Примечание редактора: Это сообщение от членов PMC Apache Flink Фабиана Хуеске и Костаса Цумаса . Фабиан и Костас также являются соучредителями Data Artisans.
Очень большая часть сегодняшней обработки данных выполняется для данных, которые постоянно создаются, например, данных из журналов активности пользователей, веб-журналов, машин, датчиков и транзакций базы данных. До настоящего времени технология потоковой передачи данных отсутствовала в нескольких областях, таких как производительность, корректность и работоспособность, что заставляло пользователей создавать свои собственные приложения для обработки и анализа этих непрерывных потоков данных или (ab) использовать инструменты пакетной обработки для имитации непрерывного приема и обработки данных. анализ трубопроводов.
Это уже не так, поскольку технология потоковой передачи уже сформировалась и быстро внедряется на предприятии. Написание приложений данных поверх потоковых данных имеет несколько преимуществ:
- Это уменьшает общую задержку, поскольку данные не обязательно должны быть перемещены в файловую систему или базу данных, прежде чем они станут полезными для аналитики.
- Это упрощает архитектуру инфраструктуры данных, так как обслуживать и координировать гораздо меньше движущихся частей, чтобы обеспечить своевременные ответы от сигналов данных.
- Это делает измерение времени явным, связывая каждую запись данных с ее временной меткой и позволяя аналитикам обрабатывать и группировать события на основе этих временных меток.
В целом, потоковая технология обеспечивает очевидное: непрерывную обработку данных, которые естественным образом создаются непрерывными реальными источниками (которые являются наиболее «большими» наборами данных).
Apache Flink — это распределенная платформа с открытым исходным кодом для потоковой и пакетной обработки с долгой историей инноваций и проект верхнего уровня Apache Software Foundation с сообществом из более чем 150 участников. В этом посте мы сосредоточимся на возможностях потоковой обработки системы. Flink 0.10, последний выпуск Apache Flink и результат работы около 80 человек, принес ряд новых функций, которые выделяют Flink как систему потоковой обработки в пространстве с открытым исходным кодом.
- Поддержка времени событий и потоков не по порядку. В действительности потоки событий редко поступают в том порядке, в котором они были созданы, особенно потоки из распределенных систем и устройств. До сих пор программисту приложения приходилось исправлять этот «сдвиг времени» или просто игнорировать его и принимать неточные результаты, поскольку потоковые системы (по крайней мере, с открытым исходным кодом) не поддерживали время события. Flink 0.10 — это первый движок с открытым исходным кодом, который поддерживает потоки не по порядку и время события.
- Выразительные и простые в использовании API-интерфейсы в Scala и Java: API-интерфейс Flink DataStream портирует множество операторов, которые хорошо известны по API-интерфейсам пакетной обработки, таким как map, Reduce и Join. Кроме того, он предоставляет специфичные для потока операции, такие как window, split и connect. Первоклассная поддержка пользовательских функций облегчает реализацию пользовательского поведения приложения. DataStream API доступен в Scala и Java.
- Поддержка сеансов и невыровненных окон. Большинство потоковых систем имеют некоторую концепцию оконного режима, то есть группировку событий, основанную на некоторой функции времени. К сожалению, во многих системах эти окна жестко запрограммированы и связаны с внутренним контрольным механизмом системы. Flink — это первый потоковый движок с открытым исходным кодом, который полностью отделяет управление окнами от отказоустойчивости, допуская более богатые формы окон , такие как сеансы.
- Согласованность, отказоустойчивость и высокая доступность: Flink гарантирует постоянные обновления состояния при наличии сбоев (часто называемых «точно однократной обработкой») и согласованное перемещение данных между выбранными источниками и приемниками (например, согласованное перемещение данных между Kafka и HDFS) , Flink также поддерживает мастер восстановления после отказа, устраняя любую точку отказа.
- Низкая задержка и высокая пропускная способность. Мы работали с Flink со скоростью 1,5 миллиона событий в секунду на ядро , а также наблюдали задержки в диапазоне 25 миллисекунд для заданий, которые включают перестановку сетевых данных. Используя ручку настройки, пользователи Flink могут выбирать компромисс между задержкой и пропускной способностью, что делает систему пригодной как для приема и преобразования данных с высокой пропускной способностью, так и для приложений со сверхнизкой задержкой (миллисекундный диапазон).
- Интеграция: Flink интегрируется с широким спектром систем с открытым исходным кодом для ввода и вывода данных (например, HDFS, Kafka, Elasticsearch, HBase и др.), Развертывания (например, YARN), а также выступает в качестве механизма выполнения для других сред (например, Каскадирование, инкубация Apache Beam или Google Cloud Dataflow). Сам проект Flink поставляется в комплекте со слоем совместимости Hadoop MapReduce, слоем совместимости Storm, а также библиотеками для машинного обучения и обработки графиков.
- Поддержка пакетной обработки. В Flink пакетная обработка представляет собой особый случай потоковой обработки, поскольку конечные источники данных — это просто потоки, которые заканчиваются. Flink предлагает полный набор инструментов для пакетной обработки с выделенным API DataSet и библиотеками для машинного обучения и обработки графиков. Кроме того, Flink содержит несколько специфических для каждой партии оптимизаций (например, для планирования, управления памятью и оптимизации запросов), соответствующих и даже превосходящих выделенные механизмы пакетной обработки в случаях пакетного использования.
- Продуктивность разработчика и простота эксплуатации: Flink работает в различных средах. Локальное выполнение в среде IDE значительно облегчает разработку и отладку приложений Flink. В распределенных установках Flink работает в широком масштабе. Режим YARN позволяет пользователям вызывать кластеры Flink за считанные секунды. Flink обслуживает мониторинг показателей заданий и системы в целом через четко определенный интерфейс REST. Встроенная веб-панель отображает эти показатели и делает мониторинг Flink очень удобным.
Flink в стеке инфраструктуры данных
Flink — это среда обработки потоков, не зависящая от хранилища, и, таким образом, она используется в сочетании с системами хранения данных или брокерскими системами. Типичным архитектурным паттерном является использование Flink совместно с Apache Kafka для:
- Вводите данные в другие системы, такие как HDFS, базы данных или поисковые индексы, и создавайте непрерывные конвейеры ETL.
- Выполняйте аналитику непосредственно на движущихся данных, чтобы создавать оповещения, информационные панели или мощные рабочие приложения, устраняя необходимость в приеме и ETL.
- Выполняйте машинное обучение в потоках, непрерывно создавая модели событий по мере их поступления и используя модель для предоставления онлайн-рекомендаций.
Поскольку Flink также является полноценной системой для пакетной обработки, ее также можно использовать для приложений поверх статических данных. На следующем рисунке представлен обзор того, где приложения Flink могут поместиться в более широкий стек:
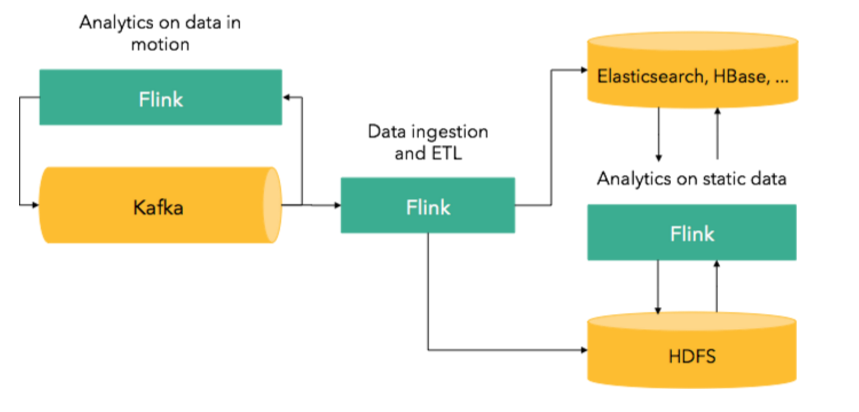
Мы видели, как Flink использовался для различных случаев использования, таких как мониторинг оборудования, анализ сгенерированных машинами журналов, аналитика данных об активности клиентов, системы онлайн-рекомендаций и приложения для обработки графиков. Посмотрите доклады Flink Forward этого года, чтобы узнать, как компании используют Flink.
Ручная обработка потока с помощью Flink
Теперь, когда вы понимаете функции потоковой обработки Apache Flink, пришло время взглянуть на возможности API-интерфейса DataStream и ознакомиться с тремя примерами приложений. Мы публикуем полностью упакованные реализации этих примеров на Github и призываем вас запускать эти программы в вашей IDE и играть с кодом. Все, что вам нужно сделать, это следовать инструкциям, размещенным в репозитории , которые помогут вам импортировать код в вашу IDE, запустить пример приложения из вашей IDE и отслеживать ход выполнения с помощью веб-панели Flink.
Наши демонстрационные приложения обрабатывают поток событий поездки на такси, которые происходят из общедоступного набора данных Комиссии по такси и лимузинам Нью-Йорка (TLC). Набор данных состоит из записей о поездках на такси в Нью-Йорке с 2009 по 2015 гг. Мы взяли некоторые из этих данных и преобразовали их в набор данных о поездках на такси, разделив каждую запись поездки на начало поездки и событие окончания поездки. События имеют следующую схему:
|
1
2
3
4
5
6
|
rideId: Long // unique id for each ridetime: DateTime // timestamp of the start/end eventisStart: Boolean // true = ride start, false = ride endlocation: GeoPoint // lon/lat of pick-up/drop-off locationpassengerCnt: short // number of passengerstravelDist: float // total travel distance, -1 on start events |
Мы реализовали пользовательскую SourceFunction для обслуживания DataStream[ TaxiRide ] из набора данных событий поездки. Чтобы генерировать поток настолько реалистично, насколько это возможно, события генерируются по их временным меткам. Два события, которые произошли через десять минут друг за другом, на самом деле подаются через десять минут Коэффициент ускорения может быть указан для «ускоренной перемотки» потока, т. Е. С коэффициентом ускорения два события обрабатываются с интервалом в пять минут. Кроме того, мы можем указать максимальную задержку обслуживания, которая приводит к случайной задержке событий в пределах границы для имитации потока вне очереди. Все примеры работают в режиме времени события. Это гарантирует стабильные результаты даже в случае исторических данных или данных, которые доставляются не по порядку. Обратите внимание, что потоки вне очереди очень распространены в реальных приложениях, особенно если события происходят из нескольких источников, таких как распределенные сенсорные сети.
Определите популярные места
Для нашего первого демонстрационного приложения мы хотим определить места в Нью-Йорке, куда многие люди приезжают на такси. Мы внедрили это приложение как TotalArrivalCount.scala и проведем вас шаг за шагом по программе.
Сначала мы получаем StreamExecutionEnvironment и устанавливаем TimeCharacteristic в EventTime. Обработка времени события гарантирует, что программа вычисляет согласованные результаты, даже если события поступают не по порядку на потоковом процессоре.
|
1
2
|
val env: StreamExecutionEnvironment = DemoStreamEnvironment.envenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) |
Затем мы определяем источник данных, который генерирует DataStream[TaxiRide] с задержкой обслуживания не более 60 секунд (события выходят из строя не более чем на 1 минуту) и коэффициентом ускорения 600 (события, произошедшие за 10 минут, обрабатываются в течение 1 секунды).
|
1
2
3
|
// Define the data sourceval rides: DataStream[TaxiRide] = env.addSource(new TaxiRideSource( “./data/nycTaxiData.gz”, 60, 600.0f)) |
Поскольку нас интересуют только те места, куда люди ездят (а не туда, откуда они приходят) и поскольку данные немного беспорядочные (местоположения не всегда указаны правильно), мы сначала применяем несколько фильтров для очистки данных.
|
1
2
3
4
5
|
val cleansedRides = rides // filter for trip end events .filter( !_.isStart ) // filter for events in NYC .filter( r => NycGeoUtils.isInNYC(r.location) ) |
Поток поездки на такси определяет места событий как координаты с непрерывными значениями долготы / широты. Нам нужно отобразить их в конечный набор регионов, чтобы иметь возможность агрегировать события по местоположению. Мы делаем это, определяя сетку из примерно 100 × 100-метровых ячеек в районе Нью-Йорка. Мы используем служебный класс ( NycGeoUtils.scala ) для сопоставления местоположений событий с идентификаторами ячеек и извлечения метки времени события и количества пассажиров следующим образом:
|
1
2
3
4
5
|
// map location coordinates to cell Id, timestamp, and passenger countval cellIds: DataStream[(Int, Long, Short)] = cleansedRides.map { r => ( NycGeoUtils.mapToGridCell(r.location), r.time.getMillis, r.passengerCnt )} |
После этих подготовительных шагов у нас есть данные, которые мы хотели бы объединить. Поскольку мы хотим вычислить количество пассажиров для каждого местоположения (идентификатор ячейки), мы начнем с ввода потока по идентификатору ячейки (_._ 1). Это в основном организует и разделяет поток по идентификатору ячейки. Впоследствии мы применяем преобразование сгиба к каждому ключевому разделу, чтобы вычислить сумму всех пассажиров и последнюю временную метку. Преобразование сгиба начинается с начального значения (0, 0, 0) и вычисляет сумму, добавляя по одной записи за раз. Поскольку функция сгиба агрегирует бесконечный поток, она возвращает текущее значение агрегации для каждой входной записи, т. Е. Отправляет обновленный счетчик.
|
1
2
3
4
5
6
|
val passengerCnts: DataStream[(Int, Long, Int)] = cellIds // key stream by cell Id .keyBy(_._1) // sum passengers per cell Id and update time .fold((0, 0L, 0), (s: (Int, Long, Int), r: (Int, Long, Short)) => { (r._1, s._2.max(r._2), s._3 + r._3) } ) |
Наконец, мы переводим идентификатор ячейки обратно в GeoPoint (который является центром ячейки), печатаем поток результатов в стандартный вывод и начинаем выполнение программы.
|
1
2
3
4
5
6
7
8
9
|
val cntByLocation: DataStream[(Int, Long, GeoPoint, Int)] = passengerCnts // map cell Id back to GeoPoint .map( r => (r._1, r._2, NycGeoUtils.getGridCellCenter(r._1), r._3 ) )cntByLocation // print to console .print()env.execute(“Total passenger count per location”) |
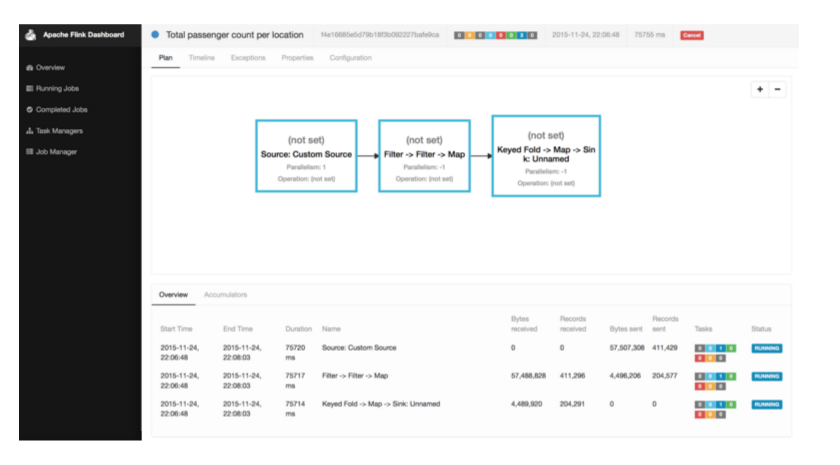
Когда вы запустите программу TotalArrivalCount.scala в вашей IDE, вы увидите сообщения журнала для инициализации программы, планирования ее операторов и запуска обработки потока данных, а также вывода программы, выводимой на стандартный вывод. Flink также запустит свою веб-панель, к которой вы можете получить доступ, открыв http: // localhost: 8081 в вашем браузере. Панель мониторинга отображает статистику мониторинга запущенных программ и системы в целом, помогает анализировать поведение выполненных заданий и предоставляет доступ к файлам конфигурации и журналов. На следующем снимке экрана показан обзор выполнения задания на панели мониторинга.
Определите популярные места за последние 15 минут
Наше первое демонстрационное приложение вычисляет для каждого местоположения общее количество людей, которые прибыли на такси. Хотя это помогает идентифицировать популярные места в целом, оно также скрывает много информации, такой как изменения во времени. В нашем следующем примере мы определяем места, которые популярны в течение определенного периода времени, т.е. мы вычисляем каждые 5 минут количество пассажиров, которые прибыли в каждое место в течение последних 15 минут на такси. Этот вид вычислений известен как операция со скользящим окном.
Основная структура нашей программы скользящего окна SlidingArrivalCount.scala очень похожа на программу нашего первого примера. Мы очищаем поток и сопоставляем координаты местоположения с идентификатором ячейки и извлекаем количество пассажиров. Получив это, мы снова вводим поток по идентификатору ячейки, как и раньше, но вместо применения оператора сгиба к потоку с WindowFunction мы определяем скользящее временное окно и запускаем WindowFunction , вызывая apply():
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
val passengerCnts: DataStream[(Int, Long, Int)] = cellIds // key stream by cell Id .keyBy(_._1) // define sliding window on keyed streams .timeWindow(Time.minutes(15), Time.minutes(5)) // count events in window .apply { ( cell: Int, window: TimeWindow, events: Iterable[(Int, Short)], out: Collector[(Int, Long, Int)]) => out.collect( ( cell, window.getEnd, events.map( _._2 ).sum ) ) } |
Операция timeWindow() группирует события потока в конечные наборы записей, к которым может применяться окно или функция агрегирования. В нашем примере мы вызываем apply() для обработки окон с помощью WindowFunction . WindowFunction получает четыре параметра: WindowFunction , содержащий ключ окна, объект TimeWindow который содержит такие сведения, как время начала и окончания окна, Iterable всех элементов в окне и Collector для сбора выпущенных записей. с помощью WindowFunction . Мы хотим посчитать количество пассажиров, прибывающих в течение времени, определенного окном. Следовательно, мы должны выдать одну запись, которая содержит идентификатор ячейки сетки, время окончания окна и сумму подсчетов пассажира, который рассчитывается путем извлечения подсчетов отдельных пассажиров из Iterable ( events.map( _._2) ) и суммируя их ( .sum ).
Наконец, мы отображаем ячейку сетки обратно в GeoPoint, как и раньше, и печатаем полученный поток. Эта программа будет производить каждые пять минут одну запись для каждого местоположения, которое получило хотя бы одного пассажира такси. Обратите внимание, что при обработке времени события синхронизируются временные окна, то есть окна всех ключей оцениваются в одно и то же логическое время.
Вычислить ранние подсчеты для популярных мест
Демонстрационное приложение со скользящим окном вычисляет каждые 5 минут, сколько прибывает для каждого местоположения за последние 15 минут. Однако некоторым приложениям может потребоваться более своевременная информация для немедленного реагирования, такого как создание оповещения. В нашем последнем примере мы хотим вычислить количество скользящих окон, как в нашем предыдущем примере, но в дополнение мы хотим получить ранний счет всякий раз, когда несколько человек из 50 человек прибыли в какое-либо место в пределах временных рамок окна (15 минут), то есть, мы хотели бы получить частичные подсчеты для окна, когда его количество поступлений превышает 50, 100, 150 и так далее.
DataStream API от Flink предлагает интерфейс Trigger для точного контроля, когда оценивается окно, т.е. когда вызывается оконная функция. В нашем последнем примере программы EarlyArrivalCount.scala повторно используется код для очистки потока и назначения идентификаторов ячеек событиям, как и раньше. Здесь мы только показываем код для вычисления частичного и окончательного количества прибытия:
|
01
02
03
04
05
06
07
08
09
10
|
val passengerCnts: DataStream[(Int, Long, Int)] = cellIds // key stream by cell Id .keyBy( _._1 ) // define sliding window on keyed streams .timeWindow(Time.mintes(15), Time.minutes(5)) .trigger(new EarlyCountTrigger(50)) // count events in window .apply( (cell, window, events, out: Collector[(Int, Long, Int)]) => { out.collect((cell, window.getEnd, events.map( _._2 ).sum )) }) |
Сравнивая этот фрагмент кода с кодом примера скользящего окна ( SlidingArrivalCount.scala ), мы видим, что keyBy(), timeWindow() и apply() точно такие же, как и раньше. Есть только одно отличие, а именно строка, которая определяет наш пользовательский триггер. Определяя пользовательский триггер, мы перезаписываем триггер по умолчанию временного окна, который будет оценивать окно (вызывать оконную функцию) в конце его определенного временного интервала.
Интерфейс Trigger API DataStream определяет три метода:
-
onElement(), который вызывается для каждого элемента, который входит в окно. -
onEventTime(), который вызывается, когда истекает ранее зарегистрированный таймер времени события. -
onProcessingTime(), который вызывается, когда истекает ранее зарегистрированный триггер времени обработки.
Наша пользовательская реализация триггера EarlyCountTrigger реализует эти методы следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
override def onElement( event: (Int, Short), timestamp: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = { // register event time timer for end of window ctx.registerEventTimeTimer(window.getEnd) // get current count val personCnt = ctx.getKeyValueState[Integer]("personCnt", 0) // update count by passenger cnt of new event personCnt.update(personCnt.value() + event._2) // check if count is high enough for early notification if (personCnt.value() < triggerCnt) { // not there yet TriggerResult.CONTINUE } else { // trigger count is reached personCnt.update(0) TriggerResult.FIRE }} |
Метод onElement() нашего пользовательского триггера сначала регистрирует таймер времени события для определенного времени окончания окна. Этот таймер гарантирует, что метод onEventTime() вызывается в конце окна, чтобы вычислить окончательный результат. Затем мы получаем состояние триггера, который представляет собой простое Integer которое содержит текущее количество пассажиров. На данном этапе мы используем интерфейс Flink для управляемого состояния, чтобы гарантировать, что состояние триггера периодически проверяется и последовательно восстанавливается в случае сбоя. Затем мы обновляем состояние количества пассажиров по количеству событий, которое было добавлено в окно, и проверяем, превышен ли порог. Если это не так, TriggerResult.CONTINUE возвращается, чтобы сигнализировать, что обработка продолжается. Если порог превышен, мы сбрасываем состояние счета до нуля и возвращаем TriggerResult.FIRE который заставляет оконную функцию оценивать окно (Примечание: FIRE не удаляет элементы из окна).
|
1
2
3
4
5
6
7
8
|
override def onEventTime( time: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = { // trigger final computation TriggerResult.FIRE_AND_PURGE} |
Как только время события onEventTime() конечное время окна, onEventTime() метод onEventTime() который возвращает TriggerResult.FIRE_AND_PURGE чтобы вычислить окончательный результат окна и, наконец, удалить все элементы из окна.
Метод onProcessingTime() не реализован, потому что мы работаем в режиме времени события и не регистрируем таймер времени обработки в нашем триггере.
Определяя скользящее окно и наш пользовательский триггер, мы реализуем желаемое поведение нашего последнего демонстрационного приложения. Программа вычисляет количество скользящих окон, но выдает частичные значения, если превышены определенные пороговые значения. Частичные счета постоянно обновляются новыми частичными счетами и, в конечном счете, окончательным счетом.
Временные окна и триггеры — не единственные концепции, поддерживаемые API-интерфейсом Flink DataStream для группировки потоковых событий. В дополнение к интерфейсу Trigger , API-интерфейс DataStream предлагает интерфейс Evictor для удаления элементов из начала окна до его оценки. Кроме того, вы можете определить CountWindows которые оценивают оконные функции на основе количества событий, и GlobalWindows которые собирают все данные и GlobalWindows вам возможность определять политики триггеров и исключать элементы. Имея под рукой окна, триггеры, эвикторы и оконные функции, вы получаете очень выразительный набор инструментов для точного определения настраиваемой оконной логики для ваших потоковых приложений.
Визуализация потоков данных с Kibana
Flink предлагает несколько соединителей для записи потоков данных в системы хранения, такие как Apache Kafka, HDFS и Elasticsearch. Возможно, вы заметили, что наши демонстрационные приложения содержат код для записи рассчитанного количества поступлений в Elasticsearch . Когда данные находятся в Elasticsearch, мы можем использовать Kibana , панель инструментов для визуализации данных, хранящихся в Elasticsearch , для построения графиков местоположений на карте и для анализа результатов наших программ. На следующем снимке экрана показано, как Kibana визуализирует результаты потоковой программы, которая вычисляет популярные местоположения в Нью-Йорке.
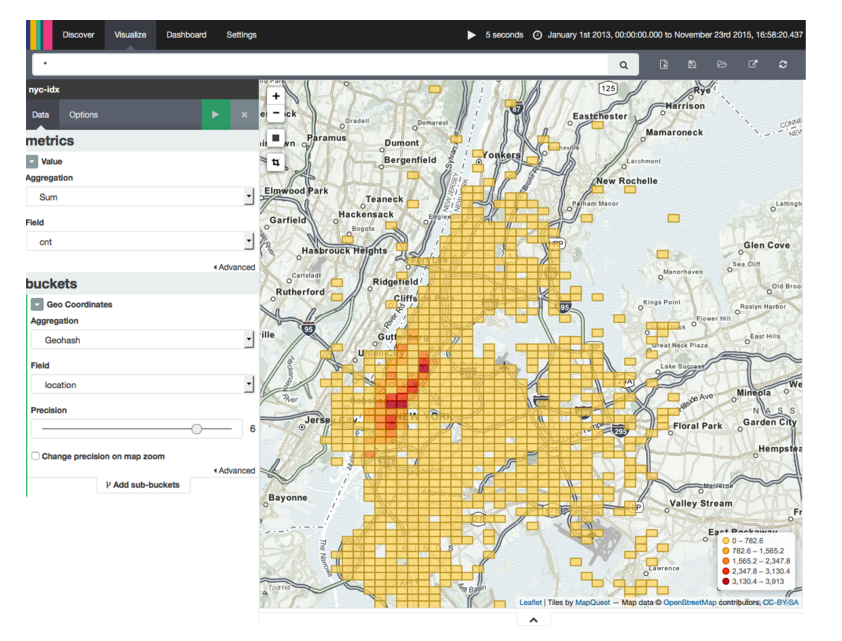
Мы предоставляем подробные инструкции по настройке Elasticsearch и Kibana в нашем репозитории Github . Посмотрите, хотите ли вы поиграть с Flink, Elasticsearch и Kibana.
Завершение
Apache Flink — это готовый к работе распределенный потоковый процессор с конкурентоспособным набором функций. Поддержка неупорядоченных потоков событий, обработки времени событий и очень гибкая механика управления окнами выделяют Flink среди решений для обработки потоков с открытым исходным кодом. В этом посте мы представили три демонстрационных приложения и продемонстрировали выразительную мощь окон в Flink DataStream API. Код доступен на Github, и мы приглашаем вас импортировать примеры в вашу среду IDE, чтобы поиграть и самостоятельно изучить Flink.
С точки зрения архитектуры предприятия, примером которой является архитектура Zeta, Flink может служить гибким вычислительным механизмом для очень большого разнообразия форматов данных. Flink может считывать данные из различных источников данных, таких как распределенные файловые системы (включая HDFS, MapR-FS и все HDFS-совместимые файловые системы), базы данных (такие как HBase и MapR-DB) и очереди сообщений (например, MapR). Ручьи и кафки). В настоящее время Flink может работать на YARN и в Mesos с использованием Myriad, и в настоящее время предпринимаются попытки заставить Flink работать на Mesos. Наконец, Flink может выступать в качестве вычислительного механизма и для других API. В настоящее время Flink поставляется со слоем совместимости для Apache Storm , а для потоков данных (недавно предложенного проекта Apache Beam) есть бегуны на Flink и каскадные на Flink .
Об авторах:

Фабиан Хьюске является членом PMC Apache Flink. Он вносит свой вклад в Flink с самых первых дней, когда он начинал как исследовательский проект в рамках своей аспирантуры в TU Berlin. Фабиан проходил практику в IBM Research, SAP Research и Microsoft Research и является соучредителем Data Artisans .

Костас Цумас является соучредителем и генеральным директором Data Artisans , компании, созданной первоначальными создателями Apache Flink Framework, и членом PMC Apache Flink. Прежде чем основать данные Artisans, Костас работал докторантом в TU Berlin, в Microsoft Research и Ольборгском университете.
| Ссылка: | Основное руководство по потоковой обработке в первую очередь с Apache Flink от нашего партнера по JCG Фабиана Хуеске в блоге Mapr . |