Во всяком случае, наши беседы на jOOQ на различных JUG и конференциях показали, в основном, одно:
Java-разработчики не знают SQL.
И это даже не обязательно наша вина. Сейчас мы просто не знакомы с SQL.
Но учтите следующее: мы, разработчики (или наши клиенты), ежегодно платим миллионы долларов Oracle, Microsoft, IBM, SAP за их отличные СУБД, только за то, что они игнорируют 90% функций своих баз данных и выполняют немного CRUD и немного ACID с ORM, такими как Hibernate. Мы забыли о том, почему эти СУБД были такими дорогими. Мы не обращали внимания на различные улучшения стандартов SQL, включая SQL: 1999 , SQL: 2003 , SQL: 2008 и недавний SQL: 2011 , которые в основном не поддерживаются JPA .
Если бы только мы, Java-разработчики, знали, как легко и весело можно заменить тысячи строк ошибочного кода Java пятью строками SQL. Не верь этому? Проверь это:
Продвижение SQL, язык
Вместо того, чтобы просто продвигать jOOQ, мы начали помогать разработчикам Java ценить реальный SQL, независимо от используемого ими шаблона доступа. Потому что истинный SQL можно оценить через любой из этих API:
- JDBC
- JOOQ (да, шокер, я знаю)
- Spring JDBC расширения
- MyBatis
- Apache DbUtils
- Groovy SQL
Как можно использовать вышеупомянутые API в Java 8, можно увидеть здесь.
И поверьте нам, большинство разработчиков были удивлены тем, что было возможно в SQL, когда они увидели наш NoSQL? Нет, SQL! говорить:
Расчет промежуточного итога
Итак, давайте углубимся в суть разговора и вычислим промежуточную сумму с помощью SQL. Что такое промежуточный итог? Это просто. Представьте, что в вашей базе данных есть данные транзакций банковского счета:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT ||------|------------|--------|| 9997 | 2014-03-18 | 99.17 || 9981 | 2014-03-16 | 71.44 || 9979 | 2014-03-16 | -94.60 || 9977 | 2014-03-16 | -6.96 || 9971 | 2014-03-15 | -65.95 | |
Вы сразу заметите, что баланс на транзакцию аккаунта отсутствует. Да, мы хотим рассчитать этот баланс как таковой:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | BALANCE ||------|------------|--------|----------|| 9997 | 2014-03-18 | 99.17 | 19985.81 || 9981 | 2014-03-16 | 71.44 | 19886.64 || 9979 | 2014-03-16 | -94.60 | 19815.20 || 9977 | 2014-03-16 | -6.96 | 19909.80 || 9971 | 2014-03-15 | -65.95 | 19916.76 | |
Если мы предполагаем, что нам известен текущий баланс на банковском счете, мы можем использовать значение AMOUNT каждой транзакции и вычесть его из этого текущего баланса. В качестве альтернативы мы могли бы принять начальный баланс, равный нулю, и сложить все значения AMOUNT до сегодняшнего дня. Это показано здесь:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | BALANCE ||------|------------|--------|----------|| 9997 | 2014-03-18 | 99.17 | 19985.81 || 9981 | 2014-03-16 | +71.44 |=19886.64 | n| 9979 | 2014-03-16 | -94.60 |+19815.20 | n + 1| 9977 | 2014-03-16 | -6.96 | 19909.80 || 9971 | 2014-03-15 | -65.95 | 19916.76 | |
Баланс каждой транзакции можно рассчитать по одной из следующих формул:
|
1
2
|
BALANCE(ROWn) = BALANCE(ROWn+1) + AMOUNT(ROWn)BALANCE(ROWn+1) = BALANCE(ROWn) – AMOUNT(ROWn) |
Итак, это промежуточный итог. Легко, правда?
Но как мы можем сделать это в SQL?
Большинство из нас, вероятно, вытащили бы небольшую Java-программу из своих рукавов, сохраняя все объемы в памяти, записывая модульные тесты, исправляя всевозможные ошибки (в конце концов, мы не математики), борясь с BigDecimals и т. Д. Немногие из нас, вероятно, придется пройти через то же самое в PL / SQL или T-SQL или на любом другом процедурном языке, который у вас есть, и, возможно, обновить каждый баланс непосредственно в таблице при вставке / обновлении новых транзакций.
Но, как вы уже догадались, решение, которое мы ищем здесь, — это решение на SQL. Пожалуйста, потерпите нас, пока мы рассмотрим примеры. Они становятся все лучше и лучше. И если вы хотите поиграть с примерами, скачайте Oracle XE и скрипт running-totals.sql и начните работать!
То, что мы узнали из колледжа / SQL-92 , вероятно, будет включать в себя …
Использование вложенного SELECT
Давайте предположим, что у нас есть представление типа v_transactions , которое уже соединяет таблицу счетов с таблицей транзакций счета для доступа к current_balance . Вот как мы могли бы написать этот запрос:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
SELECT t1.*, t1.current_balance - ( SELECT NVL(SUM(amount), 0) FROM v_transactions t2 WHERE t2.account_id = t1.account_id AND (t2.value_date, t2.id) > (t1.value_date, t1.id) ) AS balanceFROM v_transactions t1WHERE t1.account_id = 1ORDER BY t1.value_date DESC, t1.id DESC |
Обратите внимание, как вложенный SELECT использует предикаты выражения значения строки для выражения критериев фильтрации. Если ваша база данных не поддерживает стандартные предикаты выражения значения строки SQL ( и вы не используете jOOQ для их эмуляции ), вы можете самостоятельно выделить их для формирования эквивалентного запроса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
SELECT t1.*, t1.current_balance - ( SELECT NVL(SUM(amount), 0) FROM v_transactions t2 WHERE t2.account_id = t1.account_id AND ((t2.value_date > t1.value_date) OR (t2.value_date = t1.value_date AND t2.id > t1.id)) ) AS balanceFROM v_transactions t1WHERE t1.account_id = 1ORDER BY t1.value_date DESC, t1.id DESC |
Таким образом, по сути, для любой данной транзакции по счету ваш вложенный SELECT просто выбирает сумму всех значений AMOUNT для транзакций по счету, которые являются более недавними, чем текущая прогнозируемая транзакция по счету.
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | BALANCE ||------|------------|---------|----------|| 9997 | 2014-03-18 | -(99.17)|+19985.81 || 9981 | 2014-03-16 | -(71.44)| 19886.64 || 9979 | 2014-03-16 |-(-94.60)| 19815.20 || 9977 | 2014-03-16 | -6.96 |=19909.80 || 9971 | 2014-03-15 | -65.95 | 19916.76 | |
Это работает?
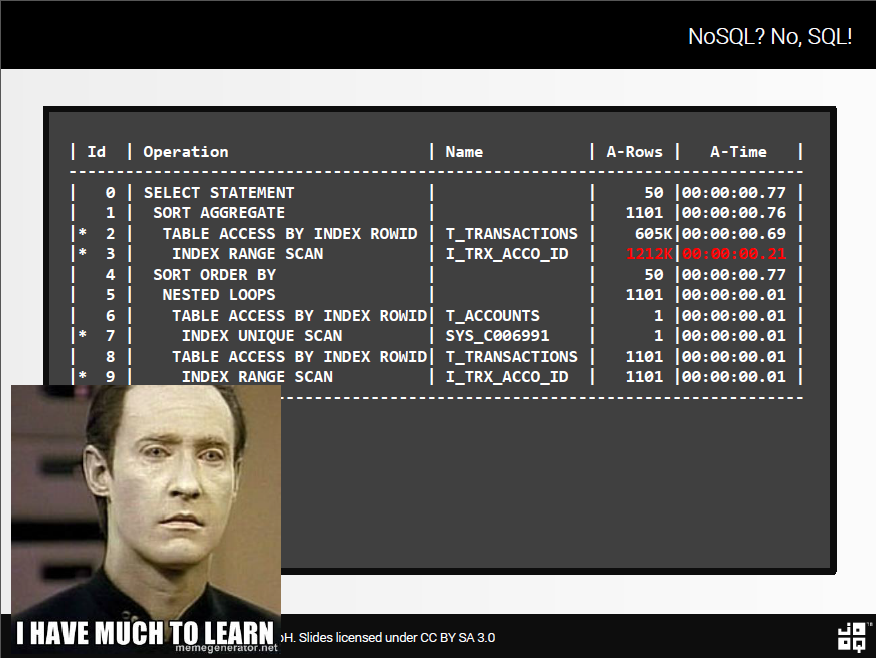
План выполнения для вложенного SELECT
Нет. Как видите, для относительно простого примера набора данных (только 1101 запись отфильтрована по account_id = 1 в строке 9), существует INDEX RANGE SCAN, обеспечивающий колоссальное количество 1212K строк в памяти. Похоже, у нас сложность O(n 2 ) . Т.е. применяется очень наивный алгоритм.
(и не думайте, что 770мс быстро для этого тривиального запроса!)
Хотя вы, вероятно, могли бы немного настроить этот запрос, мы все же должны чувствовать, что Oracle должен иметь возможность разработать алгоритм O(n) для этой простой задачи.
Использование рекурсивного SQL
Никто не любит писать рекурсивный SQL. Ни один. Никто. Позвольте мне убедить вас.
Для простоты мы предполагаем, что у нас также есть столбец TRANSACTION_NR перечисляющий транзакции в порядке их сортировки, который можно использовать для упрощения рекурсии:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | TRANSACTION_NR ||------|------------|--------|----------------|| 9997 | 2014-03-18 | 99.17 | 1 || 9981 | 2014-03-16 | 71.44 | 2 || 9979 | 2014-03-16 | -94.60 | 3 || 9977 | 2014-03-16 | -6.96 | 4 || 9971 | 2014-03-15 | -65.95 | 5 | |
Готовы? Проверьте этот великолепный кусок SQL!
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
WITH ordered_with_balance ( account_id, value_date, amount, balance, transaction_number)AS ( SELECT t1.account_id, t1.value_date, t1.amount, t1.current_balance, t1.transaction_number FROM v_transactions_by_time t1 WHERE t1.transaction_number = 1 UNION ALL SELECT t1.account_id, t1.value_date, t1.amount, t2.balance - t2.amount, t1.transaction_number FROM ordered_with_balance t2 JOIN v_transactions_by_time t1 ON t1.transaction_number = t2.transaction_number + 1 AND t1.account_id = t2.account_id)SELECT *FROM ordered_with_balanceWHERE account_id= 1ORDER BY transaction_number ASC |
Ах … Как читать эту красавицу?
По сути, мы присоединяемся к представлению (общему табличному выражению), которое собираемся объявить:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
WITH ordered_with_balance ( account_id, value_date, amount, balance, transaction_number)AS ( SELECT t1.account_id, t1.value_date, t1.amount, t1.current_balance, t1.transaction_number FROM v_transactions_by_time t1 WHERE t1.transaction_number = 1 UNION ALL SELECT t1.account_id, t1.value_date, t1.amount, t2.balance - t2.amount, t1.transaction_number FROM ordered_with_balance t2 JOIN v_transactions_by_time t1 ON t1.transaction_number = t2.transaction_number + 1 AND t1.account_id = t2.account_id)SELECT *FROM ordered_with_balanceWHERE account_id= 1ORDER BY transaction_number ASC |
В первом подвыборе выражения UNION ALL мы проецируем current_balance счета, только для первого transaction_number .
Во второй части выражения UNION ALL мы проецируем разницу между остатком previous транзакции счета и AMOUNT текущей транзакции счета.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
WITH ordered_with_balance ( account_id, value_date, amount, balance, transaction_number)AS ( SELECT t1.account_id, t1.value_date, t1.amount, t1.current_balance, t1.transaction_number FROM v_transactions_by_time t1 WHERE t1.transaction_number = 1 UNION ALL SELECT t1.account_id, t1.value_date, t1.amount, t2.balance - t2.amount, t1.transaction_number FROM ordered_with_balance t2 JOIN v_transactions_by_time t1 ON t1.transaction_number = t2.transaction_number + 1 AND t1.account_id = t2.account_id)SELECT *FROM ordered_with_balanceWHERE account_id= 1ORDER BY transaction_number ASC |
И поскольку мы возвращаемся к общему табличному выражению ordered_with_balance , это будет продолжаться до тех пор, пока мы не достигнем «последней» транзакции.
Теперь давайте сделаем обоснованное предположение, хорошо ли это работает …
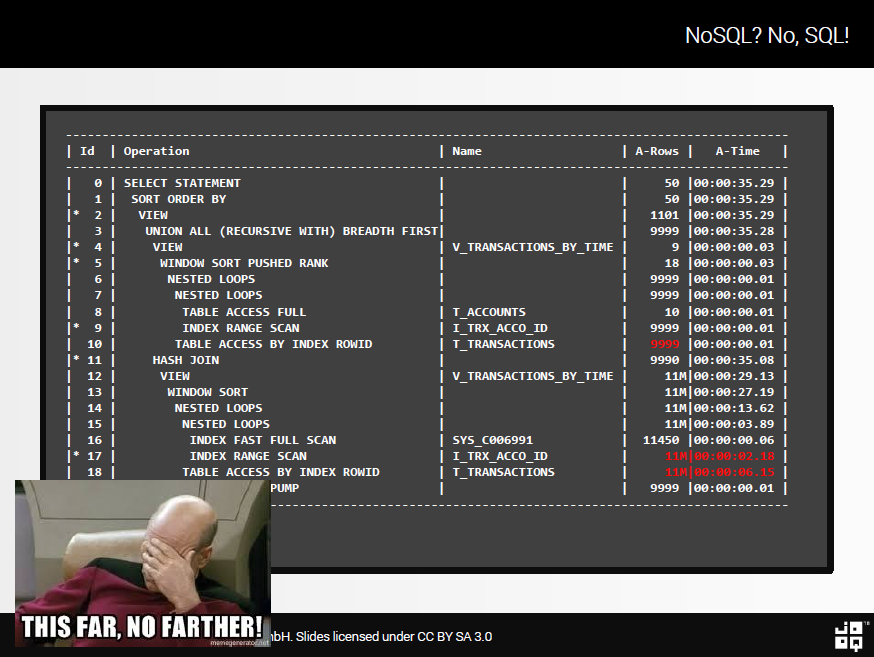
План выполнения для рекурсивного SQL
Что ж. Это не так. Мы получаем еще больше строк в памяти, а именно 11M строк, что должно быть не более 1101 . Части этого плана связаны с тем, что служебный столбец TRANSACTION_NUMBER является еще одним вычисляемым столбцом, который не может быть оптимизирован Oracle. Но суть здесь в том, что правильно понять это уже очень сложно, еще быстрее — быстро .
Использование оконных функций
Итак, мы достаточно пострадали. Давайте послушаем хорошие новости.
Есть SQL перед оконными функциями, и есть SQL после оконных функций
— Дмитрий Фонтейн в этом великом посте
Лучшее решение для этой проблемы это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
SELECT t.*, t.current_balance - NVL( SUM(t.amount) OVER ( PARTITION BY t.account_id ORDER BY t.value_date DESC, t.id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING ), 0) AS balanceFROM v_transactions tWHERE t.account_id = 1ORDER BY t.value_date DESC, t.id DESC |
По сути, мы делаем то же самое, что и с вложенным SELECT. Мы вычитаем SUM() из всех значений AMOUNT «над» подмножеством строк:
- в том же разделе
PARTITIONчто и текущая строка (т.е. имеет тот жеaccount_id) - заказывается по тем же критериям заказа, что и транзакции по счету (из внешнего запроса)
- позиционируется строго перед текущей строкой в смысле приведенного выше порядка
Или опять визуально:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | BALANCE ||------|------------|---------|----------|| 9997 | 2014-03-18 | -(99.17)|+19985.81 || 9981 | 2014-03-16 | -(71.44)| 19886.64 || 9979 | 2014-03-16 |-(-94.60)| 19815.20 || 9977 | 2014-03-16 | -6.96 |=19909.80 || 9971 | 2014-03-15 | -65.95 | 19916.76 | |
И теперь, это выполняет?
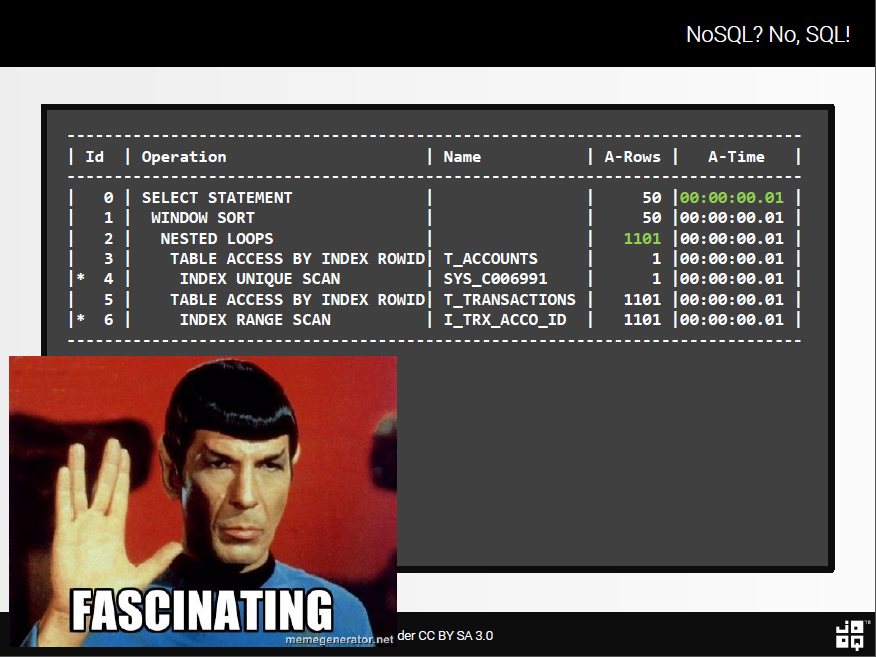
План выполнения оконных функций
Аллилуйя!
Это не могло быть намного быстрее! Оконные функции, вероятно, самая недооцененная функция SQL .
Использование предложения Oracle MODEL
Теперь, это больше особенное удовольствие для тех ботаников SQL среди вас, кто хочет разозлить ваших коллег-разработчиков с помощью жуткого, странного SQL. Предложение MODEL (доступно только в Oracle).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
SELECT account_id, value_date, amount, balanceFROM ( SELECT id, account_id, value_date, amount, current_balance AS balance FROM v_transactions) tWHERE account_id = 1MODEL PARTITION BY (account_id) DIMENSION BY ( ROW_NUMBER() OVER ( ORDER BY value_date DESC, id DESC ) AS rn ) MEASURES (value_date, amount, balance) RULES ( balance[rn > 1] = balance[cv(rn) - 1] - amount [cv(rn) - 1] )ORDER BY rn ASC |
Теперь, как читать этого зверя? Мы берем пример данных и преобразуем их в:
-
PARTITIONпо обычным критериям - быть
DIMENSIONпо порядку сортировки, то есть по номеру строки транзакции - быть
MEASURE, т. е. предоставлять рассчитанные значения для даты, суммы, баланса (где дата и сумма остаются нетронутыми, исходные данные) - рассчитываться в соответствии с
RULES, в которых баланс каждой транзакции (кроме первой) определяется как баланс предыдущей транзакции за вычетом суммы предыдущей транзакции.
Все еще слишком абстрактно? Я знаю. Но подумайте об этом так:
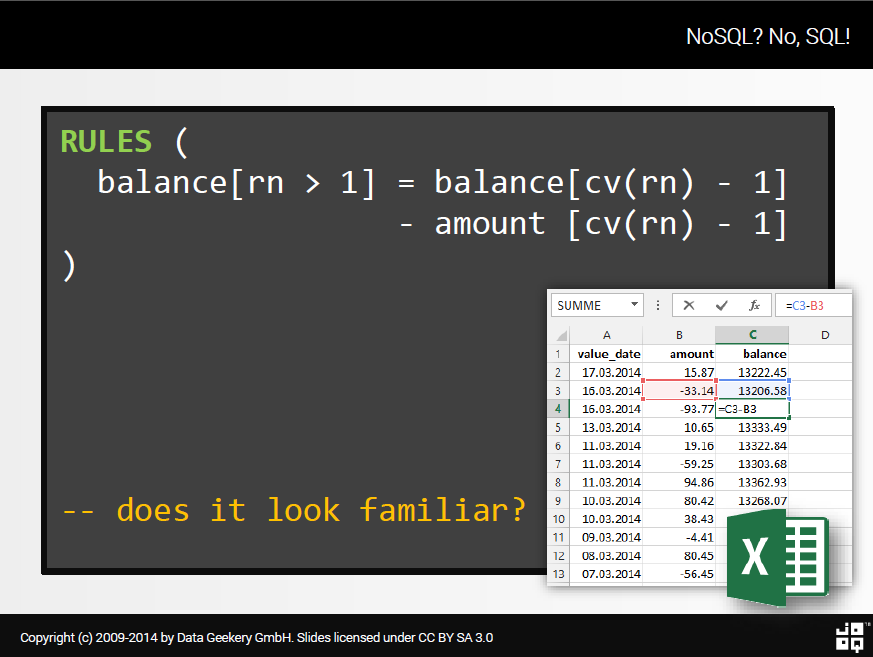
Это вам что-то напоминает?
MS Excel! Каждый раз, когда у вас возникает проблема, которую ваш менеджер проекта считает арахисом, которую нужно решить с помощью своих модных электронных таблиц MS Excel, предложение MODEL станет вашим другом!
И это работает?
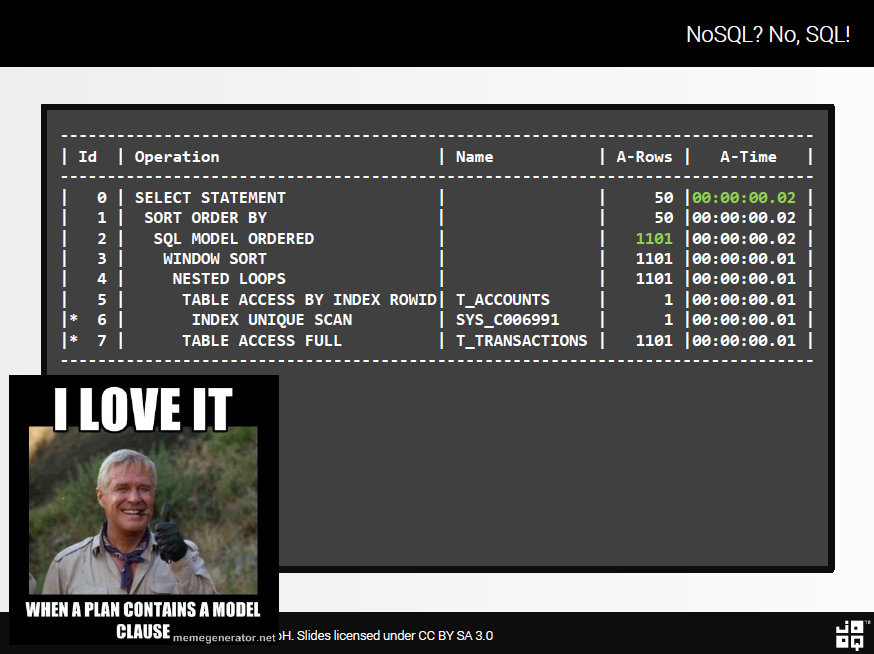
План выполнения предложения MODEL
… В значительной степени (хотя вышесказанное не следует путать с реальным тестом).
Если вы не видели достаточно, посмотрите еще один отличный пример использования предложения MODEL здесь . И для всех деталей, подумайте о том, чтобы прочитать официальный документ Oracle о предложении MODEL
Сделай это сам
Вам понравились приведенные выше примеры? Не беспокойся Когда вы видели эти вещи в первый раз, они могут быть довольно запутанными. Но по сути, они действительно не так сложны. И как только вы получите эти функции в своей цепочке инструментов, вы будете бесконечно более продуктивными, чем если бы вам пришлось выписывать все эти алгоритмы на императивном языке программирования.
Если вы хотите поиграть с примерами, скачайте Oracle XE и скрипт running-totals.sql и начните работать!
Вывод
В Data Geekery мы всегда говорим:
SQL — это устройство, тайна которого превосходит только его мощь
И иногда мы также цитируем Уинстона Черчилля, который сказал что-то вроде:
SQL является худшей формой запросов к базе данных, за исключением всех других форм
Действительно, как показало предложение MODEL, SQL может стать очень экстремальным. Но как только вы узнаете хитрости и выражения (и, что наиболее важно, оконные функции ), вы будете невероятно более продуктивны с SQL, чем со многими другими технологиями, если задача — это операция массовых вычислений над простым или сложным набором данных. И ваш запрос часто быстрее, чем если бы вы его написали от руки, по крайней мере, когда вы используете достойную базу данных.
Итак, давайте применим SQL в наших программах!
Вы заинтересованы в размещении нашего NoSQL? Нет, SQL! поговорить на местном кувшине или в качестве внутренней презентации? Свяжитесь с нами , мы более чем рады помочь вам улучшить ваши навыки SQL!
| Ссылка: | NoSQL? Нет, SQL! — Как рассчитать промежуточные суммы от нашего партнера по JCG Лукаса Эдера из блога JAVA, SQL и JOOQ . |