Erlang существует уже более 30 лет и был построен задолго до появления многоядерных процессоров. Тем не менее, этот язык не может быть более актуальным сегодня! Базовая архитектура языка идеально подходит для современных процессоров, которые установлены на каждом компьютере и мобильном устройстве.
Компьютер, на котором я пишу эту статью, имеет процессор Intel Core i7 с тактовой частотой 2,2 ГГц, но, что более важно, он оснащен восемью ядрами. Проще говоря, он может выполнять восемь задач одновременно.
Возможность воспользоваться этими ядрами существует во многих языках, но часто кажется неуместной или чреватой ловушками и проблемами. Если вам когда-либо приходилось беспокоиться о мьютексе , общем изменяемом состоянии и о том, что код безопасен для потоков , вы знаете, что есть как минимум несколько ловушек, которые следует опасаться.
В Erlang и, следовательно, в Elixir, использующем Erlang VM (BEAM), он позволяет без труда писать и рассуждать о параллельном коде. В то время как у Ruby есть несколько отличных библиотек для помощи в написании параллельного кода, с Elixir он встроен и является первоклассным гражданином.
Нельзя сказать, что написание сильно параллельных или распределенных систем легко. Отнюдь не! Но с Elixir язык на вашей стороне.
Процессы, PID и почтовые ящики
Прежде чем мы рассмотрим, как писать параллельный код в Elixir, полезно понять термины, которые мы будем использовать, и модель параллелизма, которую использует Elixir.
Актер модель
Параллелизм в эликсире (и эрланге) основан на модели актера . Актеры — это однопоточные процессы, которые могут отправлять и получать сообщения между собой. Erlang VM управляет их созданием, выполнением и связью. Их память полностью изолирована, что позволяет не беспокоиться о «общем состоянии».
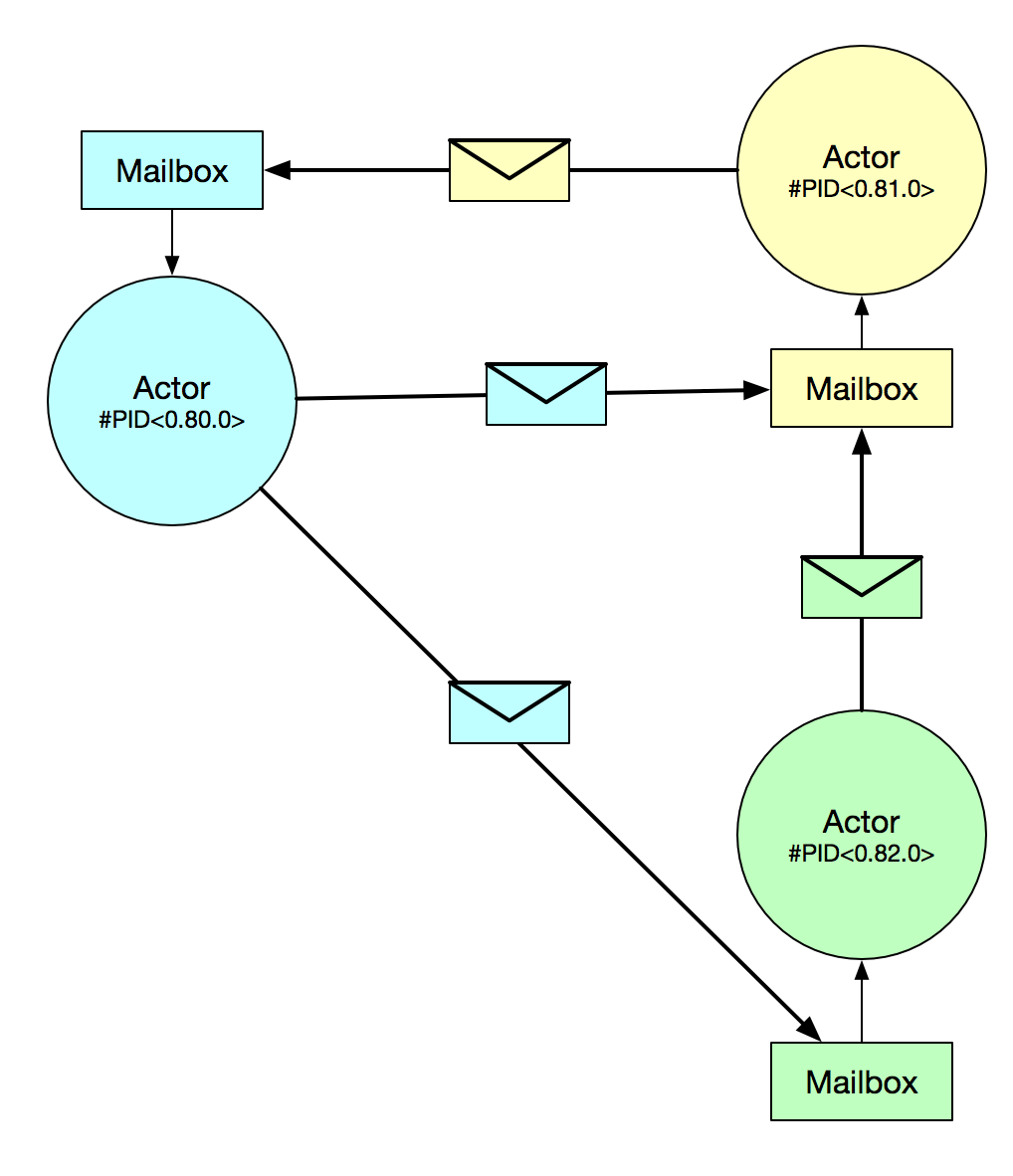
- Процесс : похож на поток уровня ОС, но гораздо более легкий. Это, по сути, единица параллелизма в эликсире. Процессы управляются BEAM (среда выполнения Erlang), которая обрабатывает распределение работы по всем ядрам ЦП или даже по другим узлам BEAM в сети. Система может иметь миллионы таких процессов одновременно, и вы не должны бояться использовать их в своих интересах.
- Идентификатор процесса (PID) : это ссылка на конкретный процесс. Как и IP-адрес в Интернете, PID — это способ указать Elixir, на какой процесс вы хотите отправить сообщение.
- Почтовый ящик : чтобы процессы могли взаимодействовать друг с другом, сообщения отправляются туда и обратно. Когда сообщение отправляется процессу, оно поступает в почтовый ящик этого процесса. Именно этот процесс принимает сообщения, сидящие в его почтовом ящике.
Итак, чтобы свести все воедино, процесс в Elixir — это актер. Он может общаться с другим субъектом, отправляя сообщение на определенный PID. Получатель может получить сообщение, проверив его почтовый ящик на наличие новых сообщений.
Написание параллельного кода
В этом разделе мы рассмотрим, как на самом деле модель акторов для параллелизма используется в Elixir.
Создание процессов
Создание нового процесса выполняется с spawn_link функций spawn или spawn_link . Эта функция принимает анонимную функцию, которая будет вызываться в отдельном процессе. В ответ нам дают идентификатор процесса, часто называемый PID. Это важно, если мы хотим связаться с этим процессом в будущем или попросить ядро предоставить информацию о процессе.
|
1
2
|
pid = spawn(fn -> :timer.sleep 15000 end)#PID<0.89.0> |
Все в Эликсире работает внутри процесса. Вы можете узнать PID вашего текущего процесса, вызвав функцию self() . Таким образом, даже когда вы находитесь в оболочке iex , при вызове self() вы можете увидеть PID для этого сеанса iex, что-то вроде #PID<0.80.0> .
Мы можем использовать этот PID, чтобы запросить у Elixir информацию о процессе. Это делается с помощью функции Process.info(pid) .
|
01
02
03
04
05
06
07
08
09
10
|
Process.info(pid)[current_function: {:timer, :sleep, 1}, initial_call: {:erlang, :apply, 2}, status: :waiting, message_queue_len: 0, messages: [], links: [], dictionary: [], trap_exit: false, error_handler: :error_handler, priority: :normal, group_leader: #PID<0.50.0>, total_heap_size: 233, heap_size: 233, stack_size: 2, reductions: 43, garbage_collection: [max_heap_size: %{error_logger: true, kill: true, size: 0}, min_bin_vheap_size: 46422, min_heap_size: 233, fullsweep_after: 65535, minor_gcs: 0], suspending: []] |
Интересно, что вы можете найти здесь! Например, в iex если вы запросите информацию о себе Process.info(self()) , вы увидите историю введенных вами команд:
|
01
02
03
04
05
06
07
08
09
10
|
iex(1)> 5 + 5iex(2)> IO.puts "Hello!"iex(3)> pid = spawn(fn -> :timer.sleep 15000 end)iex(4)> Process.info(self())[:dictionary][:iex_history]%IEx.History.State{queue: {[ {3, 'pid = spawn(fn -> :timer.sleep 15000 end)\n', #PID<0.84.0>}, {2, 'IO.puts "Hello!"\n', :ok}], [{1, '5 + 5\n', 10}]}, size: 3, start: 1} |
Отправка сообщений
Сообщения могут быть отправлены процессу с помощью функции send . Вы предоставляете ему PID процесса, в который вы хотите отправить сообщение вместе с отправляемыми данными. Сообщение отправляется в почтовый ящик принимающих процессов.
Отправка это только полдела. Если получатель не готов принять сообщение, оно не услышит. Процесс может получать сообщения, используя конструкцию receive , образец которой соответствует полученным сообщениям.
В приведенном ниже примере мы создаем новый процесс, который ожидает получения сообщения. Как только оно получит сообщение в своем почтовом ящике, мы просто выведем его на экран.
|
1
2
3
4
5
6
7
8
|
pid = spawn(fn -> IO.puts "Waiting for messages" receive do msg -> IO.puts "Received #{inspect msg}" endend)send(pid, "Hello Process!") |
Поддерживая наш процесс живым
Процесс завершается, когда у него больше нет кода для выполнения. В приведенном выше примере процесс будет работать до тех пор, пока не получит первое сообщение, а затем завершится. Таким образом, возникает вопрос: как получить длительный процесс?
Мы можем сделать это, используя функцию loop которая вызывает себя рекурсивно. Этот цикл просто получит сообщение, а затем позвонит сам, чтобы дождаться следующего.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
defmodule MyLogger do def start do IO.puts "#{__MODULE__} at your service" loop() end def loop do receive do msg -> IO.puts msg end loop() endend# This time we will spawn a new processes based on the MyLogger module's method `start`.pid = spawn(MyLogger, :start, [])send(pid, "First message")send(pid, "Another message") |
Поддержание состояния
Наш текущий процесс не отслеживает состояние. Он просто выполняет свой код без сохранения какого-либо дополнительного состояния или информации.
Что если бы мы хотели, чтобы наш регистратор отслеживал некоторые статистические данные, например количество зарегистрированных сообщений? Обратите внимание на вызов вызова spawn(MyLogger, :start, []) ; последний параметр, который является пустым списком, фактически является списком аргументов, которые могут быть переданы процессу. Это действует как «начальное состояние» или то, что передается в функцию точки входа. Нашим состоянием будет просто число, которое отслеживает количество сообщений, которые мы зарегистрировали.
Теперь, когда вызывается функция init , ей будет передано число 0 . Мы должны следить за этим числом, пока мы делаем свою работу, всегда передавая обновленное состояние следующему циклу нашего процесса.
Еще одна вещь, которую мы сделали, — добавила дополнительное действие, которое может выполнять наш регистратор. Теперь он может регистрировать сообщения, а также распечатывать статистику. Для этого мы отправим наши сообщения в виде tuple где первое значение — это atom , представляющий команду, которую мы хотим, чтобы наш процесс выполнял. Сопоставление с образцом в конструкции receive позволяет нам отличать намерения одного сообщения от другого.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
defmodule MyLogger do def start_link do # __MODULE__ refers to the current module spawn(__MODULE__, :init, [0]) end def init(count) do # Here we could initialize other values if we wanted to loop(count) end def loop(count) do new_count = receive do {:log, msg} -> IO.puts msg count + 1 {:stats} -> IO.puts "I've logged #{count} messages" count end loop(new_count) endendpid = MyLogger.start_linksend(pid, {:log, "First message"})send(pid, {:log, "Another message"})send(pid, {:stats}) |
Рефакторинг на клиент и сервер
Мы можем немного реорганизовать наш модуль, чтобы сделать его более удобным для пользователя. Вместо непосредственного использования функции send мы можем скрыть детали за клиентским модулем. Его работа будет состоять в том, чтобы отправлять сообщения процессу, выполняющему модуль сервера, и при необходимости ждать ответа на синхронные вызовы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
defmodule MyLogger.Client do def start_link do spawn(MyLogger.Server, :init, [0]) end def log(pid, msg) do send(pid, {:log, msg}) end def print_stats(pid) do send(pid, {:print_stats}) end def return_stats(pid) do send(pid, {:return_stats, self()}) receive do {:stats, count} -> count end endend |
Наш серверный модуль довольно прост. Он состоит из функции init которая в этом случае мало что делает, кроме запуска loop функции цикла. Функция loop отвечает за получение сообщений из почтового ящика, выполнение запрошенной задачи и затем повторение цикла с обновленным состоянием.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
defmodule MyLogger.Server do def init(count \\ 0) do loop(count) end def loop(count) do new_count = receive do {:log, msg} -> IO.puts msg count + 1 {:print_stats} -> IO.puts "I've logged #{count} messages" count {:return_stats, caller} -> send(caller, {:stats, count}) count end loop(new_count) endend |
Если мы хотим использовать приведенный ниже код, нам не нужно знать, как реализован сервер. Мы взаимодействуем напрямую с клиентом, а он в свою очередь отправляет сообщения на сервер. Я использовал псевдоним модуля, чтобы не вводить MyLogger.Client несколько раз.
|
1
2
3
4
5
6
7
|
alias MyLogger.Client, as: Loggerpid = Logger.start_linkLogger.log(pid, "First message")Logger.log(pid, "Another message")Logger.print_stats(pid)stats = Logger.return_stats(pid) |
Рефакторинг сервера
Обратите внимание, что все сообщения, принимаемые сервером, сопоставляются с шаблоном, чтобы определить, как их обрабатывать? Мы можем добиться большего успеха, чем иметь одну большую функцию, создав серию «обработчиков» функций, которые соответствуют шаблону полученных данных.
Это не только очищает наш код, но и облегчает тестирование. Мы можем просто вызвать отдельные функции handle_receive с правильными аргументами, чтобы проверить, что они работают правильно.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
defmodule MyLogger.Server do def init(count \\ 0) do loop(count) end def loop(count) do new_count = receive do message -> handle_receive(message, count) end loop(new_count) end def handle_receive({:log, msg}, count) do IO.puts msg count + 1 end def handle_receive({:print_stats}, count) do IO.puts "I've logged #{count} messages" count end def handle_receive({:return_stats, caller}, count) do send(caller, {:stats, count}) count end def handle_receive(other, count) do IO.puts "Unhandled message of #{inspect other} received by logger" count endend |
Параллельная карта
Для окончательного примера давайте посмотрим на выполнение параллельной карты.
Мы будем сопоставлять список URL-адресов с их возвращенным кодом состояния HTTP. Если бы мы делали это без параллелизма, наша скорость была бы суммой скорости проверки каждого URL. Если бы у нас их было пять, и каждому потребовалась секунда, проверка всех URL-адресов заняла бы примерно пять секунд. Если бы мы могли проверить их параллельно, промежуток времени был бы около одной секунды, времени самого медленного URL, поскольку они происходят одновременно.
Наша тестовая реализация выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
defmodule StatusesTest do use ExUnit.Case test "parallel status map" do urls = [ ] assert Statuses.map(urls) == [ {url1, 200}, {url2, 200}, {url3, 500}, {url4, 200}, {url5, 200} ] endend |
Теперь для реализации актуального кода. Я добавил комментарии, чтобы было понятно, что делает каждый шаг.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
defmodule Statuses do def map(urls) do # Put self into variable to send to spawned process caller = self() urls # Map the URLs to a spawns process. Remember a `pid` is returned. |> Enum.map(&(spawn(fn -> process(&1, caller) end))) # Map the returned pids |> Enum.map(fn pid -> # Receive the response from this pid receive do {^pid, url, status} -> {url, status} end end) end def process(url, caller) do status = case HTTPoison.get(url) do {:ok, %HTTPoison.Response{status_code: status_code}} -> status_code {:error, %HTTPoison.Error{reason: reason}} -> {:error, reason} end # Send message back to caller with result send(caller, {self(), url, status}) endend |
Когда мы запустили код, это заняло 2,2 секунды. Это имеет смысл, потому что один из URL-адресов — это фальшивый URL-сервис, который, как мы сказали, задерживает ответ на две секунды … так что это заняло примерно время самого медленного URL-адреса.
Куда пойти отсюда?
В этой статье мы рассмотрели основы создания нового процесса, отправки этому процессу сообщения, поддержания состояния в процессе с помощью рекурсивного цикла и получения сообщений от других процессов. Это хорошее начало, но есть гораздо больше!
Elixir поставляется с некоторыми очень полезными модулями, которые помогут нам удалить некоторые из шаблонов, связанных с тем, что мы сделали сегодня. Agent — это модуль для поддержания состояния в процессе. Task — это модуль для одновременного выполнения кода и при необходимости получения его ответа. GenServer обрабатывает как государственные, так и параллельные задачи в длительном процессе. Я планирую освещать эти темы во второй статье этой серии.
Наконец, есть целая тема связывания, мониторинга и реагирования на ошибки, которые могут возникнуть в процессе. Elixir поставляется с модулем Supervisor для этого и является частью построения надежной отказоустойчивой системы.
| Ссылка: | Параллельность в Elixir от нашего партнера JCG Ли Хэллидея в блоге Codeship Blog . |