Кажется, что новая парадигма приближается. Facebook и Netflix придумали разные варианты реализации этой идеи. Некоторые называют это архитектурой , управляемой спросом , но прежде чем я покажу вам некоторые решения, давайте разберемся с историей, чтобы понять проблему. Я буду использовать пример, который предоставляет Netflix, но я думаю, что большинство из нас найдет шаблоны знакомыми. 
Просто для ясности, давайте предположим, что у нас есть потоковая служба по требованию, очень похожая на Netflix :), которая имеет три микросервиса. Один содержит жанры, другой — заголовки, а последний — оценки, которые разные пользователи присваивают этим заголовкам. В 2015 году мы откажемся от RPC как от архитектурного стиля и разработаем дизайн RESTful. Давайте кратко перечислим характеристики дизайна RESTful:
- Глаголы HTTP имеют прямое соответствие с глаголами CRUD. Одним из преимуществ является то, что клиенты могут понять, что происходит на сервере, не углубляясь в реализацию. Например, мы знаем, что PUT является идемпотентом, поэтому, поскольку не будет никакого побочного эффекта, клиент может вызывать эту конечную точку несколько раз подряд без каких-либо проблем.
- Мы используем обширное HTTP-кеширование. Благодаря таким заголовкам, как Cache-Control или ETag, мы используем одну из самых сочных функций HTTP: ресурсы кэширования.
- HATEOAS для победы. Каждое отдельное представление должно иметь ссылки на разные представления, чтобы клиенты могли перемещаться по нашему бэкэнду как график. дальнейшее чтение
REST ограничения
Давайте представим, что мы отправляем GET в конечную точку жанров. Ответ будет содержать ссылки на другие запросы GET, такие как названия / 1234 или рейтинги / 6789. Если у нас есть титул «Титаник» в разных жанрах (романс, драма и DiCaprioRules), вы можете увидеть, как клиент собирается выполнить как минимум два избыточных запроса. Кроме того, клиент будет изменять форму данных всякий раз, когда они возвращаются, поскольку вполне вероятно, что клиенту не понадобятся все поля, включенные в эти ответы. Итак, у нас есть две проблемы с этим дизайном:
- Высокая задержка, так как мы не оптимизируем звонки.
- Большие размеры сообщений.
Исправление REST с помощью RPC
Одним из способов преодоления этих проблем является настройка наших запросов с помощью параметров запроса. Вы можете сказать серверу что-то вроде: « дайте мне только пару полей, которые вы выставляете в этом представлении » или любой другой произвольный параметр. Это означает, что вы потеряете кеширование, которое предлагает HTTP, так как теперь у вас будет куча возможных не реально ресурсов для кеширования.
Также вы можете создавать новые абстракции ad-hoc, которые агрегируют это для клиента. Фактически, одним из преимуществ CQRS является возможность создавать различные представления ваших внутренних объектов, поэтому требования клиента не влияют на моделирование вашего домена. Хотя есть проблема: существует большая связь с сервером. Наша система обладает огромным количеством фрагментов, поскольку вы можете передавать по Android, iOS, телевизорам, а также по различным версиям одного и того же клиентского устройства. Поэтому будут разные потребности и ритмы, и координация между бэкендом и клиентами будет очень грязной.
Кроме того, CQRS поражает тем фактом, что вы можете решить смоделировать свою систему в разных ограниченных контекстах, т. Е. В различных развертываемых средах CQRS. Если вашему клиенту требуется представление, которое объединяет данные из двух модулей CQRS, у вас есть та же проблема.
Спешите на помощь архитектуру
Это приводит к созданию архитектуры, управляемой спросом. Концептуально серверная часть — это просто единая сущность, и, поскольку она смоделирована с использованием принципов REST, она определяет форму данных. Тем не менее, у нас будет множество клиентов с разными потребностями, и всем им нужно изгибаться, чтобы получить нужную форму данных. Было бы здорово, если бы клиенты могли просто отправлять запросы в логический блок данных, называемый backend?
Если мы думаем, что в реляционной базе данных концепция похожа. У нас есть разные таблицы (остальные конечные точки, ресурсы, серверные службы), и у нас есть язык запросов, который позволяет нам легко объединять и формировать данные. Некоторые из оптимизаций этого запроса будут выполняться платформой, которая выполняет эти запросы.
Falcor и JSON Graph
Netflix создал инструмент под названием Falcor, который пытается решить эту конкретную проблему. Клиенты больше не будут напрямую взаимодействовать с внутренними службами, вместо этого они будут отправлять запросы в службу Falcor, которая будет выполнять маршрутизацию, агрегацию, прогнозирование и оптимизацию. Это изображение из официальной документации Falcor.
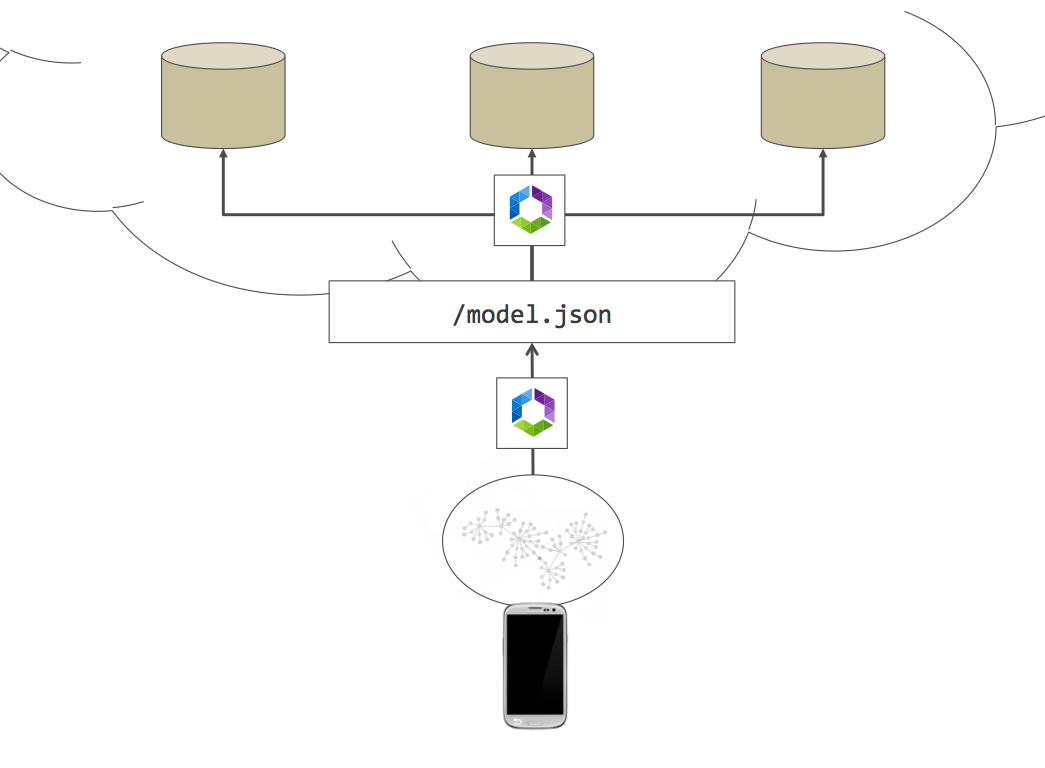
Они основали эту платформу на идее JSON Graph. Позвольте мне объяснить это вкратце. JSON по сути является древовидной структурой. Тем не менее, большинство наших данных имеют отношения, поэтому они должны быть смоделированы как график. Используя дизайн REST, программисты обычно решают эту проблему с помощью идентификаторов, но это делает нашу жизнь действительно сложной (подумайте о таких проблемах, как аннулирование кэша). Так как они сказали:
Граф JSON является допустимым JSON и может быть проанализирован любым анализатором JSON. Однако JSON Graph вводит новые примитивные типы в JSON, что позволяет использовать JSON для представления графической информации простым и согласованным способом.
Они заимствуют идею из файловой системы Unix. Эта файловая система является деревом, но благодаря символическим ссылкам вы можете эмулировать поведение графа. Это имеет огромное значение для способа, которым Falcor оптимизирует вызовы для внутренних служб. Вместо того чтобы хранить некоторые значения в денормализованном виде, Falcor сохраняет ссылки на это нормализованное значение, поэтому, если вы запросите значение, которое уже было получено, Falcor избежит этого вызова. Кроме того, это делает кеширование недействительным намного проще.
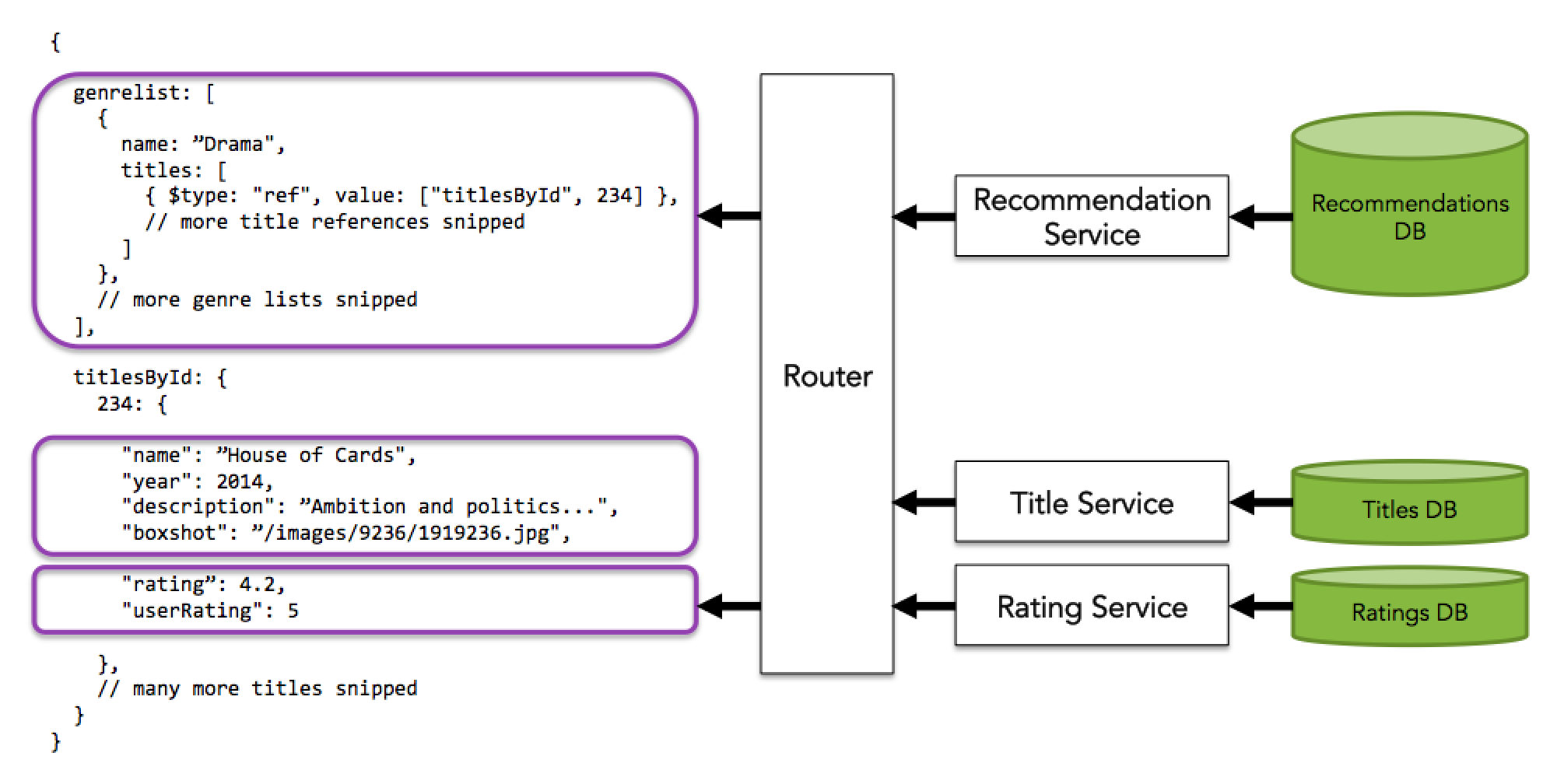
Как вы можете видеть из примера, мы не храним денормализованные документы для названий внутри жанров, но ссылаемся на карту заголовков, проиндексированную по id. Я могу показать вам некоторый код, над которым я работал, для подтверждения концепции. Серверная часть Falcor в настоящее время доступна только на Node.js, но планируется перенести ее на другие платформы .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
router.get('/model.json', falcorKoa.dataSourceRoute(new FalcorRouter([ { route: "teamsById[{integers:teamIds}]['name', 'memberCount']", get : function(pathSet) { const teamIds = pathSet.teamIds; const keys = pathSet[2]; return teamsService.getTeams() .then(function(teams) { var results = []; teamIds.forEach(function(teamId) { keys.forEach(function(key) { var team = teams[teamId]; results.push({ path : ['team', teamId, key], value: team[key] }); }); }); return results; }); } } ]))); |
Клиентская сторона будет выглядеть так:
|
1
2
3
|
const model = new falcor.Model({ source: new falcor.HttpDataSource('/model.json') });model.get('teamsById['1234', '456'].name');model.get('teamsById['789']['name', 'memberCount']'); |
В ЗАКЛЮЧЕНИИ
В программном обеспечении нет серебряных пуль, и никто не утверждает, что Falcor или GraphQL решат все проблемы интеграции клиента и сервера. Однако, если у вас есть приложение с большим количеством клиентов, а ваш бэкэнд имеет сложную модель данных, возможно, стоит попробовать эту новую парадигму.
| Ссылка: | Превосходя REST и RPC от нашего партнера JCG Фелипе Фернандеса в блоге Crafted Software . |