Часть 2. Понимание
В предыдущем посте этой серии мы рассмотрели доступные инструменты для захвата дрожания осциллографа и предложили новую альтернативу с более высоким разрешением, которая может быть особенно полезна, когда нам нужно перейти к масштабам менее миллисекунды.
Итак, давайте воспользуемся этим инструментом и еще раз поймем немного дрожания. На этот раз мы работаем над установкой, которая должна предлагать более настроенную среду выполнения, применяя несколько основных приемов, чтобы сделать вычислительные ресурсы более доступными для пользовательских процессов и менее склонными к тому, чтобы ОС была захвачена, чтобы делать то, что делают эти операционные системы. дней.
Мы передаем ядру несколько дополнительных параметров загрузки:
isolcpus = 6,7 nohz_full = 6,7 rcu_nocbs = 6,7 processor.max_cstate = 0 intel_idle.max_cstate = 0 transparent_hugepage = никогда не занят
Если вы заинтересованы в том, что они делают, посмотрите на отличный пост от Джереми Эдера или просто прочитайте пункты в ядре os jitter README .
Эти параметры загрузки ядра должны дать нам хороший непрерывный поток циклов процессора, чтобы наша программа могла работать без сбоев. Правильно?
На этот раз мы не только попытаемся захватить профиль дрожания, но и запишем основную деятельность, пытаясь ее понять.
Чтобы проанализировать активность ядра, нам нужно профилировать его, чтобы определить любые источники дрожания.
Чаще всего люди используют ftrace (с trace-cmd, kernel shark) и плагином function_graph. Это отличный инструмент, используемый многими профессионалами, которым необходимо погрузиться в интуицию системы. Вы также можете использовать perf запись, а затем просмотреть захваченный профиль с помощью скриптов отчета perf, которые также предлагают увеличенное представление о том, сколько циклов потребовалось отдельным функциям ядра (или подпрограммам пользовательского пространства).
Если вы ищете инструменты для профилирования ядра, вы также наткнетесь на sysdig, systemtap или dtrace — если вы используете Solaris или используете экспериментальную поддержку Linux.
Представляем LTTng
Мне лично нравится работать с LTTng — довольно недооцененным и относительно мало известным стеком профилирования для Linux. Он существует уже довольно давно, и я думаю, что он заслуживает большего признания, чем сейчас.
Вы можете прочитать о его богатом наборе функций и о том, как эффективно использовать его в руководстве пользователя .
Сделав это базовое введение, давайте запустим сэмплер jitter и профилирование lttng параллельно:
|
1
|
$ nohup jitter -c 6 -d 300 -r 10 -o influx://localhost:5581 &; lttng create jitter-sampling && lttng enable-events -k -a && lttng start && sleep 300 && lttng stop |
Теперь давайте посмотрим, на каком уровне прерывания поток пользовательского пространства должен испытывать при работе на одном из наших изолированных ядер:
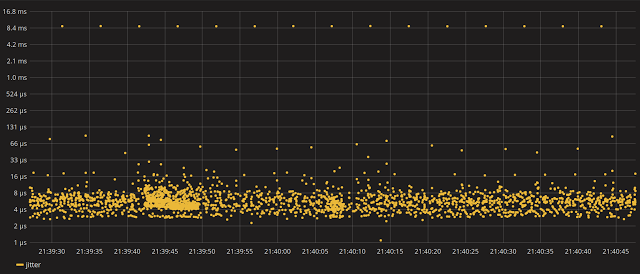
Вау, это не совсем то, что мы ожидали, не так ли? То, на что мы надеялись, это иметь одно полное ядро изолированным (cpu6, cpu7 для настройки HT), помогая нам достичь относительно низкого уровня джиттера.
Пики в несколько миллисекунд не соответствуют ожиданиям. Так почему бы не увеличить один из этих пиков и не попытаться сопоставить его с записью LTTng.
На мой взгляд, одна из лучших сторон этого инструмента — тот факт, что он сохраняет записанные события в CTF (общий формат трассировки), который можно загрузить в другой аккуратный программный продукт:
Трасса Компас .
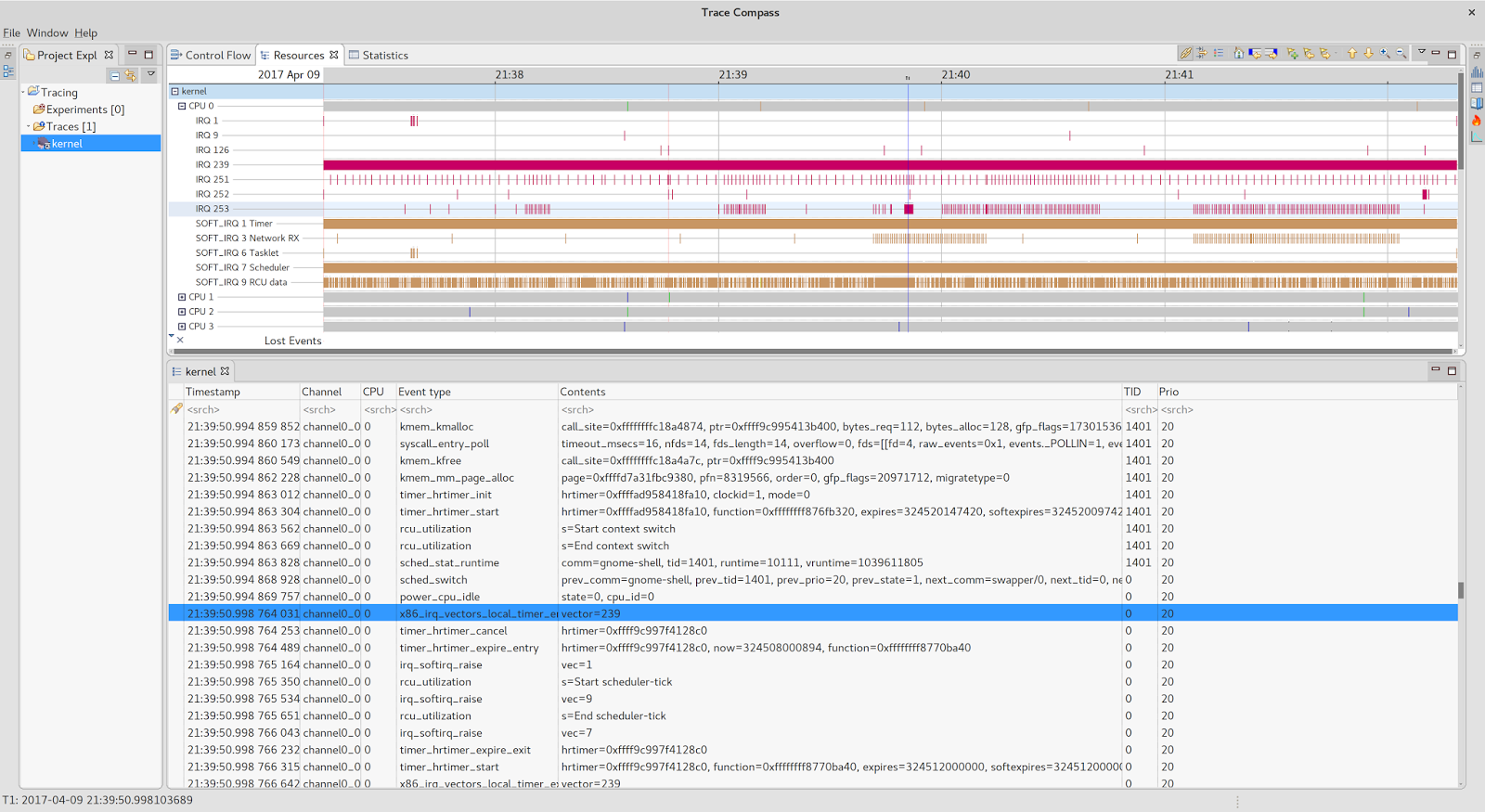
Круто, не правда ли? Я оставлю открытие его чудес вашему усердному уму. А пока давайте придерживаться соответствующего ядра и работы, которую он выполнял во время киоска (21: 40: 07.200):
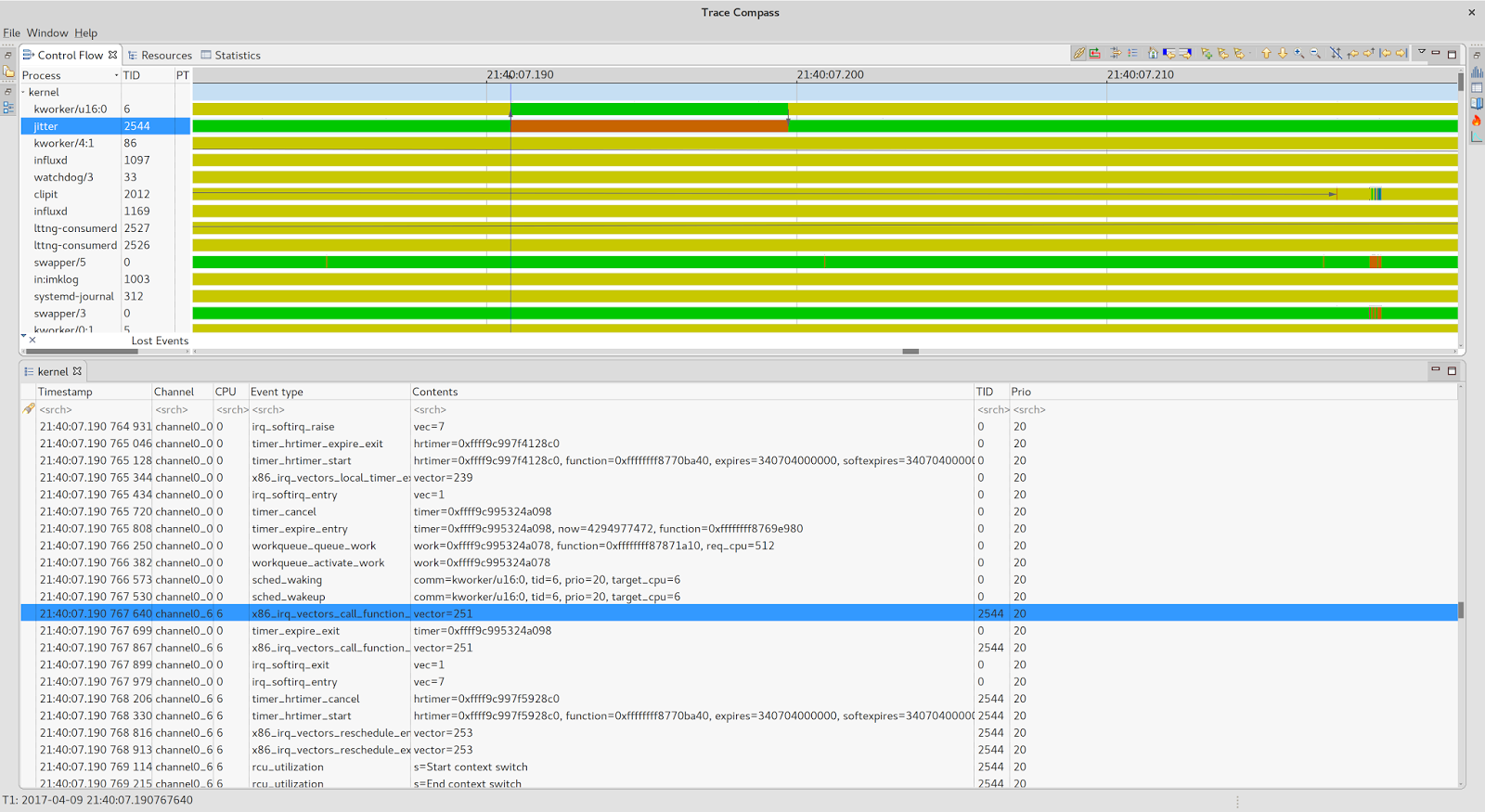
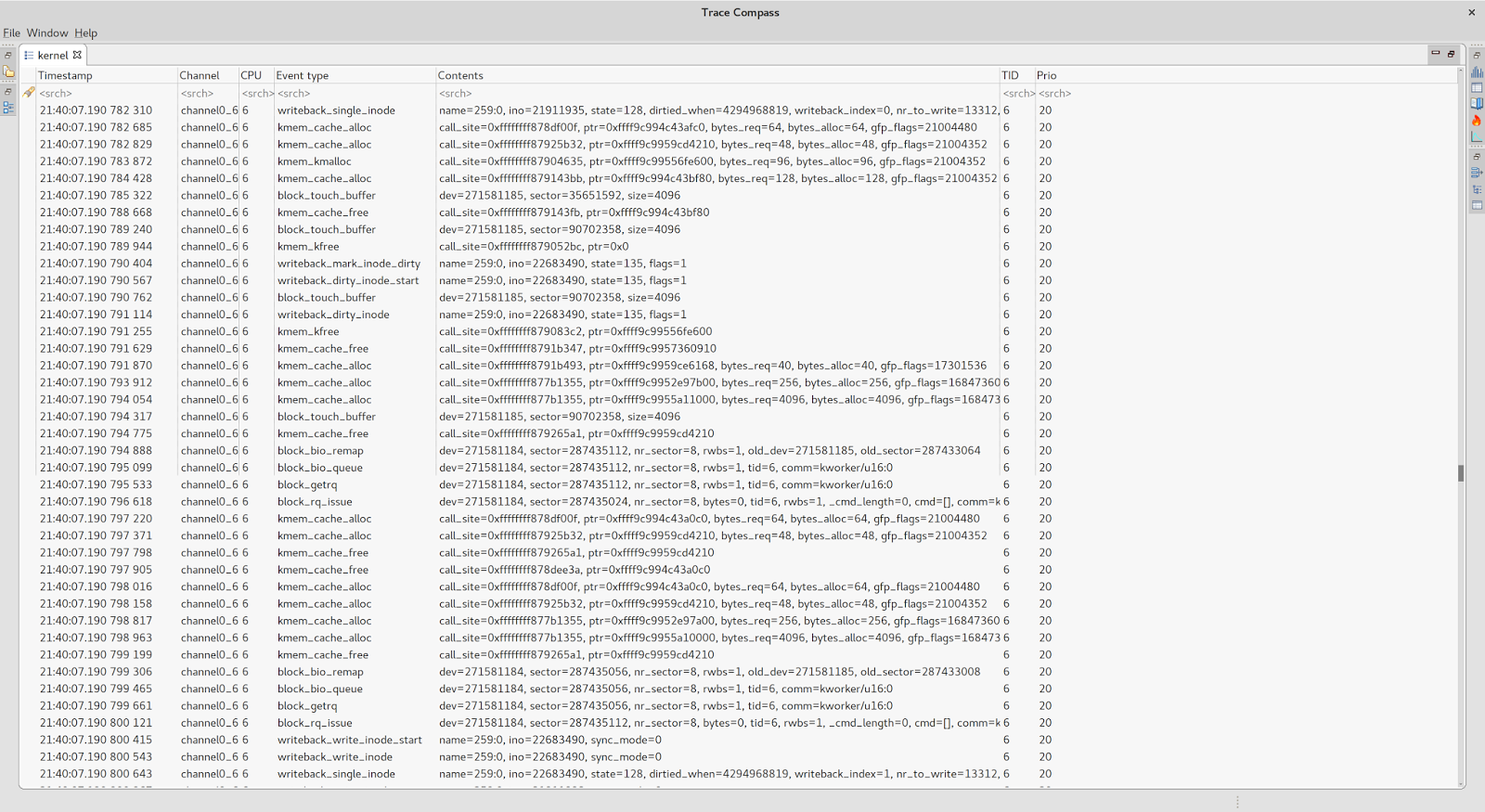
Так что теперь все становится ясно. Наш поток дискретизации джиттера был отключен kthread, выполняющим операцию обратной записи как часть обработки связанной рабочей очереди.
Рабочие очереди являются одним из механизмов ядра Linux для управления фрагментами отложенной работы, обычно связанными с файловой системой io, блочными устройствами или другими системными подпрограммами.
Давайте исправим это, связав рабочую очередь обратной записи с процессором 0-5 на данный момент. Это исключит наш критический набор задержки (процесс 6,7).
|
1
|
echo 3f > /sys/bus/workqueue/devices/writeback/cpumask |
Пришло время перезапустить сэмплер джиттера и посмотреть, есть ли улучшения.
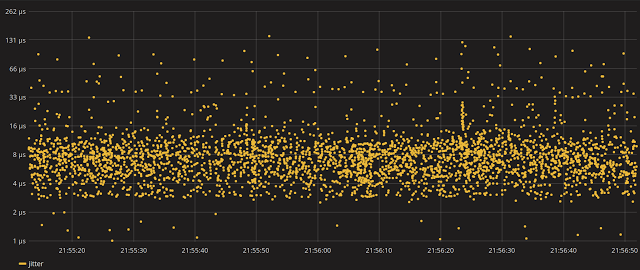
Намного лучше…
Хотя афинитизация рабочих очередей, обратных вызовов irqs или rcu является довольно фундаментальной техникой, большинство разработчиков, ориентированных на производительность, знакомы с тем, что этот пост посвящен чему-то совершенно другому.
Я надеюсь, что этот короткий материал демонстрирует, что охота на пики латентности не всегда должна быть пугающим опытом или подвигом какого-то темного системотехнического искусства. Используя и комбинируя правильные инструменты, это может стать плодотворным упражнением даже для тех из нас, кто не чувствует себя очень комфортно вникать во внутренности ОС.
Следите за следующей статьей из серии, в которой мы более подробно рассмотрим HW-управляемый источник киосков исполнения и другие менее известные классы событий, которые привели к так называемому шуму платформы.
| Ссылка: | Почему мой код иногда тормозит (и как узнать, кто стоит за всем этим)? от нашего партнера JCG Войцеха Кудлы в Fast. Быстрее. Фрик блог. |