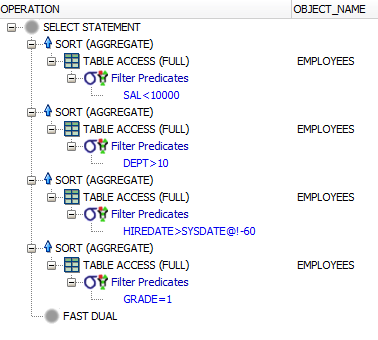
Если вы добавляете индекс к каждому отдельному фильтруемому столбцу, есть шанс, по крайней мере, оптимизировать отдельные подзапросы, но для отчетов такого типа случайное полное сканирование таблицы вполне подойдет, особенно если вы объединяете много данных.
Даже если не оптимально по скорости, вышеупомянутое дает правильный результат:
|
1
2
3
|
TEST1 TEST2 TEST3 TEST4-----------------------------2 2 3 3 |
Как улучшить запрос, тогда?
Мало кто знает о том, что агрегатные функции агрегируют только NULL значения. Это не имеет никакого эффекта, когда вы пишете COUNT(*) , но когда вы передаете выражение в функцию COUNT(expr) , это становится намного интереснее!
Идея заключается в том, что вы используете выражение CASE которое преобразует оценку TRUE каждого предиката в значение, отличное от NULL , а оценку FALSE (или NULL ) в NULL . Следующий запрос иллюстрирует этот подход
|
01
02
03
04
05
06
07
08
09
10
|
SELECT COUNT(CASE WHEN sal < 10000 THEN 1 END) AS test1, COUNT(CASE WHEN dept > 10 THEN 1 END) AS test2, COUNT(CASE WHEN hiredate > (SYSDATE-60) THEN 1 END) AS test3, COUNT(CASE WHEN grade = 1 THEN 1 END) AS test4FROM employees; |
… и снова дает правильный результат:
|
1
2
3
|
TEST1 TEST2 TEST3 TEST4-----------------------------2 2 3 3 |
Использование FILTER () вместо CASE
Стандарт SQL и потрясающая база данных PostgreSQL предлагают еще более удобный синтаксис для вышеуказанной функциональности. Малоизвестное предложение FILTER() для агрегатных функций .
В PostgreSQL вы должны написать вместо этого:
|
01
02
03
04
05
06
07
08
09
10
|
SELECT COUNT(*) FILTER (WHERE sal < 10000) AS test1, COUNT(*) FILTER (WHERE dept > 10) AS test2, COUNT(*) FILTER (WHERE hiredate > (SYSDATE - 60)) AS test3, COUNT(*) FILTER (WHERE grade = 1) AS test4FROM employees; |
Это полезно, когда вы хотите четко отделить критерии FILTER() от любого другого выражения, которое вы хотите использовать для агрегирования. Например, при расчете SUM() .
В любом случае, запрос теперь должен попасть в таблицу только один раз. Агрегирование может быть выполнено полностью в памяти.
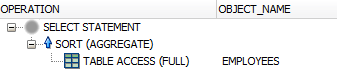
Это всегда лучше, чем предыдущий подход, если только у вас нет индекса для каждой агрегации!
ХОРОШО. Теперь, как получить результаты в строках?
Вопрос о переполнении стека хотел получить результат, TESTn значения TESTn помещаются в отдельные строки, а не в столбцы.
|
1
2
3
4
5
6
|
Description COUNT-------------------TEST1 2TEST2 2TEST3 3TEST4 3 |
Опять же, есть канонический, не очень производительный подход, чтобы сделать это с помощью UNION ALL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
SELECT 'TEST1' AS Description, COUNT(*) AS COUNTFROM employees WHERE sal < 10000UNION ALLSELECT 'TEST2', COUNT(*)FROM employees WHERE dept > 10UNION ALLSELECT 'TEST3', COUNT(*) FROM employees WHERE hiredate > (SYSDATE - 60)UNION ALLSELECT 'TEST4', COUNT(*) FROM employees WHERE grade = 1 |
Этот подход более или менее эквивалентен вложенному подходу выбора, за исключением транспонирования столбца / строки («разворачивание»). И план тоже очень похож
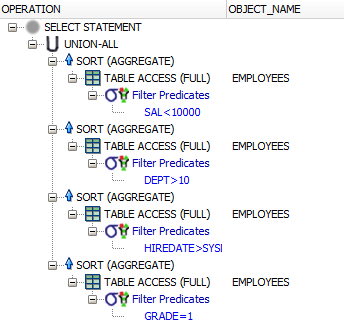
Транспозиция = (не) поворот
Обратите внимание, как я использовал термин «транспонировать». Это то, что мы сделали, и у него есть название: (не) поворот. Мало того, что у него есть имя, но эта функция также поддерживается в Oracle и SQL Server PIVOT после UNPIVOT ключевые слова PIVOT и UNPIVOT которые можно размещать после ссылок на таблицы.
-
PIVOTтранспонирует строки в столбцы -
UNPIVOTтранспонирует столбцы обратно в строки
Итак, мы возьмем оригинальное оптимальное решение и перенесем его в UNPIVOT
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
SELECT *FROM ( SELECT COUNT(CASE WHEN sal < 10000 THEN 1 END) AS test1, COUNT(CASE WHEN dept > 10 THEN 1 END) AS test2, COUNT(CASE WHEN hiredate > (SYSDATE-60) THEN 1 END) AS test3, COUNT(CASE WHEN grade = 1 THEN 1 END) AS test4 FROM employees) tUNPIVOT ( count FOR description IN ( "TEST1", "TEST2", "TEST3", "TEST4" )) |
Все, что нам нужно сделать, это обернуть исходный запрос в производную таблицу t (т. UNPIVOT SELECT в предложении FROM ), а затем « UNPIVOT » этой таблицы t , генерируя столбцы count и description . Результат, опять же:
|
1
2
3
4
5
6
|
Description COUNT-------------------TEST1 2TEST2 2TEST3 3TEST4 3 |
План выполнения по-прежнему оптимален. Все действие происходит в памяти.
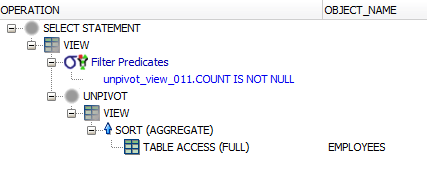
Вывод
PIVOT и UNPIVOT являются очень полезными инструментами для отчетности и реорганизации данных. Есть много вариантов использования, таких как выше, где вы хотите реорганизовать некоторые агрегаты. Другие варианты использования включают таблицы настроек или свойств, которые реализуют модель значений атрибутов сущности , и вы хотите преобразовать атрибуты из строк в столбцы ( PIVOT ) или из столбцов в строки ( UNPIVOT )
Заинтригованный? Читайте о PIVOT здесь:
- Вы уже используете SQL PIVOT? Вам следует!
- Как использовать SQL PIVOT для сравнения двух таблиц в вашей базе данных
- Awesome PostgreSQL 9.4 / SQL: 2003 FILTER для агрегатных функций
| Ссылка: | Произведите впечатление на ваших коллег с помощью SQL UNPIVOT! от нашего партнера JCG Лукаса Эдера в блоге JAVA, SQL и JOOQ . |