За последние 20 лет было проведено много исследований в области обработки изображений документов, но мало было проведено исследований с точки зрения параллельной обработки. Некоторые из решений, предложенных для параллельной обработки, заключались в создании потоков выполнения для каждого изображения или использовании GNU Parallel .
В этом посте вы узнаете, как использовать платформу больших данных для параллельной обработки изображений. Это решение было реализовано для одного из наших клиентов в сфере здравоохранения, медицинские изображения сканируются и становятся доступными для поиска данных. Для извлечения текста из изображений используется программное обеспечение оптического распознавания символов (OCR) под названием Tesseract. Извлеченный текст из графических документов хранится на платформе MapR для быстрого поиска. В этом сценарии использования используется формат изображения TIFF, который можно расширить и применить к другим типам изображений.
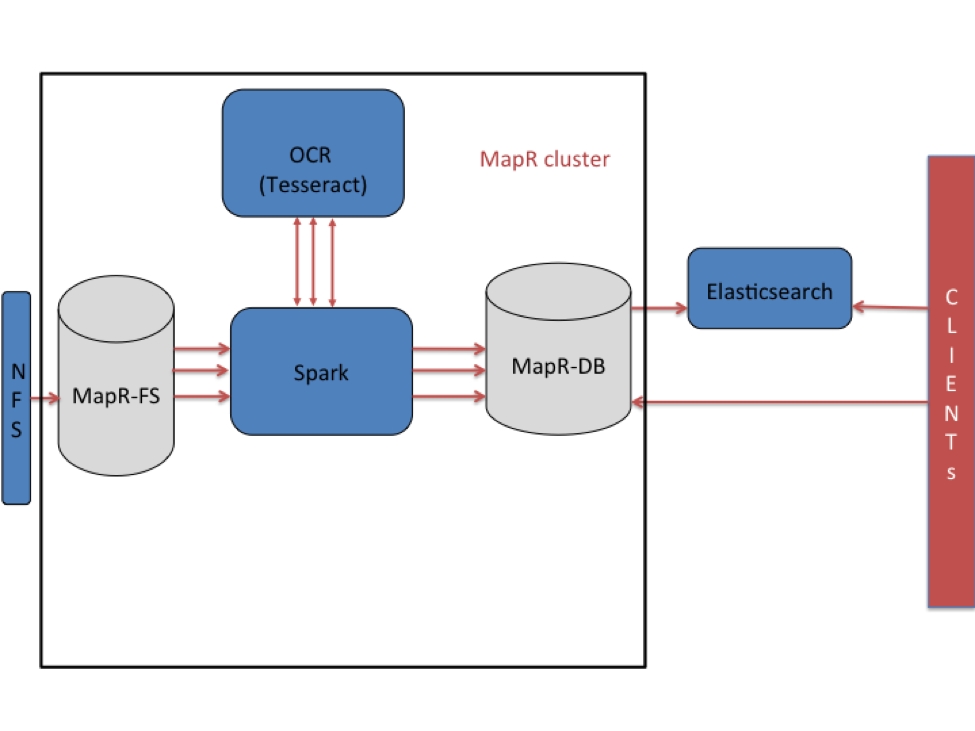
Архитектура высокого уровня
В этом случае использования изображения хранятся в файловой системе MapR (MapR-FS) и обрабатываются с использованием программного обеспечения Apache Spark и OCR. Файлы попадают через монтирование NFS в MapR-FS. Как только файлы попадают в MapR-FS, их можно читать и обрабатывать последовательно. Для распараллеливания обработки используется структура Spark. Встроенный текст извлекается с помощью Tesseract, а извлеченный текст помещается в MapR-DB. Tesseract — это механизм оптического распознавания текста с открытым исходным кодом, который был первоначально разработан в лаборатории HP, а затем выпущен как программное обеспечение с открытым исходным кодом и спонсируется Google. Основываясь на моих исследованиях, Tesseract — самая точная библиотека с открытым исходным кодом для распознавания текста.
С выпуском MapR 5.0 в Elasticsearch можно создавать внешние поисковые индексы для столбцов, семейств столбцов или целых таблиц в MapR-DB. Таблицы в MapR-DB включены с репликацией Elasticsearch, так как данные вставляются в таблицы и индексируются в Elasticsearch. То есть извлеченный текст и метаданные, хранящиеся в таблицах MapR-DB, будут автоматически реплицированы и проиндексированы в Elasticsearch. Поскольку модель данных с широкими столбцами в MapR-DB изначально поддерживает несколько версий данных, в MapR-DB может храниться несколько версий документа. Последняя версия в таблице MapR-DB индексируется в Elasticsearch.
Установка Тессеракта
На компьютере с Linux войдите как «root» и следуйте инструкциям ниже:
# yum install tesseract
# yum install leptonica
Описание схемы таблицы MapR-DB
Схема для таблицы проста. Ключ строки состоит из идентификатора документа, который является именем файла без суффикса. Существует одно семейство столбцов «cf» с двумя столбцами «info» и «data». Первый предназначен для хранения метаданных, а другой — для извлеченного текста. Путь к файлу будет сохранен в столбце «информация». Клиенты смогут выполнять поиск, используя текст и метаданные в индексах Elasticsearch. Как только запись найдена, весь документ может быть извлечен с использованием пути к файлу исходного документа.
Создание таблицы MapR-DB
Таблицы могут быть созданы программно с помощью Java API или оболочки HBase. Вот инструкции по использованию оболочки:
|
1
2
3
|
$ hbase shellhbase(main):001:0> create '/user/user01/datatable', 'cf' |
где «/ user / user01 / datatable» — это путь к таблице данных, а «cf» — это семейство столбцов с количеством версий по умолчанию.
Следуйте краткому руководству по включению Elasticsearch Replication
Установите Elasticsearch, загрузив его с rubber.co .
|
1
2
3
4
5
|
$ /opt/mapr/bin/register-elasticsearch -r localhost -e /opt/mapr/QSS/miner/elasticsearch-2.2.0 -u mapr -y -c maprdemoes$ /opt/mapr/bin/register-elasticsearch -l$ maprcli table replica elasticsearch autosetup -path /srctable -target maprdemoes -index sourcedoc -type json |
Tesseract с открытым исходным кодом использует библиотеку обработки изображений Leptonica. Чтобы прочитать изображения, обработать и сохранить документы, скачать исходный код , собрать его и запустить программу. Код Spark в Java читает двоичные файлы, как показано ниже.
Чтение файлов изображений
Для чтения изображений API двоичного кода () вызывается в JavaStreamingContext. Этот API читает только двоичные файлы изображений; После прочтения каждый файл обрабатывается в методе processFile ().
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
JavaPairRDD<String, PortableDataStream> readRDD = jsc.binaryFiles(inputPath);readRDD.map(new Function<Tuple2<String, PortableDataStream>, String>() { @Override public String call(Tuple2<String, PortableDataStream> pair) { String fileName = StringUtils.remove(pair._2.getPath(), "maprfs://"); processFile(StringUtils.remove(fileName, "file:")); return null; }}).collect(); |
В методе «processFile» вызывается API Tesseract для извлечения текста. Здесь документы на английском языке, поэтому API установлен на «eng».
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public static String processImageFile(String fileName) { Tesseract instance = new Tesseract(); File imageFile = new File(fileName); String resultText = null; instance.setLanguage("eng"); try { resultText = instance.doOCR(imageFile); } catch (Exception e) { e.printStackTrace(); } finally { return resultText; }} |
После того, как текст извлечен, он сохраняется в MapR-DB, вызывая метод populateDataInMapRDB (). Здесь данные хранятся в семействе столбцов «cf» и столбце «data». Метаданные файла (имя файла) хранятся в столбце «информация». Если есть еще данные, которые необходимо проиндексировать, они могут быть заполнены другим квалификатором столбца.
|
1
2
3
|
populateDataInMapRDB(config, convertedTable, rowKey, cf, "data", resultText);populateDataInMapRDB(config, convertedTable, rowKey, cf, "info", fileName); |
Запустите приложение
- Загрузите код и пример данных здесь:
git clone https://github.com/ranjitreddy2013/imageprocessing
- Создайте приложение, используя maven:
mvn clean install
- Скопируйте файл с образцом изображения, расположенный в каталоге с образцами, в каталог, в котором читается программа Spark. Смотрите inputPath, установленный в binaryFiles () api в программе.
- Чтобы вызвать программу Spark:
|
1
|
${SPARK_HOME}/bin/spark-submit --class com.mapr.ocr.text.ImageToText --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j-spark.properties" --master local[4]document-store-0.0.1-SNAPSHOT-jar-with-dependencies.jar |
После завершения программы данные должны быть реплицированы и проиндексированы в Elasticsearch.
Доступ к проиндексированному тексту из Elasticsearch:
Выполните следующий запрос для извлечения документов в Elasticsearch:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
{ "query": { "match": { "cf.info": "quick" }}, "fields" : ["_id", "cf.filepath", "cf.info"]}' | python -m json.tool |
Вывод
В этом блоге вы узнали, как программное обеспечение OCR можно использовать для сканирования документов с изображениями с помощью Spark. Вы также узнали, как извлеченный текст хранится в MapR-DB. Если для таблиц MapR-DB включена репликация Elasticsearch, индексация данных выполняется автоматически при загрузке данных в таблицу. Это делает возможность поиска извлеченного текста очень простой в управлении. Это упрощает конвейер обработки, что важно для сред, в которых постоянно растут объемы изображений для обработки.
| Ссылка: | Обработка графических документов на MapR в Scale от нашего партнера JCG Ранджита Лингаиа в блоге Mapr . |