В этой статье я поделюсь своим опытом классификации неструктурированных данных в URL. Я решил применить алгоритм TF-IDF для решения этой проблемы и подумал, что поделиться опытом будет интересно.
Эта статья посвящена исключительно решению проблем, но поскольку используемый контекст связан с Plumbr, то сначала немного информации для читателей, незнакомых с Plumbr:
- Plumbr отслеживает взаимодействие конечных пользователей с приложениями. Каждое из таких взаимодействий называется транзакцией
- Транзакции группируются по фактическому потреблению конечной точки . Например, если пользователь нажал кнопку «Добавить в корзину» в веб-приложении, конечная точка, извлеченная из такого URL-адреса, может быть «/ cart / add / {item}». Эти конечные точки называются сервисами .
Plumbr также раскрывает основную причину в исходном коде для ситуаций, когда транзакция, потребляющая определенную службу, либо дает сбой, либо медленнее, чем ожидалось. Являясь ключевым преимуществом для пользователей Plumbr, эта часть продукта никак не связана с содержанием этого поста; так что не стесняйтесь забыть об этой функции.
Как полное раскрытие: пост суммирует мою недавно законченную магистерскую диссертацию в Comp. Sci. институт в Тартуском университете . Помимо получения степени в университете, я также являюсь членом команды инженеров в Пламбре, поэтому было вполне естественно, что я связал свою работу и исследования, чтобы получить выгоду на обоих направлениях.
Проблема
Проблема, с которой я столкнулся, была связана с сопоставлением транзакций с реальными услугами. Чтобы понять проблему, давайте рассмотрим пример.
Давайте создадим веб-приложение, доступное конечным пользователям через традиционные методы HTTP GET / POST по адресу http://www.example.com . Фактические транзакции, попадающие в это приложение, могут выглядеть следующим образом:
- http://www.example.com/invoices/12345?action=pay
- http://www.example.com/invoices/98765?action=pay
- http://www.example.com/invoices/search?from=01-01-2015
- http://www.example.com/invoices/search?from=01-01-2015&to=31-01-2015
Для читателя очевидно, что четыре транзакции, указанные выше, обращаются к двум различным сервисам. Первые две транзакции — это попытки оплаты счетов-фактур «12345» и «98765», а две последние — поиск счетов-фактур в течение определенного периода времени.
Проблема сейчас стоит прямо на нас. Так как идентификатор конкретного ресурса или параметров в URL-адресе имеет тенденцию изменяться, то наивный подход простого применения сравнения строк не даст нам ничего, кроме самых простых приложений.
Чтобы быть уверенным в том, действительно ли это так, я провел тест набора данных из реальных производственных развертываний Plumbr. Тест применял наивную группировку транзакций к сервисам по контролируемому приложению.
Это привело к четкому подтверждению моих гипотез, так как в 39,5% приложений обнаружилось более 5000 обнаруженных сервисов. В 11,6% заявок количество сервисов превысило 50 000.
Это подтверждает наши ожидания. Никто в здравом уме не должен рассматривать возможность объединения даже 500 различных функций в одно приложение, не говоря уже о 5000 или 50000.
Решение
Подтвердив наличие проблемы, я теперь должен был убедиться, что всякий раз, когда транзакция имеет какую-либо динамическую часть в URL, такую как параметр или идентификатор ресурса, мы сможем идентифицировать динамические разделы из URL и правильно сгруппировать транзакции.
Таким образом, требования к предстоящему анализу данных можно агрегировать как:
- Различают «динамические» и «статические» части в URL.
- Нормализуйте URL-адреса, удалив из них динамические части.
- Генерируйте имя службы из нормализованных URL-адресов, которые по-прежнему будут иметь достаточную семантику, чтобы люди могли понять, что это был за сервис.
- Генерация регулярных выражений, группирующих URL к сервисам.
Подготовка данных
Перед описанием фактического используемого алгоритма, давайте рассмотрим одну из задач, которые необходимо было решить перед фактическим анализом. Чтобы начать определять динамические и статические части по URL, нам нужно было токенизировать URL. Затем можно использовать токенизированные URL для сравнения каждой части URL при определении динамических и статических частей.
Поначалу кажется легкой задачей. Наивного подхода к токенизации при каждом прямом слэше и амперсандах было явно недостаточно, поскольку менее половины приложений в наборе данных форматировали URL-адреса, используя только косые черты и амперсанды. В оставшейся половине приложений использовались действительно разные подходы. Чтобы дать вам представление, просто посмотрите на следующие примеры, полученные из реального набора данных:
- http://www.example.com/invoices.pay.12345
- http://www.example.com/invoices-pay-12345
- http://www.example.com/invoices/pay&id=12345
Очевидно, что, несмотря на популярность стандартов REST, дизайн URL зависит от конкретного приложения, и нет гарантии, что характеристики, применимые к одному приложению, будут одинаковыми для другого.
Таким образом, я закончил с извлечением набора известных разделителей из данных, к которым у меня был доступ, и запустил алгоритм выбора правильного разделителя для каждого приложения. Критерии отбора основывались на выборе разделителя, появляющегося в более чем 90% случаев для предстоящего анализа.
Выбор алгоритма
Теперь, когда URL-адреса были токенизированы, нам нужен был способ категоризации полностью неструктурированных и непредсказуемых данных. Такая категоризация создаст основу для динамического / статического обнаружения токенов. Алгоритм выбора был довольно прост, отогнав задачу к классификации. Я реализовал популярный алгоритм анализа текста и поиска информации под названием TF-IDF, используя модель программирования MapReduce .
TF-IDF — это комбинация двух статистических методов: TF — Term Frequency и IDF — Inverse Document Frequency. Основное преимущество оценки TF-IDF состоит в том, что ее значение увеличивается с соответствующим числом раз, когда слово появляется в документе, но компенсируется появлением слова в коллекции документов. Это помогает подтвердить тот факт, что некоторые слова в наших частях URL-адреса появляются чаще. Существуют многочисленные вариации для TF и IDF с разными методами расчета баллов. Рисунки 1 и 2 ( любезно предоставленные Викимедиа ) иллюстрируют несколько вариантов адаптации для расчета баллов TF и IDF соответственно.


Что касается этого поста в блоге, мы должны рассматривать URL как текстовый документ без какой-либо предопределенной структуры. Для большей наглядности давайте проанализируем текстовый пример для книг. Предположим, мы хотим найти список наиболее важных слов в 10 книгах, поэтому, когда я набираю определенное слово, я хочу выбрать книгу, в которой это слово кажется наиболее «релевантным». Например, если я напишу слово «оружейный стрелок», я бы хотел увидеть « Темную башню: стрелок » Стивена Кинга.
В этом случае мы хотим исключить часто используемые слова, такие как: «и», «или», «с» и т. Д. Мы можем выполнить эту задачу, вычисляя частоту термина, используя формулу необработанной частоты вместе с частотой обратного документа. Единственное, что нам нужно, это разделитель для слов, и, насколько мы уже знаем из книг, это обычно пробел.
Если вычисленная оценка близка к 0, это означает, что данное слово редко встречается в книгах, что означает, что оно может быть помечено как специфическое для определенной книги. С другой стороны, высокий балл показывает, что выбранное слово встречается в большинстве книг. Обычно такие слова, как: «и», «или», «с», имеют высокий балл TF-IDF.
Таким образом, мы можем думать о транзакциях в одном приложении, использующих разные URL-адреса, одинаково. Учитывая тот факт, что мы уже определили разделитель, мы можем вычислить оценку TF-IDF для каждой части URL для любого приложения, передав нам значение оценки. На основе этого значения мы можем классифицировать часть URL как динамическую или статическую.
TF-IDF с использованием MapReduce
На протяжении многих лет модель программирования MapReduce оправдывала свою эффективность для анализа текста, поиска информации и различных других больших задач обработки данных. На модель оказали влияние функции отображения и сгиба, обычно используемые практически в любом функциональном языке программирования. Программная модель MapReduce основана на парах ключ-значение, где map генерирует значения для определенного ключа, а значения для тех же ключей поступают в один и тот же редуктор. Но прежде чем углубляться в детали реализации MapReduce, нам нужно взглянуть на то, как выглядят функции map и fold в функциональном программировании.
Карта применяет данную функцию к каждому элементу списка и дает измененный список в качестве вывода.
|
1
|
map f lst: (’a -> ’b) -> (’a list) -> (’b list) |
Fold применяет данную функцию к одному элементу списка и к аккумулятору (начальное значение аккумулятора должно быть установлено заранее). После этого результат сохраняется в аккумуляторе, и это повторяется для каждого элемента в списке.
|
1
|
fold f acc lst: (acc -> ’a -> acc) -> acc -> (’a list) -> acc |
Давайте рассмотрим простой пример суммы квадратов с использованием функций map и fold. Как мы уже описали, Map применяет данную функцию к каждому элементу списка и дает нам измененный список. Для указанной выше задачи у нас есть список целых чисел, и мы хотим, чтобы каждое число было степенью двойки. Итак, наша функция карты будет выглядеть так:
|
1
2
3
|
(map (lambda (x) (* x x)) '(1 2 3 4 5)) → '(1 4 9 16 25) |
Что касается Fold, так как мы хотим иметь сумму элементов, нам нужно установить начальное значение аккумулятора в 0, и мы можем передать + как функцию.
|
1
|
(fold (+) 0 '(1 2 3 4 5)) → 15 |
Комбинация карты и сгиба для суммы квадратов будет выглядеть так:
|
1
2
3
4
|
(define (sum-of-squares v) (fold (+) 0 (map (lambda (x) (* x x)) v))) (sum-of-squares '(1 2 3 4 5)) → 55 |
Если мы думаем о расчете TF-IDF для URL-адресов, нам нужно применить данную функцию для каждого URL-адреса и сложить вычисленные результаты по предопределенным формулам, используя MapReduce. Чтобы рассчитать частоты терминов и частоты обратных документов, нам нужно сгенерировать данные для нескольких промежуточных этапов, таких как количество слов в каждом URL, общее количество слов в наборе URL и т. Д.
Поэтому вычисление всего в одной задаче MapReduce может быть огромным в плане разработки и реализации алгоритма. Чтобы решить эту проблему, мы можем разделить задачу на четыре взаимозависимых итерации MapReduce, это даст нам возможность выполнить пошаговый анализ набора данных, и во время последней итерации у нас будет возможность рассчитать оценку для каждой части URL в наборе данных. ,
Первая итерация MapReduce
Во время первой итерации MapReduce нам нужно разделить каждый URL на части и вывести каждую часть URL отдельно, где идентификатор URL и сама часть будут определены как ключи. Это даст возможность редуктору рассчитать общее вхождение определенной части URL в наборе данных.
Реализация будет похожа на:
Карта :
- Вход: (необработанный URL)
- Функция: Разделить URL на части и вывести каждый pert.
- Выходные данные: (urlPart; urlCollectionId, 1)
Уменьшить :
- Ввод: (urlPart; urlCollectionId, [count])
- Функция: Суммируйте все числа как n
- Выходные данные: (urlPart; urlCollectionId, n)
Вторая итерация MapReduce
Для второй итерации вход для функции карты является выходом первой итерации. Цель функции map — изменить значения ключей первой итерации, чтобы мы могли собирать количество раз, когда каждая часть URL появлялась в данной коллекции. Это даст возможность редуктору рассчитать количество общих членов в каждой коллекции.
Реализация будет примерно такой:
Карта :
- Ввод — (urlPart; urlCollectionId, n)
- Функция — нам нужно изменить ключ, чтобы он был только идентификатором коллекции, и переместить имя части URL в поле значения.
- Выход — (urlCollectionId, urlPart; n)
Уменьшить :
- Ввод — (urlCollectionId, [urlPart; n])
- Функция — Нам нужно сложить все n в коллекции URL как N и снова вывести каждую часть URL.
- Выход — (urlPart; urlCollectionId, n; N)
Третья итерация MapReduce
Цель третьей итерации — вычислить частоту части URL в коллекциях. Для этого нам нужно отправить в редуктор расчетные данные для конкретной части URL, поэтому функция map должна переместить urlCollectionId в поле значения, а ключ должен содержать только значение urlPart . После такой модификации редуктор может подсчитать, сколько раз urlPart появлялся в разных коллекциях.
Реализация будет похожа на:
Карта :
- Ввод — (urlPart; urlCollectionId, n; N)
- Функция — Переместить urlCollectionId в поле значения
- Выход — (urlPart, urlCollectionId; n; N; 1)
Уменьшить :
- Ввод — (urlPart, [urlCollectionId; n; N; 1])
- Функция — Рассчитать общее количество urlParts в коллекции как m . Переместить urlCollectionId обратно в ключевое поле
- Выход — (urlPart; urlCollectionId, n; N; m)
Четвертая итерация MapReduce
На данный момент у нас будут все необходимые данные для расчета частоты терминов и частоты инвертирования документов для каждой части URL, такие как:
- n — Сколько раз указанная часть URL появлялась в коллекции
- N — количество вхождений данной части URL в разных коллекциях URL.
- m — общее количество частей URL в коллекции.
Для TF мы будем использовать следующую формулу:
![]()
Где f представляет количество раз, когда данное слово появилось в документе. Теперь мы можем рассчитать частоту обратных документов по следующей формуле:
![]()
Где N — общее количество документов, а n t — количество терминов в документе. Нам не нужно уменьшать функцию на этом последнем этапе, так как вычисление TF-IDF выполняется для каждой части URL в данной коллекции.
Реализация должна выглядеть примерно так:
Карта :
- Ввод — (urlPart; urlCollectionId, n; N; m)
- Функция — вычисляет TF-IDF на основе n; N; m и D. Где D — общее количество коллекций URL.
![]()
- Вывод — (urlPart; urlCollectionId, оценка)
Полученные результаты
Чтобы дать вам представление о том, действительно ли выбранный подход действительно работает, давайте рассмотрим два примера с совершенно другим дизайном URL. Аккаунт А использовал «.» в качестве разделителя и счета B — «/». Количество служб, обнаруженных наивным подходом, было плохим в обоих случаях: 105 000 служб на счете A и 275 000 служб на счете B.
Решение смогло успешно определить разделитель для каждой учетной записи и рассчитать оценку TF-IDF для каждой части URL. Идентифицированные динамические части были заменены статическим содержимым, аналогично примеру, показанному ниже:
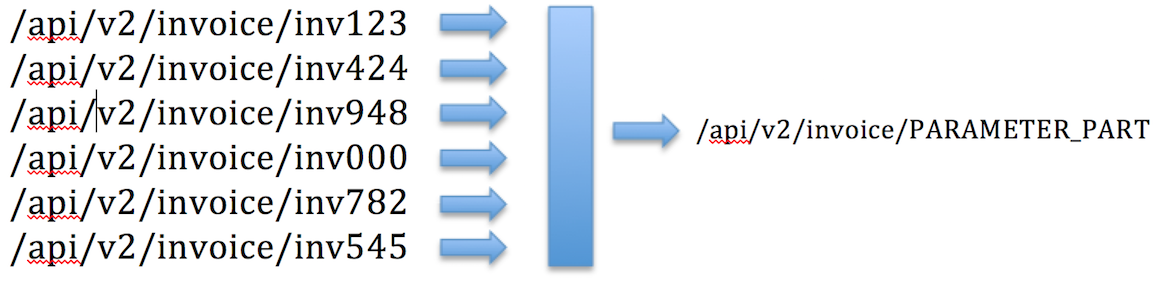
Классификация была улучшена более чем на 99% для обеих учетных записей, в результате чего всего лишь 320 служб для учетной записи A и 195 служб для учетной записи B.
Качество результатов также было подтверждено фактическими владельцами приложений, поэтому в обоих случаях использованный подход был действительно удачным.
Заключительные замечания
Чтобы быть справедливым, текущий Plumbr не основывает свое текущее обнаружение сервиса на сравнении простых строк, как описано во вступительных разделах этого поста. Вместо этого он применяет множество различных методов для смягчения проблемы. Они включают в себя специфичное для фреймворка (Spring MVC, Struts, JSF и т. Д.) Обнаружение и сопоставление с образцом для простых повторяющихся токенов.
Однако результаты, которые я получил с помощью описанного алгоритма, оправдывают фактическое развертывание алгоритма. Уже в июле я начну внедрять подход к нашему фактическому внедрению продукта.
| Ссылка: | Применение алгоритма TF-IDF на практике от нашего партнера JCG Левани Кохреидзе в блоге Plumbr Blog . |