Это руководство по созданию редактора на основе браузера для нового языка, который мы собираемся определить.
Мы собираемся использовать два компонента:
- Монако : это отличный браузерный редактор (или веб-редактор: как вы предпочитаете его называть)
- ANTLR : это генератор парсеров, который мы любим использовать для создания всевозможных парсеров
Мы создадим редактор для простого языка для выполнения расчетов. Результат будет таким:
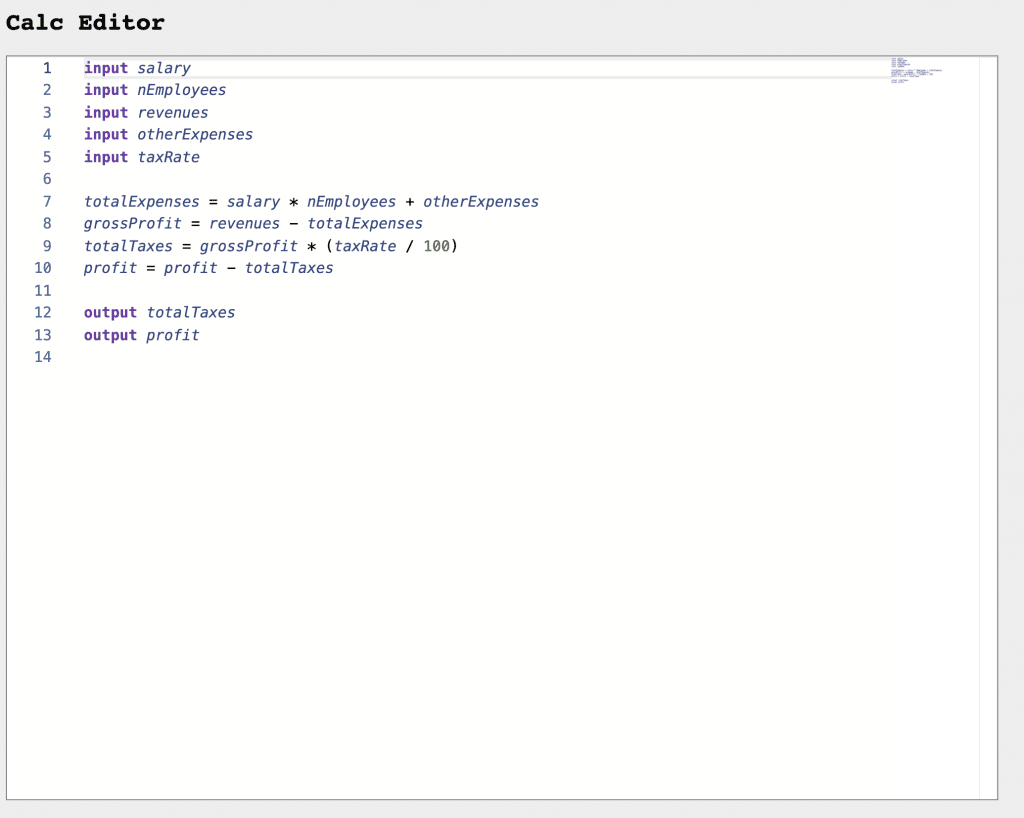
Весь код доступен онлайн: calc-monaco-editor .
Некоторое время назад мы написали статью о создании простого веб-редактора с использованием ANTLR в браузере . Мы продолжаем эту работу на следующем этапе, адаптируя его для использования NPM и WebPack, чтобы упростить создание приложения.
Зачем использовать Монако?
Монако является производным от кода Visual Studio (VSCode, для его друзей). VSCode — это легкий редактор, который привлекает все больше и больше пользователей. Монако в основном VSCode перепакован для запуска в браузере. Это отличный редактор, с множеством интересных функций, он в хорошем состоянии и выпущен под лицензией с открытым исходным кодом (The MIT License).
Зачем использовать ANTLR?
ANTLR — это инструмент, который с помощью грамматики может генерировать соответствующий синтаксический анализатор на нескольких целевых языках. Среди прочего поддерживаются Java, C #, Python и Javascript. Еще одно преимущество заключается в том, что для ANTLR доступно несколько грамматик. Поэтому, если вы научитесь сочетать Монако и ANTLR, вы легко сможете получить поддержку в Монако для любого языка, для которого вы можете найти грамматику ANTLR. У нас есть обширный материал по ANTLR, от нашего бесплатного мега-учебника ANTLR до видеокурса по изучению ANTLR Like Professional .
Наш образец проекта
Давайте пересмотрим, как мы собираемся организовать наш проект:
- В этом проекте мы собираемся использовать NPM для загрузки зависимостей, таких как среда выполнения ANTLR
- Мы будем использовать gradle для вызова инструмента ANTLR, который сгенерирует анализатор Javascript для нашего языка из определения грамматики.
- Мы собираемся написать наш код на TypeScript. Наш код свяжет ANTLR в Монако
- Мы упакуем Javascript в один файл, используя WebPack
- Мы напишем модульные тесты, используя мокко
- Мы напишем более простой сервер с использованием Kotlin и платформы Ktor. Это может быть заменено любым сервером, просто я предпочитаю работать с Kotlin всякий раз, когда у меня есть возможность.
Наш простой язык расчетов
Наш язык будет очень простым. Это просто позволит выполнять очень простые вычисления. Это намеренно, но тот же подход можно использовать с очень сложными языками.
Мы сможем написать такой код:
|
1
2
3
4
|
input ab = a * 2c = (a - b) / 3output c |
На практике наш язык позволит определить:
- входные данные: это значения, которые будут получены калькулятором
- расчеты: новые значения могут быть рассчитаны и сохранены в переменных. Они могут быть рассчитаны из входных данных или других переменных
- выходные данные: мы идентифицируем переменные, которые мы хотим вернуть в результате наших расчетов
Написание парсера
Прежде всего мы начнем с определения грамматик лексера и синтаксического анализатора.
Мы создадим каталог src/main/antlr и внутри этого каталога мы определим файлы CalcLexer.g4 и CalcParser.g4 .
Мы не будем объяснять с нуля, как писать грамматики ANTLR. Если вы не знакомы с ANTLR, то учебник ANTLR Mega Tutorial — хорошее место для начала. Однако у нас есть несколько комментариев, относящихся к этому случаю использования, в частности к лексеру.
- Мы не должны пропускать пробелы, но мы должны вместо этого вставить эти токены в определенный канал, потому что все токены будут релевантны для подсветки синтаксиса.
- Кроме того, лексер должен приписывать каждый отдельный символ токену, поэтому мы добавляем специальное правило в конце лексера, чтобы перехватить любой символ, который не был захвачен другими правилами лексера.
- Для простоты мы должны избегать использования токенов, состоящих из нескольких строк, или использования лексических режимов, поскольку они затруднят интеграцию с Монако для выделения синтаксиса. Это проблемы, которые мы можем решить (и мы решаем для проектов клиентов), но мы не хотим решать их в этом учебном пособии, поскольку они затруднят понимание основ
Это наша грамматика CalcLexer.g4 ( CalcLexer.g4 ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
lexer grammar CalcLexer;channels { WS_CHANNEL }WS: [ \t]+ -> channel(WS_CHANNEL);NL: ('\r\n' | '\r' | '\n') -> channel(WS_CHANNEL);INPUT_KW : 'input' ;OUTPUT_KW : 'output' ;NUMBER_LIT : ('0'|[1-9][0-9]*)('.'[0-9]+)?;ID: [a-zA-Z][a-zA-Z0-9_]* ;LPAREN : '(' ;RPAREN : ')' ;EQUAL : '=' ;MINUS : '-' ;PLUS : '+' ;MUL : '*' ;DIV : '/' ;UNRECOGNIZED : . ; |
И это наша грамматика синтаксического анализатора ( CalcParser.g4 ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
parser grammar CalcParser;options { tokenVocab=CalcLexer; }compilationUnit: (inputs+=input)* (calcs+=calc)* (outputs+=output)* EOF ;input: INPUT_KW ID ;output: OUTPUT_KW ID ;calc: target=ID EQUAL value=expression ;expression: NUMBER_LIT | ID | LPAREN expression RPAREN | expression operator=(MUL|DIV) expression | expression operator=(MINUS|PLUS) expression | MINUS expression ; |
Теперь, когда у нас есть грамматики, нам нужно сгенерировать из них лексерный анализатор Javascript. Для этого нам понадобится инструмент ANTLR. Самым простым подходом для меня является использование gradle для загрузки ANTLR и зависимостей, а также определение задач в gradle для вызова ANTLR.
Мы установим упаковщик Gradle, выполнив:
gradle wrapper --gradle-version = 5.6.1 --distribution-type = bin
Сценарий build.gradle будет выглядеть так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
apply plugin: 'java'repositories { jcenter()}dependencies { runtime 'org.antlr:antlr4:4.7.2'}task generateLexer(type:JavaExec) { def lexerName = "CalcLexer" inputs.file("$ANTLR_SRC/${lexerName}.g4") outputs.file("$GEN_JS_SRC/${lexerName}.js") outputs.file("$GEN_JS_SRC/${lexerName}.interp") outputs.file("$GEN_JS_SRC/${lexerName}.tokens") main = 'org.antlr.v4.Tool' classpath = sourceSets.main.runtimeClasspath args = ['-Dlanguage=JavaScript', "${lexerName}.g4", '-o', '../../main-generated/javascript'] workingDir = ANTLR_SRC }task generateParser(type:JavaExec) { dependsOn generateLexer def lexerName = "CalcLexer" def parserName = "CalcParser" inputs.file("$ANTLR_SRC/${parserName}.g4") inputs.file("$GEN_JS_SRC/${lexerName}.tokens") outputs.file("$GEN_JS_SRC/${parserName}.js") outputs.file("$GEN_JS_SRC/${parserName}.interp") outputs.file("$GEN_JS_SRC/${parserName}.tokens") main = 'org.antlr.v4.Tool' classpath = sourceSets.main.runtimeClasspath args = ['-Dlanguage=JavaScript', "${parserName}.g4", '-no-listener', '-no-visitor', '-o', '../../main-generated/javascript'] workingDir = ANTLR_SRC} |
Он использует некоторые свойства, определенные в файле gradle.properties :
ANTLR_SRC = src / main / antlr GEN_JS_SRC = src / основной сгенерированный / javascript
На практике это будет использовать грамматики в src/main/antlr для генерации src/main/antlr и анализатора в src/main-generated/javascript .
Мы можем запустить ANTLR:
./gradlew generateParser
Это также сгенерирует лексер, поскольку задача generateParser задачи зависит от задачи generateLexer .
После выполнения этой команды у вас должны быть эти файлы в src/main-generated/javascript :
- CalcLexer.interp
- CalcLexer.js
- CalcLexer.tokens
- CalcParser.interp
- CalcParser.js
- CalcParser.tokens
Использование NPM для управления зависимостями
Для запуска нашего лексера и парсера нам понадобятся две вещи: сгенерированный код Javascript и среда выполнения ANTLR. Чтобы получить время выполнения ANTLR, мы будем использовать NPM. NPM также будет использоваться для загрузки Монако. Поэтому мы не собираемся запускать Node.JS для нашего проекта, мы просто будем использовать его для получения зависимостей и запуска тестов.
Мы предполагаем, что вы установили npm в вашей системе. Если вы не, ну, пора нажать Google и выяснить, как установить его.
После того, как мы установили npm, нам нужно предоставить ему конфигурацию проекта, заполнив наш файл package.json :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
{ "name": "calc-monaco-editor", "version": "0.0.1", "author": "Strumenta", "license": "Apache-2.0", "dependencies": { "antlr4": "^4.7.2", "webpack": "^4.39.2", "webpack-cli": "^3.3.7" }, "devDependencies": { "mocha": "^6.2.0", "monaco-editor": "^0.17.1" }, "scripts": { "test": "mocha" }} |
На данный момент мы можем установить все, что нам нужно, просто запустив npm install .
Теперь вы должны были получить среду выполнения ANTLR 4 в node_modules вместе с несколькими другими вещами. Да, там много всего. Да, вы не хотели бы загружать эти вещи вручную, так что спасибо npm!
Компиляция TypeScript
Давайте теперь напишем некоторый код, используя наш сгенерированный лексер и парсер.
Мы создадим каталог src/main/typescript и начнем писать файл с именем ParserFacade.ts . В этом файле мы напишем некоторый код для вызова и генерирования лексера и парсера и получим список токенов. Позже мы также рассмотрим получение дерева разбора.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
/// <reference path="../../../node_modules/monaco-editor/monaco.d.ts" />import {InputStream, Token} from '../../../node_modules/antlr4/index.js'import {CalcLexer} from "../../main-generated/javascript/CalcLexer.js"function createLexer(input: String) { const chars = new InputStream(input); const lexer = new CalcLexer(chars); lexer.strictMode = false; return lexer;}export function getTokens(input: String) : Token[] { return createLexer(input).getAllTokens()} |
Затем нам нужно будет сгенерировать код Javascript из Typescript. Мы сгенерируем его в src/main-generated/javascript с tsc инструмента tsc . Для его настройки нам потребуется создать файл tsconfig.json .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
{ "compilerOptions": { "module": "CommonJS", "target": "es5", "sourceMap": true, "outDir": "src/main-generated/javascript" }, "exclude": [ "node_modules" ], "include" : [ "src/main/typescript" ]} |
На данный момент мы можем просто запустить:
TSC
В каталоге src / main-generate / javascript мы также должны увидеть эти файлы:
- ParserFacade.js
- ParserFacade.js.map
Как мы гарантируем, что наш код работает? С юнит-тестами, конечно!
Написание юнит-тестов
Мы настроим mocha, создав test/mocha.opts с таким содержанием:
SRC / тест / JavaScript --recursive
Теперь мы готовы написать наши тесты. В src/test/javascript мы создадим lexingTest.js :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
let assert = require('assert');let parserFacade = require('../../main-generated/javascript/ParserFacade.js');let CalcLexer = require('../../main-generated/javascript/CalcLexer.js').CalcLexer;function checkToken(tokens, index, typeName, column, text) { it('should have ' + typeName + ' in position ' + index, function () { assert.equal(tokens[index].type, CalcLexer[typeName]); assert.equal(tokens[index].column, column); assert.equal(tokens[index].text, text); });}describe('Basic lexing without spaces', function () { let tokens = parserFacade.getTokens("a=5"); it('should return 3 tokens', function() { assert.equal(tokens.length, 3); }); checkToken(tokens, 0, 'ID', 0, "a"); checkToken(tokens, 1, 'EQUAL', 1, "="); checkToken(tokens, 2, 'NUMBER_LIT', 2, "5");}); |
Мы можем запустить тесты с:
tsc && npm test
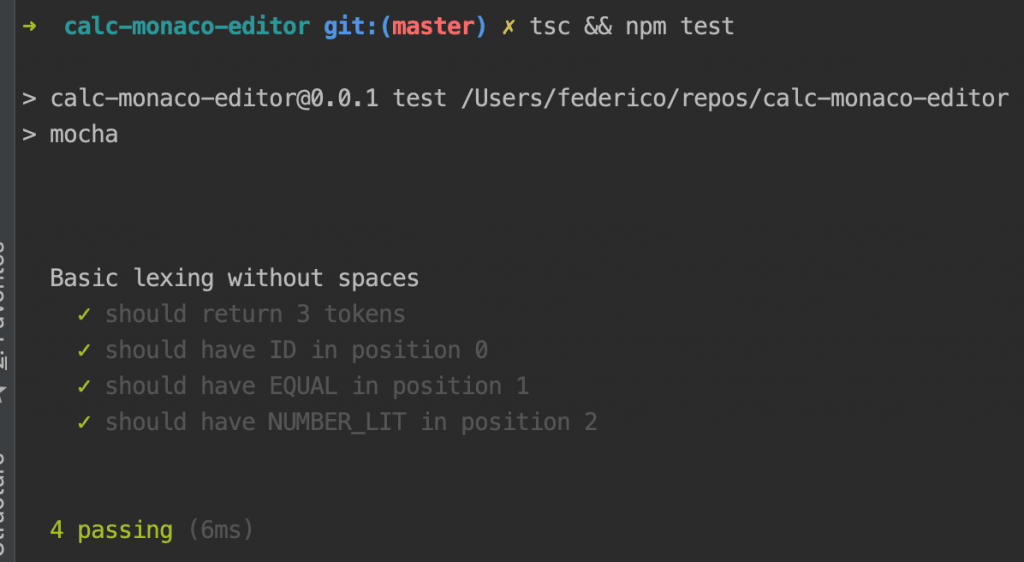
Хорошо, наш проект начинает куда-то идти, и у нас есть возможность проверить работоспособность нашего кода. Жизнь хороша.
Теперь, когда мы создали эти основы, мы можем написать больше кода в ParserFacade .
Давайте завершить ParserFacade
Теперь мы собираемся завершить ParserFacade. В частности, мы представим простую функцию для получения строкового представления дерева разбора. Это будет полезно для тестирования нашего парсера.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
/// <reference path="../../../node_modules/monaco-editor/monaco.d.ts" />import {CommonTokenStream, InputStream, Token, error} from '../../../node_modules/antlr4/index.js'import {CalcLexer} from "../../main-generated/javascript/CalcLexer.js"import {CalcParser} from "../../main-generated/javascript/CalcParser.js"class MyErrorListener extends error.ErrorListener { syntaxError(recognizer, offendingSymbol, line, column, msg, e) { console.log("ERROR " + msg); }}function createLexer(input: String) { const chars = new InputStream(input); const lexer = new CalcLexer(chars); lexer.strictMode = false; return lexer;}export function getTokens(input: String) : Token[] { return createLexer(input).getAllTokens()}function createParser(input) { const lexer = createLexer(input); return createParserFromLexer(lexer);}function createParserFromLexer(lexer) { const tokens = new CommonTokenStream(lexer); return new CalcParser(tokens);}function parseTree(input) { const parser = createParser(input); return parser.compilationUnit();}export function parseTreeStr(input) { const lexer = createLexer(input); lexer.removeErrorListeners(); lexer.addErrorListener(new MyErrorListener()); const parser = createParserFromLexer(lexer); parser.removeErrorListeners(); parser.addErrorListener(new MyErrorListener()); const tree = parser.compilationUnit(); return tree.toStringTree(parser.ruleNames);} |
Давайте теперь посмотрим, как мы можем проверить наш парсер. Мы создаем parsingTest.js в src/test/javascript :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
let assert = require('assert');let parserFacade = require('../../main-generated/javascript/ParserFacade.js');function checkToken(tokens, index, typeName, column, text) { it('should have ' + typeName + ' in position ' + index, function () { assert.equal(tokens[index].type, CalcLexer[typeName]); assert.equal(tokens[index].column, column); assert.equal(tokens[index].text, text); });}describe('Basic parsing of empty file', function () { assert.equal(parserFacade.parseTreeStr(""), "(compilationUnit <EOF>)")});describe('Basic parsing of single input definition', function () { assert.equal(parserFacade.parseTreeStr("input a"), "(compilationUnit (input input a) <EOF>)")});describe('Basic parsing of single output definition', function () { assert.equal(parserFacade.parseTreeStr("output a"), "(compilationUnit (output output a) <EOF>)")});describe('Basic parsing of single calculation', function () { assert.equal(parserFacade.parseTreeStr("a = b + 1"), "(compilationUnit (calc a = (expression (expression b) + (expression 1))) <EOF>)")});describe('Basic parsing of simple script', function () { assert.equal(parserFacade.parseTreeStr("input i\no = i + 1\noutput o"), "(compilationUnit (input input i) (calc o = (expression (expression i) + (expression 1))) (output output o) <EOF>)")}); |
И ура! Наши тесты проходят.
Хорошо, у нас есть лексер и парсер. Оба, кажется, работают достаточно прилично.
Теперь вопрос в том, как мы можем использовать этот материал в сочетании с Монако? Давай выясним.
Интегрировать в Монако
Теперь мы создадим простую HTML-страницу, на которой будет размещен наш редактор Monaco:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<!DOCTYPE html><html><head> <title>Calc Editor</title> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta http-equiv="Content-Type" content="text/html;charset=utf-8" ></head><body><h2>Calc Editor</h2><div id="container" style="width:800px;height:600px;border:1px solid grey"></div><script src="node_modules/monaco-editor/min/vs/loader.js"></script><script src="js/main.js"></script><script> require.config({ paths: { 'vs': 'node_modules/monaco-editor/min/vs' }}); require(['vs/editor/editor.main'], function() { monaco.languages.register({ id: 'calc' }); let editor = monaco.editor.create(document.getElementById('container'), { value: [ 'input a', 'b = a * 2', 'c = (a - b) / 3', 'output c', '' ].join('\n'), language: 'calc' }); });</script></body> |
Эта страница должна будет:
- загрузить код Монако
- загрузите код, который мы напишем для интеграции ANTLR в Монако
Теперь мы хотим упаковать код, который мы запишем в один файл Javascript, чтобы быстрее и проще загружать код Javascript в браузер. Для этого мы будем использовать веб-пакет: он изучит входной файл, найдет все зависимости и упакует их в один файл.
Также webpack хочет иметь собственную конфигурацию в файле с именем webpack.config.js :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
module.exports = { entry: './src/main/javascript/index.js', output: { filename: 'main.js', }, module: { rules: [{ test: /\.tsx?$/, use: 'ts-loader', exclude: /node_modules/ }] }, resolve: { modules: ['node_modules'], extensions: [ '.tsx', '.ts', '.js' ] }, mode: 'production', node: { fs: 'empty', global: true, crypto: 'empty', tls: 'empty', net: 'empty', process: true, module: false, clearImmediate: false, setImmediate: false }} |
Нам также нужно определить точку входа файла Javascript. Мы создадим его в src/main/javascript/index.js . А пока мы оставим это пустым.
Теперь, запустив webpack, мы можем сгенерировать файл dist/main.js который загружаем на страницу HTML.
Обслуживание файлов: наш простой сервер написан на Kotlin
На данный момент мы собираемся настроить очень простой веб-сервер с использованием Kotlin . Эта часть не так важна, и вы можете выбрать другой подход к серверу ваших файлов.
Мы создадим подкаталог с именем server с помощью этого файла build.gradle :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
buildscript { ext.kotlin_version = '1.3.41' repositories { jcenter() } dependencies { classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version" classpath "org.jetbrains.kotlin:kotlin-serialization:$kotlin_version" }}plugins { id 'org.jetbrains.kotlin.jvm' version '1.3.41'}apply plugin: 'kotlin'apply plugin: 'kotlinx-serialization'repositories { mavenCentral() jcenter()}ext.ktor_version = "1.2.3"dependencies { implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk8" compile "io.ktor:ktor-server-core:$ktor_version" compile "io.ktor:ktor-server-netty:$ktor_version" implementation "io.ktor:ktor-websockets:$ktor_version" implementation 'com.google.code.gson:gson:2.8.5' implementation 'org.jetbrains.kotlin:kotlin-test' implementation 'org.jetbrains.kotlin:kotlin-test-junit' compile "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version" compile "org.jetbrains.kotlinx:kotlinx-serialization-runtime:0.11.1"}compileKotlin { kotlinOptions { jvmTarget = "1.8" }}compileTestKotlin { kotlinOptions { jvmTarget = "1.8" }}task runServer(type:JavaExec) { main = 'com.strumenta.simpleserver.MainKt' classpath = sourceSets.main.runtimeClasspath args = ['8888']} |
Этот скрипт задает зависимости и добавляет задачу для запуска сервера из командной строки.
Код сервера довольно прост:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package com.strumenta.simpleserverimport io.ktor.application.callimport io.ktor.http.ContentTypeimport io.ktor.http.content.filesimport io.ktor.http.content.staticimport io.ktor.response.respondTextimport io.ktor.routing.getimport io.ktor.routing.routingimport io.ktor.server.engine.embeddedServerimport io.ktor.server.netty.Nettyimport java.io.Filefun main(args: Array<string>) { val port = if (args.isEmpty()) 8080 else args[0].toInt() val server = embeddedServer(Netty, port = port) { routing { static("css") { files("../src/main/css") } static("js") { files("../dist") } static("node_modules") { files("../node_modules") } get("/") { try { val text = File("../src/main/html/index.html").readText(Charsets.UTF_8) call.respondText(text, ContentType.Text.Html) } catch (e: Exception) { e.printStackTrace() } } } } server.start(wait = false)}</string> |
На этом этапе мы можем просто запустить сервер из каталога server , выполнив:
../gradlew runServer
Обратите внимание, что оболочка gradle установлена в корневом каталоге, поэтому мы запускаем ее с ../gradlew вместо обычного ./gradlew .
Теперь, если мы откроем браузер на localhost:8888 мы увидим это:
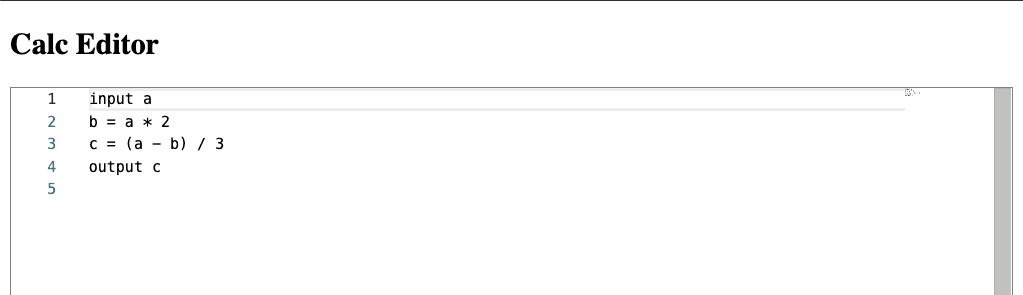
Довольно простой, правда? Посмотрим, как мы можем это улучшить.
Подсветка синтаксиса
Первое, что нам нужно добавить, это подсветка синтаксиса, то есть мы хотим представлять разные токены по-разному, чтобы ключевые слова можно было отличить от идентификаторов, литералы можно было отличить от операторов и т. Д. Несмотря на то, что эта функция является базовой, она полезна для обратной связи при вводе нашего кода. Когда у нас есть подсветка синтаксиса, мы можем взглянуть на код и понять его гораздо быстрее. И это приятное прикосновение.
Чтобы добавить поддержку подсветки синтаксиса, нам нужно изменить несколько файлов:
- Нам нужно будет написать необходимый код TypeScript
- Нам нужно будет включить этот код в
index.js - Нам нужно будет вызвать новый код в
index.htmlи выполнить необходимые подключения с Монако.
Давайте начнем.
В ParserFacade.ts мы изменим только одно: экспорт createLexer .
|
1
2
3
|
export function createLexer(input: String) { ...} |
Мы также добавим еще один файл TypeScript с именем CalcTokensProvider.ts :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
/// <reference path="../../../node_modules/monaco-editor/monaco.d.ts" />import {createLexer} from './ParserFacade'import {CommonTokenStream, error, InputStream} from '../../../node_modules/antlr4/index.js'import ILineTokens = monaco.languages.ILineTokens;import IToken = monaco.languages.IToken;export class CalcState implements monaco.languages.IState { clone(): monaco.languages.IState { return new CalcState(); } equals(other: monaco.languages.IState): boolean { return true; }}export class CalcTokensProvider implements monaco.languages.TokensProvider { getInitialState(): monaco.languages.IState { return new CalcState(); } tokenize(line: string, state: monaco.languages.IState): monaco.languages.ILineTokens { // So far we ignore the state, which is not great for performance reasons return tokensForLine(line); }}const EOF = -1;class CalcToken implements IToken { scopes: string; startIndex: number; constructor(ruleName: String, startIndex: number) { this.scopes = ruleName.toLowerCase() + ".calc"; this.startIndex = startIndex; }}class CalcLineTokens implements ILineTokens { endState: monaco.languages.IState; tokens: monaco.languages.IToken[]; constructor(tokens: monaco.languages.IToken[]) { this.endState = new CalcState(); this.tokens = tokens; }}export function tokensForLine(input: string): monaco.languages.ILineTokens { var errorStartingPoints : number[] = [] class ErrorCollectorListener extends error.ErrorListener { syntaxError(recognizer, offendingSymbol, line, column, msg, e) { errorStartingPoints.push(column) } } const lexer = createLexer(input); lexer.removeErrorListeners(); let errorListener = new ErrorCollectorListener(); lexer.addErrorListener(errorListener); let done = false; let myTokens: monaco.languages.IToken[] = []; do { let token = lexer.nextToken(); if (token == null) { done = true } else { // We exclude EOF if (token.type == EOF) { done = true; } else { let tokenTypeName = lexer.symbolicNames[token.type]; let myToken = new CalcToken(tokenTypeName, token.column); myTokens.push(myToken); } } } while (!done); // Add all errors for (let e of errorStartingPoints) { myTokens.push(new CalcToken("error.calc", e)); } myTokens.sort((a, b) => (a.startIndex > b.startIndex) ? 1 : -1) return new CalcLineTokens(myTokens);} |
Что касается index.js нам в основном нужно импортировать материал и предоставлять его таким образом, чтобы мы могли получить к нему доступ со страницы HTML. Как? Проще говоря, мы добавим необходимый элемент в объект window , если он присутствует (и он присутствует только при доступе к коду из браузера).
|
1
2
3
4
5
6
7
|
const CalcTokensProvider = require('../../main-generated/javascript/CalcTokensProvider.js');if (typeof window === 'undefined') {} else { window.CalcTokensProvider = CalcTokensProvider;} |
На данный момент все, что остается сделать, это сообщить Монако о нашем новом CalcTokensProvider . Ну, это и настроить некоторые стили, чтобы мы могли видеть различные типы токенов в редакторе:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
<script> require.config({ paths: { 'vs': 'node_modules/monaco-editor/min/vs' }}); require(['vs/editor/editor.main'], function() { monaco.languages.register({ id: 'calc' }); monaco.languages.setTokensProvider('calc', new CalcTokensProvider.CalcTokensProvider()); let literalFg = '3b8737'; let idFg = '344482'; let symbolsFg = '000000'; let keywordFg = '7132a8'; let errorFg = 'ff0000'; monaco.editor.defineTheme('myCoolTheme', { base: 'vs', inherit: false, rules: [ { token: 'number_lit.calc', foreground: literalFg }, { token: 'id.calc', foreground: idFg, fontStyle: 'italic' }, { token: 'lparen.calc', foreground: symbolsFg }, { token: 'rparen.calc', foreground: symbolsFg }, { token: 'equal.calc', foreground: symbolsFg }, { token: 'minus.calc', foreground: symbolsFg }, { token: 'plus.calc', foreground: symbolsFg }, { token: 'div.calc', foreground: symbolsFg }, { token: 'mul.calc', foreground: symbolsFg }, { token: 'input_kw.calc', foreground: keywordFg, fontStyle: 'bold' }, { token: 'output_kw.calc', foreground: keywordFg, fontStyle: 'bold' }, { token: 'unrecognized.calc', foreground: errorFg } ] }); let editor = monaco.editor.create(document.getElementById('container'), { value: [ 'input a', 'b = a * 2', 'c = (a - b) / 3', 'output c', '' ].join('\n'), language: 'calc', theme: 'myCoolTheme' }); });</script> |
Теперь мы готовы к работе. Нам просто нужно запустить tsc && webpack и мы должны увидеть, что:

Если мы введем некоторые токены, которые ANTLR не распознает, мы должны получить их красным цветом:

И вот, пожалуйста: мы объединили наш лексер ANTLR с Монако! Итак, у нас есть первая часть нашего собственного браузера на основе нашего небольшого нового языка!
Я немного взволнован, а ты?
Отчет об ошибках
Еще одна важная функция — отчеты об ошибках: мы хотим указать на ошибки, когда пользователь пишет код.
В настоящее время возможны разные типы ошибок:
- лексические ошибки: когда некоторый текст не может быть распознан как принадлежащий токену любого типа
- синтаксические ошибки: когда структура кода не верна
- семантические ошибки: они зависят от характера языка. Примером семантических ошибок является использование необъявленных переменных или операций с несовместимыми типами.
В нашем случае:
- у нас нет лексических ошибок, так как наш лексер ловит все виды символов. Мы делаем это, добавляя специальное определение токена:
unrecognized. Теперь токен типаunrecognizedнельзя использовать ни в одном операторе, поэтому он всегда будет приводить к синтаксическим ошибкам - у нас есть синтаксические ошибки, и мы собираемся показать их
- мы не собираемся рассматривать семантические ошибки в контексте этого урока, поскольку они требуют некоторой продвинутой обработки дерева разбора. Например, мы должны выполнить разрешение символов, чтобы проверить все значения, которые были объявлены перед использованием. В любом случае они могут отображаться в Монако так же, как мы собираемся отображать синтаксические ошибки, они просто должны быть рассчитаны по-разному, и как рассчитать их, выходит за рамки этого урока
Теперь рассмотрим сообщение о синтаксических ошибках в редакторе. Мы хотим получить что-то вроде этого:
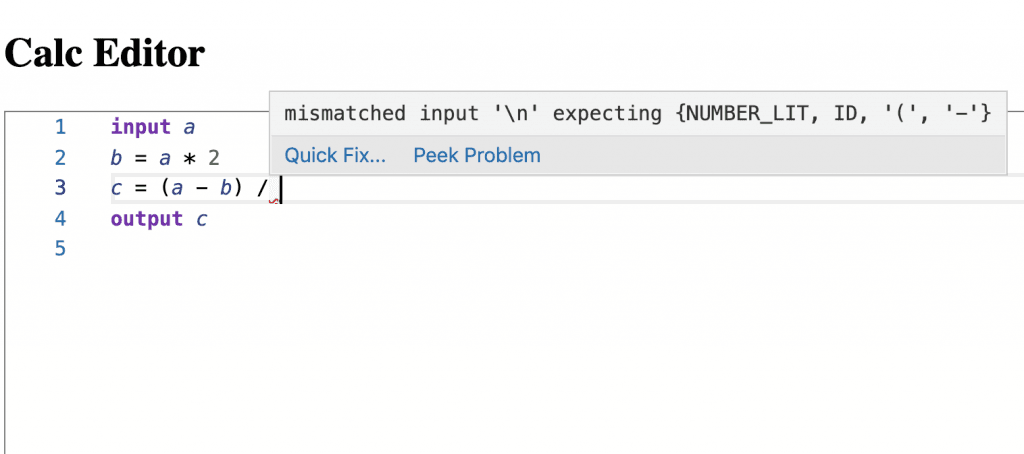
Теперь нам нужно связать ошибки, возникшие в ANTLR с Монако. Однако, прежде чем сделать это, мы хотим немного изменить нашу грамматику. Почему? Потому что мы хотим, чтобы разные операторы оставались на одной строке. Таким образом, синтаксические ошибки будут обнаружены в более интуитивных позициях.
Рассмотрим этот пример:
а = 1 + б = 3
В настоящее время ANTLR сообщит об ошибке во второй строке. Почему? Поскольку строка a = 1 + сама по себе кажется правильной, ей просто не хватает другого элемента для завершения. Таким образом, ANTLR берет из второй строки построение выражения a = 1 + b , которое является правильным. В этот момент он встречает токен = и сообщает об ошибке на токене = . Что может сбивать с толку бедных, простых пользователей нашего DSL. Мы хотим сделать вещи более интуитивными, заставив ANTLR сообщать об ошибке в конце строки 1, предполагая, что строка не завершена.
Поэтому, чтобы достичь этого, мы начинаем с того, что немного подправим наши грамматики, чтобы сделать перевод строки значимым.
В грамматике Lexer мы меняем определение NL , удаляя действие отправки токена на канал WS :
|
1
|
NL: ('\r\n' | '\r' | '\n'); |
Теперь мы должны рассмотреть NL в нашей грамматике парсера:
Мы в основном заставляем каждое утверждение заканчиваться токеном NL .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
eol: NL ;input: INPUT_KW ID eol ;output: OUTPUT_KW ID eol ;calc: target=ID EQUAL value=expression eol ; |
Хорошо. Это хорошо. Теперь давайте посмотрим, как мы можем начать собирать ошибки из ANTLR. Сначала мы создадим класс для представления ошибок, а затем добавим ANTLR ErrorListener чтобы получить ошибки, о которых сообщает ANTLR, и использовать их для создания экземпляров Error .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
export class Error { startLine: number; endLine: number; startCol: number; endCol: number; message: string; constructor(startLine: number, endLine: number, startCol: number, endCol: number, message: string) { this.startLine = startLine; this.endLine = endLine; this.startCol = startCol; this.endCol = endCol; this.message = message; }}class CollectorErrorListener extends error.ErrorListener { private errors : Error[] = [] constructor(errors: Error[]) { super() this.errors = errors } syntaxError(recognizer, offendingSymbol, line, column, msg, e) { var endColumn = column + 1; if (offendingSymbol._text !== null) { endColumn = column + offendingSymbol._text.length; } this.errors.push(new Error(line, line, column, endColumn, msg)); }} |
На этом этапе мы можем добавить новую функцию под названием validate . Эта функция будет пытаться проанализировать входные данные и записать каждую ошибку, полученную при синтаксическом анализе, просто для сообщения о них. Мы могли бы позже показать эти ошибки в редакторе.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
export function validate(input) : Error[] { let errors : Error[] = [] const lexer = createLexer(input); lexer.removeErrorListeners(); lexer.addErrorListener(new ConsoleErrorListener()); const parser = createParserFromLexer(lexer); parser.removeErrorListeners(); parser.addErrorListener(new CollectorErrorListener(errors)); parser._errHandler = new CalcErrorStrategy(); const tree = parser.compilationUnit(); return errors;} |
Мы почти на месте, но есть оговорка. Дело в том, что ANTLR по умолчанию пытается добавить или удалить токены для анализа при обнаружении ошибки. В целом это работает достаточно хорошо, но в нашем случае мы не хотим, чтобы ANTLR пытался удалить новую строку. Давайте посмотрим, как ANTLR будет анализировать наш пример:
а = 1 + б = 3
ANTLR признает наличие ошибки в строке 1, но, по ее мнению, проблема заключается в дополнительном переводе строки. Таким образом, он сообщит о новой строке в конце строки 1 как об ошибке, а затем продолжит синтаксический анализ, делая вид, что его там нет. Это поведение определяется стратегией ошибок, то есть как ANTLR реагирует на ошибки синтаксического анализа. Затем он распознает присваивание a = 1 + b и сообщит об ошибке в знаке равенства в строке 2. Мы хотим избежать этого и настроить, как ANTLR пытается исправить ввод для продолжения анализа. Мы делаем это путем реализации нашей ErrorStrategy .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
class CalcErrorStrategy extends DefaultErrorStrategy { reportUnwantedToken(recognizer: Parser) { return super.reportUnwantedToken(recognizer); } singleTokenDeletion(recognizer: Parser) { var nextTokenType = recognizer.getTokenStream().LA(2); if (recognizer.getTokenStream().LA(1) == CalcParser.NL) { return null; } var expecting = this.getExpectedTokens(recognizer); if (expecting.contains(nextTokenType)) { this.reportUnwantedToken(recognizer); // print("recoverFromMismatchedToken deleting " \ // + str(recognizer.getTokenStream().LT(1)) \ // + " since " + str(recognizer.getTokenStream().LT(2)) \ // + " is what we want", file=sys.stderr) recognizer.consume(); // simply delete extra token // we want to return the token we're actually matching var matchedSymbol = recognizer.getCurrentToken(); this.reportMatch(recognizer); // we know current token is correct return matchedSymbol; } else { return null; } } getExpectedTokens = function(recognizer) { return recognizer.getExpectedTokens(); }; reportMatch = function(recognizer) { this.endErrorCondition(recognizer); };} |
На практике мы просто говорим не пытаться притворяться, что новых строк там нет. Вот и все.
На данный момент мы можем написать несколько тестов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
function checkError(actualError, expectedError) { it('should have startLine ' + expectedError.startLine, function () { assert.equal(actualError.startLine, expectedError.startLine); }); it('should have endLine ' + expectedError.endLine, function () { assert.equal(actualError.endLine, expectedError.endLine); }); it('should have startCol ' + expectedError.startCol, function () { assert.equal(actualError.startCol, expectedError.startCol); }); it('should have endCol ' + expectedError.endCol, function () { assert.equal(actualError.endCol, expectedError.endCol); }); it('should have message ' + expectedError.message, function () { assert.equal(actualError.message, expectedError.message); });}function checkErrors(actualErrors, expectedErrors) { it('should have ' + expectedErrors.length + ' error(s)', function (){ assert.equal(actualErrors.length, expectedErrors.length); }); var i; for (i = 0; i < expectedErrors.length; i++) { checkError(actualErrors[i], expectedErrors[i]); }}function parseAndCheckErrors(input, expectedErrors) { let errors = parserFacade.validate(input); checkErrors(errors, expectedErrors);}describe('Validation of simple errors on single lines', function () { describe('should have recognize missing operand', function () { parseAndCheckErrors("o = i + \n", [ new parserFacade.Error(1, 1, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}") ]); }); describe('should have recognize extra operator', function () { parseAndCheckErrors("o = i +* 2 \n", [ new parserFacade.Error(1, 1, 7, 8, "extraneous input '*' expecting {NUMBER_LIT, ID, '(', '-'}") ]); });});describe('Validation of simple errors in small scripts', function () { describe('should have recognize missing operand', function () { let input = "input i\no = i + \noutput o\n"; parseAndCheckErrors(input, [ new parserFacade.Error(2, 2, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}") ]); }); describe('should have recognize extra operator', function () { let input = "input i\no = i +* 2 \noutput o\n"; parseAndCheckErrors(input, [ new parserFacade.Error(2, 2, 7, 8, "extraneous input '*' expecting {NUMBER_LIT, ID, '(', '-'}") ]); });});describe('Validation of examples being edited', function () { describe('deleting number from division', function () { let input = "input a\n" + "b = a * 2\n" + "c = (a - b) / \n" + "output c\n"; parseAndCheckErrors(input, [ new parserFacade.Error(3, 3, 14, 15, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}") ]); }); describe('deleting number from multiplication', function () { let input = "input a\n" + "b = a * \n" + "c = (a - b) / 3\n" + "output c\n"; parseAndCheckErrors(input, [ new parserFacade.Error(2, 2, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}") ]); }); describe('adding plus to expression', function () { let input = "input a\n" + "b = a * 2 +\n" + "c = (a - b) / 3\n" + "output c\n"; parseAndCheckErrors(input, [ new parserFacade.Error(2, 2, 11, 12, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}") ]); });}); |
В производстве мы можем использовать более продвинутый подход, чтобы избежать дорогостоящих расчетов при каждом нажатии клавиши. Однако этот подход будет хорошо работать для небольших документов.
Вот и все! У нас есть простая, но приятная интеграция между ANTLR и Монако. Мы можем начать отсюда, чтобы создать отличный редактор для наших пользователей.
Резюме
Все больше и больше приложений переходят в Интернет. В то время как профессионалы, использующие специальные инструменты, могут захотеть установить такие инструменты, как настольные приложения, есть ряд случайных пользователей или пользователей, которые не так технически подходят, для которых предоставление веб-инструмента имеет большой смысл.
Мы убедились, что можем создавать доменные языки (или DSL), которые позволяют экспертам в области писать многофункциональные и важные приложения. Создавая языки высокого уровня, мы можем сделать их доступными для написания кода самостоятельно. Тем не менее, они могут быть невосприимчивы к использованию инструментов со сложными пользовательскими интерфейсами, и для организаций иногда возникает проблема доставки IDE на их компьютеры. Для этого пользователя браузерные редакторы могут быть отличным решением.
В этом уроке мы увидели, как мы можем написать грамматику для текстового языка и интегрировать ее в Монако, получая подсветку синтаксиса и отчеты об ошибках. Это прочная основа для написания редактора, но оттуда мы должны рассмотреть больше вещей, таких как:
- семантическая проверка
- автозавершение
- предоставляя способ выполнения кода
- поддерживать некоторую форму управления версиями (в зависимости от типа пользователей мы можем захотеть что-то не так сложное, как git!)
Так что еще есть над чем поработать, но мы думаем, что Монако может стать отличным решением.
PS Если вы нашли ошибку или что-то не понятно, пожалуйста, напишите мне . Кроме того, я всегда готов услышать ваши мысли о Монако, ANTLR или других инструментах. Не стесняйтесь связаться со мной в любое время!
|
См. Оригинальную статью здесь: Написание редактора на основе браузера с использованием Monaco и ANTLR: Разбор с легкостью Мнения, высказанные участниками Java Code Geeks, являются их собственными. |