Сегодня я собираюсь поделиться некоторыми ценными уроками, извлеченными из разработки высококонкурентного программного обеспечения. Это уроки из реальной жизни, полученные непосредственно из разработки Mule ESB . Это история о взаимоблокировках, переключениях контекста, использовании процессора и профилировании , посвященная тому, как диагностировать эти проблемы, которые часто являются самой сложной частью решения.
Итак, история начинается пару недель назад, когда я начал работать над новой функцией для Mule 3.5.0. Скоро вы услышите подробности об этом, но в основном это новая функция, которая нацелена на интеграционные сценарии использования, которые требуют обработки огромных объемов данных. Как вы можете себе представить, эта функция имеет дело с распараллеливанием, управлением процессами, атомарностью, согласованностью, распределенными блокировками и т. Д. … Все самое интересное!
Начальные симптомы
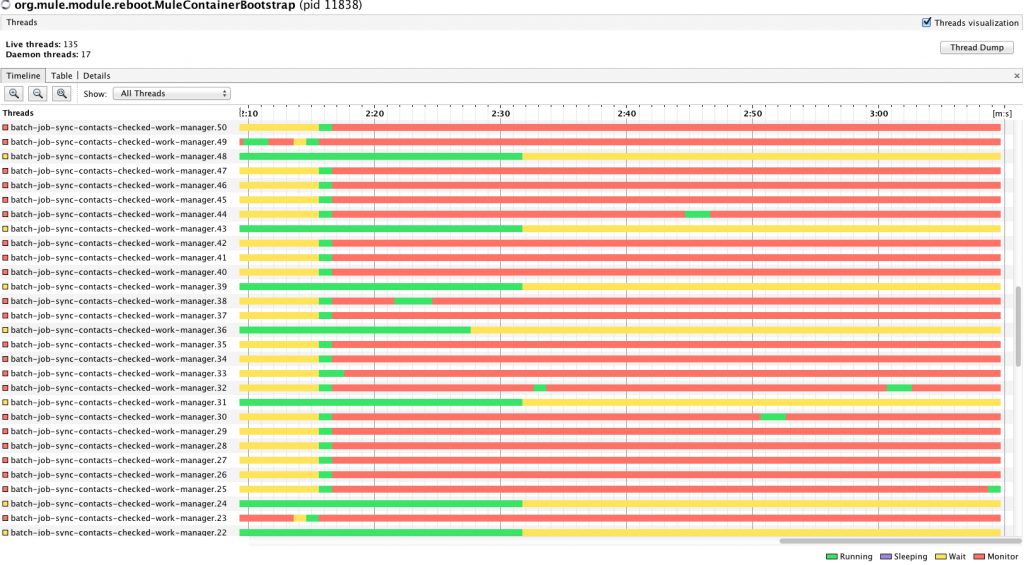
Итак, после двух итераций разработки у меня была первая альфа-версия, которую я с гордостью передал своему дружному сотруднику по контролю качества ( Лучано Гандини , ты мужчина!). Он написал несколько примеров приложений и начал тестирование. Конечно, он вернулся с полным списком ошибок, но один из них был о узком месте производительности, которое в некоторых случаях превращалось в тупик . К проблеме также было приложено это изображение:
{kind=link}
диагностики
 Решение такого рода проблем во многом похоже на то, чтобы быть ветеринаром. Ваш пациент не может сказать вам, где болит или как он себя чувствует. Все, что у меня было в данный момент, это обеспокоенный фермер, который говорил: «Мой Мул идет медленно и у него нет аппетита», что делает изображения, подобные приведенному выше, чрезвычайно ценными… Это, конечно, до тех пор, пока мы можем интерпретировать Это. Это сложная часть!
Решение такого рода проблем во многом похоже на то, чтобы быть ветеринаром. Ваш пациент не может сказать вам, где болит или как он себя чувствует. Все, что у меня было в данный момент, это обеспокоенный фермер, который говорил: «Мой Мул идет медленно и у него нет аппетита», что делает изображения, подобные приведенному выше, чрезвычайно ценными… Это, конечно, до тех пор, пока мы можем интерпретировать Это. Это сложная часть!
Итак, что говорит нам изображение выше? Изображение представляет собой снимок экрана с VisualVM , который представляет собой приложение для профилирования, которое отслеживает экземпляр JVM и дает вам полезную информацию о памяти, использовании процессора, а также активных потоках и их состояниях. Здесь мы можем видеть:
- Показываемые потоки принадлежат опросу потоков, который создает моя новая функция. Инструмент показал множество других тем, но в качестве иллюстрации я просто показываю эти.
- Рядом с именем каждого потока есть временная шкала, которая показывает состояние каждого потока в течение определенного периода времени.
- Когда нить зеленая , это означает, что она обрабатывается.
- Когда он желтый , это означает, что к нему был вызван метод wait (), и он ожидает вызова notify () или notifyAll (), чтобы разбудить его
- Наконец, красный цвет означает, что поток ожидает получения доступа через монитор (что, проще говоря, означает, что он достиг синхронизированного блока или ожидает какой-то блокировки )
Таким образом, на данный момент мы уже можем сделать наши первые выводы:
- Кажется, что все потоки становятся красными одновременно, что, скорее всего, означает, что они все пытаются получить доступ к одному и тому же синхронизированному блоку в одно и то же время. Кроме того, они по большей части красные, что объясняет, почему работа выполняется медленно.
- Кроме того, есть некоторые потоки, которые проводят довольно много времени в желтом цвете, то есть в ожидании чего-то еще. Поскольку заблокировано очень много потоков, трудно понять, почему это происходит в данный момент, поэтому сейчас мы сосредоточимся только на красных потоках.
Хорошо! Итак, теперь мы знаем, что происходит, что очень много! Тем не менее, мы до сих пор не знаем, почему это происходит … То есть, мы не знаем, какие части кода вызывают это. Вот для чего нужен дамп потока. По сути, дамп потока дает вам текущую трассировку стека для каждого из этих потоков в данный момент времени, чтобы вы могли видеть, что они на самом деле делали. Свалка показала это:
-
waiting to lock <7e69a3f18> (a org.mule.module.batch.engine.RecordBuffer$BufferHolder) at org.mule.module.batch.engine.RecordBuffer$BufferHolder.access$3(RecordBuffer.java:128) at org.mule.module.batch.engine.RecordBuffer.add(RecordBuffer.java:88) at org.mule.module.batch.BatchStepAggregate.add(BatchStepAggregate.java:101) at org.mule.module.batch.DefaultBatchStep.onRecord(DefaultBatchStep.java:144) at org.mule.module.batch.BatchRecordWork.run(BatchRecordWork.java:62) at org.mule.work.WorkerContext.run(WorkerContext.java:294) at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:921) at java.lang.Thread.run(Thread.java:680) - See more at: http://blogs.mulesoft.org/chasing-the-bottleneck-true-story-about-fighting-thread-contention-in-your-code/#sthash.jHeBiCBD.dpuf
Итак, это все! Потоки блокируются в строке 88 класса RecordBuffer. Поздравляем: Вы только что нашли свою опухоль!
лечение
К счастью, эта опухоль была работоспособна, поэтому с небольшим рефакторингом я смог избежать разногласий и устранить тупик. Но, как вы знаете, ни одна хирургическая процедура не обходится без последующего матча, поэтому, прежде чем объявить ошибку как исправленную, я снова провел тест и запустил свой собственный профиль. На этот раз я использовал другой профилировщик под названием Yourkit вместо VisualVM, главным образом, чтобы воспользоваться его функциональными возможностями.
ПРИМЕЧАНИЕ . Я выбрал YourKit, потому что мне нравятся его функциональные возможности, а также потому, что Mulesoft приобрел лицензии на него, поэтому он пригодился для этого. Тем не менее, я хочу подчеркнуть, что другие продукты, такие как JProfiler или Mission Control, могли бы выполнять свою работу так же хорошо. Просто выберите тот, который вам нравится больше всего!
После повторения теста я получил это второе изображение:
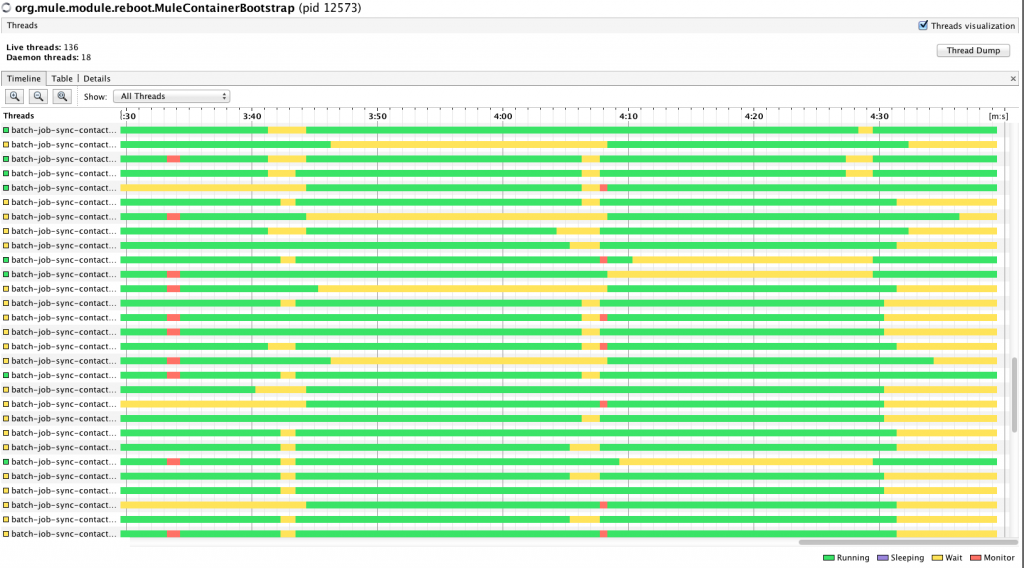
So red is mostly gone…. The ones you still see are because of network I/O and have reasonable length. However, what’s all the deal with all the yellow? Now most of my threads went from being blocked to being waiting. That’s not cool either! Deadlock are gone so the app would not hang anymore but performance hasn’t gone up, it’s just as slow as it was before. Additionally at this point I noticed a new symptom I hadn’t seen before: CPU usage was really low. Like under 20% percent.
{kind=link}
Что же нам теперь делать? Так же, как и раньше, получение дампа потока в ожидающих потоках. Результаты были более удивительными! Помните, я говорил вам, что эти потоки являются частью пула потоков, который создает моя новая функция? Что ж, получается, что потоки на самом деле простаивают, просто сидят и ждут, когда придет больше работы. Я много раз просматривал код, спрашивая себя: «Как, черт возьми, это возможно?»… Ответ был довольно прост: во время борьбы с высокой сложностью кода я упустил из виду простоту конфигурации …
Короче говоря, у меня есть пул потоков для обработки. Мы будем называть потоки в этом пуле «рабочими потоками». Кроме того, есть еще один поток, который отвечает за распределение работы в этот пул (назовем его потоком диспетчера). Поток диспетчера смог сгенерировать работу быстрее, чем рабочие потоки смогли ее завершить. В результате бассейн довольно быстро истощается. Пулы потоков часто имеют настраиваемые стратегии для борьбы с исчерпанием ресурсов. Некоторые стратегии отвергают излишнюю работу, некоторые ждут … Оказывается, что используемая по умолчанию конфигурация пула потоков, которую я использовал, заключалась в выполнении задания в вызывающем потоке. Это означает, что поток диспетчера не может продолжать диспетчеризацию работы, потому что он был занят обработкой работы, которую он должен был дать другим. Итак, к тому времени, когда рабочие потоки были готовы принять больше работы,им пришлось ждать, пока поток диспетчера снова не станет доступен.
Как бы ни была проста эта ошибка, на самом деле увидеть ее может быть довольно сложно. Как я это узнал? Смотря на дамп потока для потока диспетчера. Еще раз, профилировщики ваш друг .
Решение было простым: я просто настроил пул потоков для ожидания в случае исчерпания ресурсов. Таким образом, как только рабочий поток становится доступным, поток диспетчера просыпается и дает ему работу. Профилировщик теперь выглядел так:

{kind=link}
Теперь мы видим, что рабочие потоки эффективно используют процессор, и нет никаких красных точек, кроме неизбежного ввода-вывода. Загрузка ЦП теперь составляла около 100%, а приложение было на 58% быстрее.
Меньше параллелизма — больше
И последнее: когда я проверял загрузку ЦП, я заметил, что хотя загрузка составляла около 100%, более половины использовалось в «системных операциях» и только около 45% фактически использовалось мулом. Это произошло потому, что пул потоков был намного больше, чем необходимо. Параллелизм хорош, но вы никогда не можете упускать из виду тот факт, что чем больше у вас потоков, тем больше накладных расходов при переключении контекста вы будете страдать. Итак, я сократил пул потоков со 100 до 16. Результат? Мой тест был теперь на одну минуту быстрее. Так что помните: когда вы настраиваете максимальную загрузку процессора, не используйте столько потоков, сколько сможете выделить. Вместо этого ищите номер, который даст вам максимальную загрузку ЦП с меньшими издержками переключения контекста.
Сводные вынос
Я надеюсь, что вы найдете это полезным. Вот как мы делаем наш Мул галоп!
 Ключевые вещи, которые вы должны помнить из этого поста:
Ключевые вещи, которые вы должны помнить из этого поста:
- При тестировании производительности используйте профилировщик, чтобы убедиться, что вы эффективно используете свои ресурсы
- Старайтесь сводить синхронизированные блоки к минимуму.
- Попробуйте сократить время ожидания
- Не злоупотребляйте своей способностью создавать темы. Сократить издержки переключения контекста
- Но самое главное: не важно, сколько у вас данных, если вы не можете их интерпретировать и превратить в информацию
Спасибо за чтение. Увидимся в следующем посте!