В первой части этой серии из двух частей мы рассмотрели, как сегменты используются в облачном хранилище Google для организации файлов. Мы увидели, как управлять корзинами в Google Cloud Storage из Google Cloud Console. За этим последовал скрипт Python, в котором эти операции выполнялись программно.
В этой части я покажу, как управлять объектами, то есть файлами и папками внутри сегментов GCS. Структура этого урока будет похожа на предыдущую. Сначала я покажу, как выполнять основные операции, связанные с управлением файлами, с помощью Google Cloud Console. За этим последует сценарий Python для программного выполнения тех же операций.
Подобно тому, как присвоение имен в GCS имело некоторые рекомендации и ограничения, именование объектов также следует ряду рекомендаций . Имена объектов должны содержать допустимые символы Unicode и не должны содержать символы возврата каретки или перевода строки. Некоторые рекомендации включают в себя не использовать такие символы, как «#», «[«, «]», «*», «?» или недопустимые управляющие символы XML, потому что они могут быть неправильно истолкованы и могут привести к неоднозначности.
Кроме того, имена объектов в GCS следуют за плоским пространством имен. Это означает, что физически в GCS нет каталогов и подкаталогов. Например, если вы создадите файл с именем /tutsplus/tutorials/gcs.pdf , он будет выглядеть так, как если бы gcs.pdf в каталоге с именем tutorials который, в свою очередь, является подкаталогом tutsplus . Но согласно GCS, объект просто находится в /tutsplus/tutorials/gcs.pdf с именем /tutsplus/tutorials/gcs.pdf .
Давайте рассмотрим, как управлять объектами с помощью Google Cloud Console, а затем перейдем к сценарию Python, чтобы сделать то же самое программным способом.
Использование Google Cloud Console
Я продолжу от того, что мы оставили в последнем уроке. Начнем с создания папки.

Чтобы создать новую папку, нажмите кнопку « Создать папку» , выделенную выше. Создайте папку, указав нужное имя, как показано ниже. Имя должно соответствовать соглашениям об именах объектов .
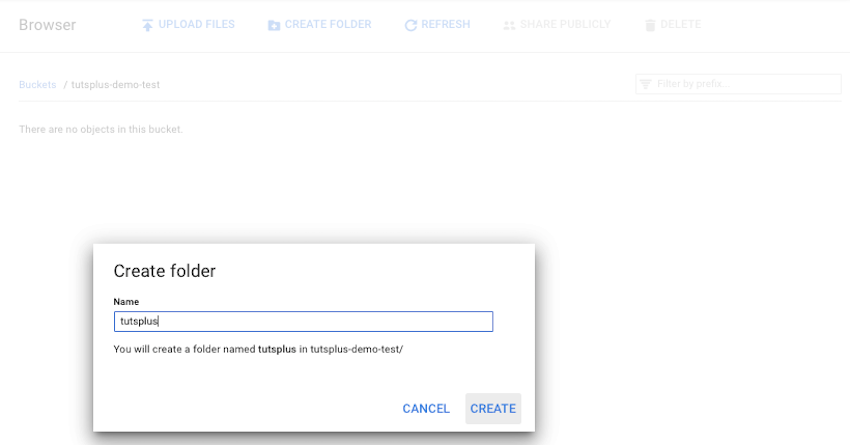
Теперь давайте загрузим файл во вновь созданную папку.
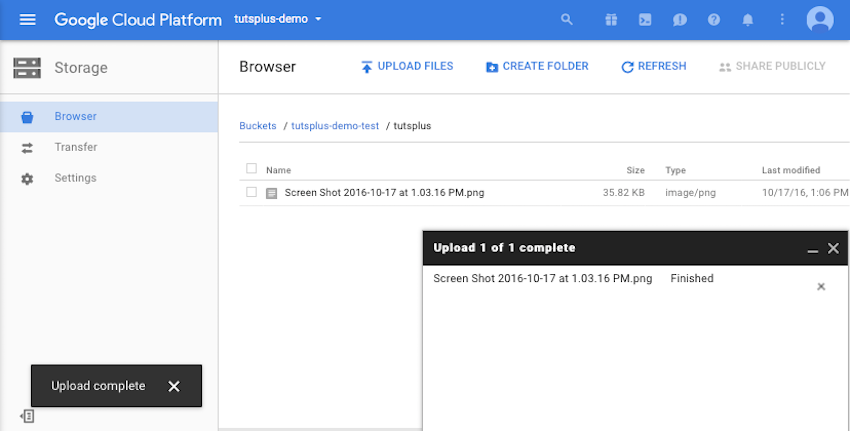
После создания браузер GCS выведет список вновь созданных объектов. Объекты можно удалить, выбрав их из списка и нажав кнопку удаления.
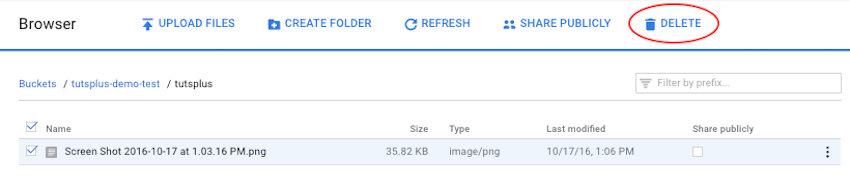
Нажатие на кнопку обновления заполняет пользовательский интерфейс любыми изменениями в списке объектов без обновления всей страницы.
Управление объектами программно
В первой части мы увидели, как создать экземпляр Compute Engine. Я буду использовать то же самое здесь и основываться на скрипте Python из последней части.
Написание скрипта Python
Для этого урока нет дополнительных шагов по установке. Обратитесь к первой части для получения более подробной информации об установке или среде разработки.
gcs_objects.py
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
import sys
from pprint import pprint
from googleapiclient import discovery
from googleapiclient import http
from oauth2client.client import GoogleCredentials
def create_service():
credentials = GoogleCredentials.get_application_default()
return discovery.build(‘storage’, ‘v1’, credentials=credentials)
def list_objects(bucket):
service = create_service()
# Create a request to objects.list to retrieve a list of objects.
fields_to_return = \
‘nextPageToken,items(name,size,contentType,metadata(my-key))’
req = service.objects().list(bucket=bucket, fields=fields_to_return)
all_objects = []
# If you have too many items to list in one request, list_next() will
# automatically handle paging with the pageToken.
while req:
resp = req.execute()
all_objects.extend(resp.get(‘items’, []))
req = service.objects().list_next(req, resp)
pprint(all_objects)
def create_object(bucket, filename):
service = create_service()
# This is the request body as specified:
# http://g.co/cloud/storage/docs/json_api/v1/objects/insert#request
body = {
‘name’: filename,
}
with open(filename, ‘rb’) as f:
req = service.objects().insert(
bucket=bucket, body=body,
# You can also just set media_body=filename, but for the sake of
# demonstration, pass in the more generic file handle, which could
# very well be a StringIO or similar.
media_body=http.MediaIoBaseUpload(f, ‘application/octet-stream’))
resp = req.execute()
pprint(resp)
def delete_object(bucket, filename):
service = create_service()
res = service.objects().delete(bucket=bucket, object=filename).execute()
pprint(res)
def print_help():
print «»»Usage: python gcs_objects.py <command>
Command can be:
help: Prints this help
list: Lists all the objects in the specified bucket
create: Upload the provided file in specified bucket
delete: Delete the provided filename from bucket
«»»
if __name__ == «__main__»:
if len(sys.argv) < 2 or sys.argv[1] == «help» or \
sys.argv[1] not in [‘list’, ‘create’, ‘delete’, ‘get’]:
print_help()
sys.exit()
if sys.argv[1] == ‘list’:
if len(sys.argv) == 3:
list_objects(sys.argv[2])
sys.exit()
else:
print_help()
sys.exit()
if sys.argv[1] == ‘create’:
if len(sys.argv) == 4:
create_object(sys.argv[2], sys.argv[3])
sys.exit()
else:
print_help()
sys.exit()
if sys.argv[1] == ‘delete’:
if len(sys.argv) == 4:
delete_object(sys.argv[2], sys.argv[3])
sys.exit()
else:
print_help()
sys.exit()
|
Приведенный выше скрипт Python демонстрирует основные операции, которые можно выполнять над объектами. Это включает:
- создание нового объекта в ведре
- распечатка всех объектов в ведре
- удаление определенного объекта
Давайте посмотрим, как выглядит каждая из вышеперечисленных операций при запуске скрипта.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
$ python gcs_objects.py
Usage: python gcs_objects.py <command>
Command can be:
help: Prints this help
list: Lists all the objects in the specified bucket
create: Upload the provided file in specified bucket
delete: Delete the provided filename from bucket
$ python gcs_objects.py list tutsplus-demo-test
[{u’contentType’: u’application/x-www-form-urlencoded;charset=UTF-8′,
u’name’: u’tutsplus/’,
u’size’: u’0′},
{u’contentType’: u’image/png’,
resp = req.execute()
u’name’: u’tutsplus/Screen Shot 2016-10-17 at 1.03.16 PM.png’,
u’size’: u’36680′}]
$ python gcs_objects.py create tutsplus-demo-test gcs_buckets.py
{u’bucket’: u’tutsplus-demo-test’,
u’contentType’: u’application/octet-stream’,
u’crc32c’: u’XIEyEw==’,
u’etag’: u’CJCckonZ4c8CEAE=’,
u’generation’: u’1476702385770000′,
u’id’: u’tutsplus-demo-test/gcs_buckets.py/1476702385770000′,
u’kind’: u’storage#object’,
u’md5Hash’: u’+bd6Ula+mG4bRXReSnvFew==’,
u’mediaLink’: u’https://www.googleapis.com/download/storage/v1/b/tutsplus-demo-test/o/gcs_buckets.py?generation=147670238577000
0&alt=media’,
u’metageneration’: u’1′,
u’name’: u’gcs_buckets.py’,
u’selfLink’: u’https://www.googleapis.com/storage/v1/b/tutsplus-demo-test/o/gcs_buckets.py’,
u’size’: u’2226′,
u’storageClass’: u’STANDARD’,
u’timeCreated’: u’2016-10-17T11:06:25.753Z’,
u’updated’: u’2016-10-17T11:06:25.753Z’}
$ python gcs_objects.py list tutsplus-demo-test
[{u’contentType’: u’application/octet-stream’,
u’name’: u’gcs_buckets.py’,
u’size’: u’2226′},
{u’contentType’: u’application/x-www-form-urlencoded;charset=UTF-8′,
u’name’: u’tutsplus/’,
u’size’: u’0′},
{u’contentType’: u’image/png’,
u’name’: u’tutsplus/Screen Shot 2016-10-17 at 1.03.16 PM.png’,
u’size’: u’36680′}]
$ python gcs_objects.py delete tutsplus-demo-test gcs_buckets.py
»
$ python gcs_objects.py list tutsplus-demo-test
[{u’contentType’: u’application/x-www-form-urlencoded;charset=UTF-8′,
u’name’: u’tutsplus/’,
u’size’: u’0′},
{u’contentType’: u’image/png’,
u’name’: u’tutsplus/Screen Shot 2016-10-17 at 1.03.16 PM.png’,
u’size’: u’36680′}]
|
Вывод
В этой серии руководств мы увидели, как Google Cloud Storage работает с высоты птичьего полета, после чего был проведен углубленный анализ контейнеров и объектов. Затем мы увидели, как выполнять основные операции с корзинами и объектами с помощью Google Cloud Console.
Затем мы выполнили то же самое, используя скрипты Python. С помощью облачного хранилища Google можно сделать гораздо больше, но это еще не все.