При создании веб-приложений часто происходит большая оптимизация для ускорения потока информации от пользователя и к пользователю. Возможные способы ускорения этого потока информации так же разнообразны, как и сами веб-приложения. В этой статье мы сосредоточимся на том, как можно оптимизировать модель данных в соответствии с конкретными случаями использования, для которых предназначена эта модель данных.
Не секрет, что эти оптимизации всегда специфичны для конкретного случая использования. Они оказывают положительное влияние на вариант использования, для которого они предназначены, но также оказывают отрицательное влияние на другие варианты использования (в случае индекса это увеличенная рабочая нагрузка вставки / обновления). Оценка того, какие варианты использования создают самые большие узкие места, и понимание того, как модель данных используется в производственной среде, имеет решающее значение для правильного компромисса для достижения желаемой производительности.
В этом посте я кратко объясню шаги, которые я обычно предпринимаю для выявления критических узких мест и как их оптимизировать.
Случай использования
Чтобы показать некоторые шаги, которые я прошёл, я буду использовать простое демонстрационное приложение для справки. Я буду использовать простое загрузочное приложение Spring, которое использует JPA / Hibernate для подключения к базе данных MySQL. Для быстрой визуализации HTML я буду использовать шаблоны Thymeleaf. Мы также рассмотрим некоторые аннотации Lombok, чтобы сэкономить время.
Давайте рассмотрим очень простой вариант использования, в котором у нас есть сущность User.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@Getter@Setter@Entity@Builder@NoArgsConstructor@AllArgsConstructor@Table(name = "users")public class User { @Id @GeneratedValue private Long id; @Length(max = 64) @Column(name = "display_name") private String displayName; @Length(max = 16) @Column(name = "first_name") private String firstName; @Length(max = 16) @Column(name = "last_name") private String lastName; @Length(max = 64) @Column(name = "email") private String email;} |
С простым репозиторием JPA с двумя методами постраничного запроса.
|
1
2
3
4
5
6
7
|
public interface UserRepository extends JpaRepository<User, Long> { Page<User> findAllByDisplayName(String displayName, Pageable pageable); Page<User> findAllByFirstNameOrLastName(String firstName, String lastName, Pageable pageable);} |
Мы создаем простой сервис Crud для нашего пользователя.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public interface UserService { Page<User> listAllUsers(Pageable pageable); Page<User> listUsersWithDisplayName(String displayName, Pageable pageable); Page<User> listUsersWithFirstNameOrLastName(String name, Pageable pageable);} @Service@RequiredArgsConstructorpublic class UserServiceImpl implements UserService { private final UserRepository userRepository; @Override public Page<User> listAllUsers(Pageable pageable) { return userRepository.findAll(pageable); } @Override public Page<User> listUsersWithDisplayName(String displayName, Pageable pageable) { return userRepository.findAllByDisplayName(displayName, pageable); } @Override public Page<User> listUsersWithFirstNameOrLastName(String name, Pageable pageable) { return userRepository.findAllByFirstNameOrLastName(name, name, pageable); }} |
Мы также создадим установщик, который запускается после установки приложения. Этот установщик случайным образом сгенерирует 10000 пользователей для нашего примера.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
@Component@RequiredArgsConstructorpublic class DummyUserInstaller { public static final String[] FIRST_NAMES = { "James", "David", "Christopher", "George", "Ronald", "John", "Richard" }; public static final String[] LAST_NAMES = { "Smith", "Johnson", "Williams", "Jones", "Brown", "Davis", "Miller", "Wilson" }; public static final String[] EMAIL_PROVIDERS = { "gmail.com", "hotmail.com", "outlook.com", "yahoo.com" }; public static final int RANDOM_USER_COUNT = 10000; private final UserRepository userRepository; @PostConstruct public void installUsers() { userRepository.deleteAll(); Random random = new Random(); for (int i = 0; i < RANDOM_USER_COUNT; i++) { userRepository.save(createRandomUser(random)); } } private User createRandomUser(Random random) { String randomFirstName = FIRST_NAMES[random.nextInt(FIRST_NAMES.length)]; String randomLastName = LAST_NAMES[random.nextInt(LAST_NAMES.length)]; return User.builder() .displayName(String.format("%s %s", randomFirstName, randomLastName)) .firstName(randomFirstName) .lastName(randomLastName) .email(String.format("%s_%s%d@%s", randomFirstName, randomLastName, random.nextInt(100), EMAIL_PROVIDERS[random.nextInt(EMAIL_PROVIDERS.length)])) .build(); }} |
А в контроллере мы зарегистрируем конечную точку, чтобы получить простую функциональность поиска пользователей. Эта конечная точка имеет три необязательных параметра запроса: страницу и размер для реализации нумерации страниц и один для возможности поиска по отображаемому имени. Если параметр запроса отображаемого имени не указан, будут возвращены все результаты.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@Controller@RequiredArgsConstructorpublic class UserController { public static final int DEFAULT_PAGE = 1; public static final int DEFAULT_PAGE_SIZE = 20; private final UserService userService; @GetMapping("/") public String overview(@RequestParam(name = "displayName", required = false) String displayName, @RequestParam(name = "page", required = false) Integer page, @RequestParam(name = "size", required = false) Integer size, Model model ) { if (displayName == null) { model.addAttribute("users", userService.listAllUsers(toPageRequest(page, size))); } else { model.addAttribute("users", userService.listUsersWithDisplayName(displayName, toPageRequest(page, size))); } return "user-overview"; } private PageRequest toPageRequest(Integer page, Integer size) { if (page == null) { page = DEFAULT_PAGE; } if (size == null) { size = DEFAULT_PAGE_SIZE; } return PageRequest.of(page, size); }} |
Мы также создаем простой шаблон Thymeleaf для отображения наших пользователей.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
<!DOCTYPE html><head> <meta charset="UTF-8"> <title>Use case</title></head><body><form action="/" method="GET"> <label for="displayName">Display name : </label> <input type="text" id="displayName" name="displayName"> <button type="submit">Search</button></form><table> <thead> <tr> <th>Display name</th> <th>First name</th> <th>Last name</th> <th>Email</th> </tr> </thead> <tbody> <tr th:each="user : ${users}"> <td th:text="${user.displayName}"></td> <td th:text="${user.firstName}"></td> <td th:text="${user.lastName}"></td> <td th:text="${user.email}"></td> </tr> </tbody></table></body></html> |
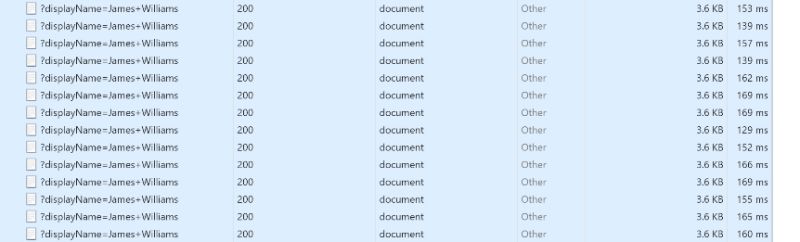
Если мы запустим это простое приложение и откроем http://localhost:8080 в веб-браузере и запросим одного из случайных пользователей, например. «Джеймс Уильямс», мы можем видеть, что время загрузки страницы лежит между 100 и 200 миллисекундами. Мы сравним время загрузки этой страницы с временем загрузки после добавления наших улучшений производительности, чтобы увидеть фактический результат улучшения пользовательского опыта.
Как их идентифицировать
Хорошим индикатором узких мест в модели данных являются запросы, которые выполняются очень часто и выглядят медленнее, чем необходимо. Существует ряд инструментов и методов, которые можно использовать для определения «медленных запросов». Я кратко опишу два способа выявления медленных запросов: использование JetProfiler и использование плана объяснения.

Такие инструменты, как JetProfiler, дают представление о том, какие запросы выполняются плохо, измеряя нагрузку на базу данных в режиме реального времени. Как видно на скриншоте ниже, образец взят из выполненных запросов к базе данных, а извлеченным запросам присваивается оценка в зависимости от их влияния на базу данных.
JetProfiler также предоставляет объяснение того, почему запрос влияет на базу данных. Пример этого показан на скриншоте ниже.
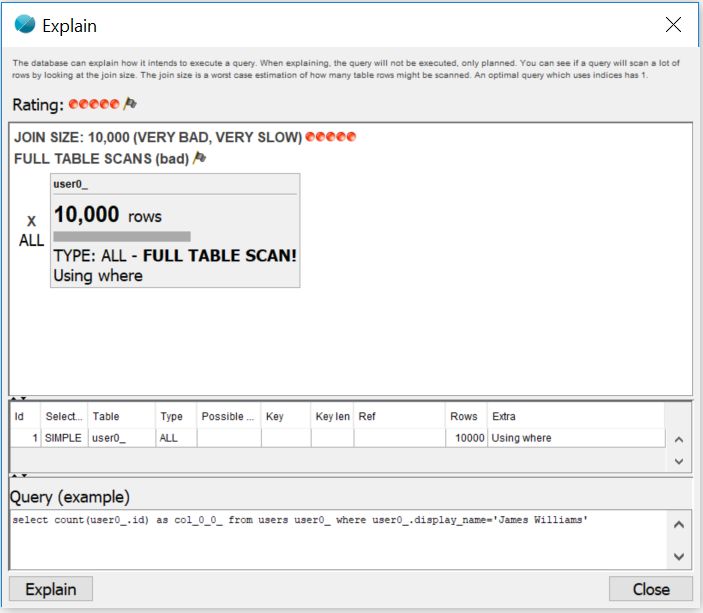
Другой способ получить представление о том, насколько эффективным может быть запрос в базе данных, — это получить план объяснения для данного запроса. Это даст вам некоторую информацию о том, какую операцию поиска должна выполнить база данных, чтобы получить правильный результат данного запроса. План объяснения получается так:
|
1
|
explain select * from users where display_name = 'James Wilson' |

Возвращенный результат содержит следующие атрибуты:
- Тип выбора : тип выбора, который использовался для выполнения этого запроса
- Таблица : таблица, использованная для получения информации
- Тип : тип соединения, который был использован
- Возможные ключи : все индексы, которые были доступны для выбора при выполнении этого запроса
- Ключ : индекс, который был выбран для использования при выполнении этого запроса
- Длина ключа : длина выбранного ключа
- Ссылка : какие столбцы или константы использовались для сравнения с выбранным индексом, данным в возвращаемом значении ключа
- Rows : количество строк, которые считались просмотренными, чтобы вернуть результат при выполнении запроса (чем ниже, тем лучше)
- Дополнительно : дополнительная информация о том, как был выполнен данный запрос.
И результат объяснения JetProfiler, и оператор объяснения приходят к одному и тому же выводу: выборка пользователей с определенным отображаемым именем требует, чтобы база данных просмотрела все вставленные записи, чтобы определить, какие записи соответствуют требованиям запроса. Это не очень эффективный способ выполнения запроса, и проверка всех пользователей на предмет соответствия одного из них заданной строке станет проблемой, если в нашей системе будут миллионы пользователей, особенно если этот запрос выполняется многими пользователями в в то же время.
Как их добавить
Теперь, когда мы определили медленный запрос в нашем приложении, мы можем попытаться оптимизировать этот запрос для вариантов использования, для которых он предназначен. Чтобы оптимизировать этот запрос, мы добавим простой индекс в пользовательскую таблицу для поля display_name. Мы можем добавить индекс несколькими разными способами:
— С помощью оператора создания индекса, подобного показанному ниже:
|
1
|
Create index ix_display_name on users(display_name) |
— Или используя JPA / Hibernate с некоторыми аннотациями Java-постоянства. Заполнив атрибут indexes в аннотации таблицы, мы можем создать индекс по его имени и список столбцов, которые необходимо проиндексировать.
|
1
|
@Table(name = "users", indexes = @Index(name = "ix_display_name", columnList = "display_name")) |
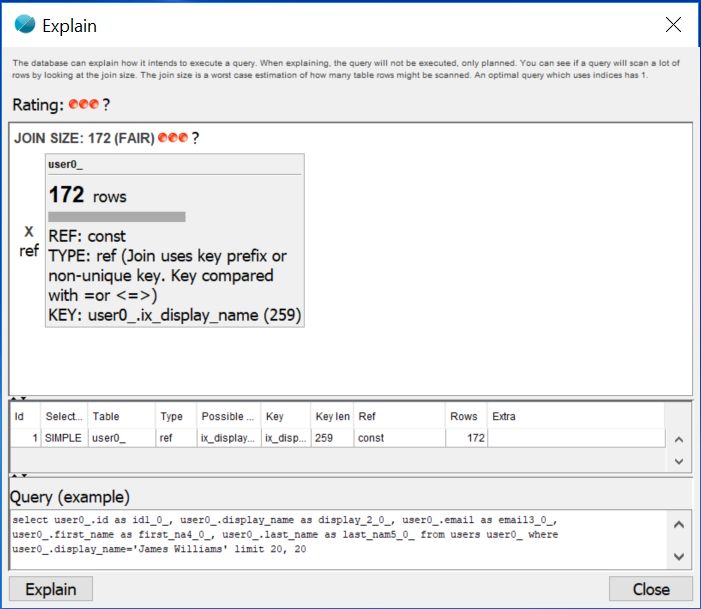
Когда мы добавляем индекс в таблицу пользователей для столбца отображаемого имени, мы видим, что наш индекс сейчас используется. Мы видим, что количество строк, проверяемых одним и тем же запросом, резко уменьшается.

Аналогичный результат показан в JetProfiler, когда мы снова записываем данные запросы:
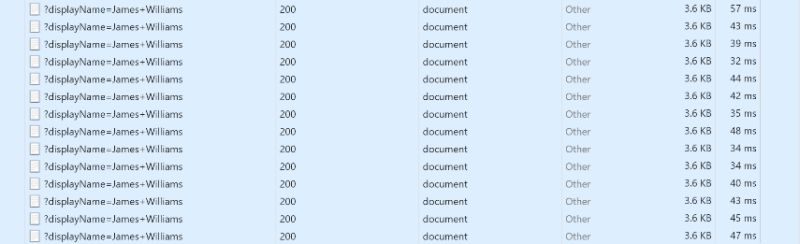
Если мы теперь снова загрузим страницу в нашем браузере и начнем поиск того же случайного пользователя, мы увидим, что скорость загрузки страницы теперь составляет от 30 до 50 миллисекунд, что является значительным улучшением.
Вывод
Так что это два разных способа определения медленных запросов в приложении: быстро найти самые медленные запросы в вашем приложении с помощью такого инструмента, как JetProfiler, или выяснить, какое влияние конкретный запрос оказывает на базу данных, используя план объяснения. Я также показал и протестировал довольно простое решение для повышения производительности этого конкретного запроса, добавив индекс для конкретного случая использования, но это, очевидно, очень зависит от случая.
|
Опубликовано на Java Code Geeks с разрешения Jesse Van Rooy, партнера по нашей программе JCG . Смотрите оригинальную статью здесь: Повышение скорости работы базы данных путем исправления медленных запросов Мнения, высказанные участниками Java Code Geeks, являются их собственными. |