В течение прошлого года или около того было уделено много внимания обнаружению утечек памяти в JVM. Утечки памяти могут вызвать хаос в JVM. Они могут быть непредсказуемыми и привести к дорогостоящему снижению производительности или даже простоя при перезапуске сервера. В идеале, утечки памяти обнаруживаются задолго до запуска приложения в производство. К сожалению, тестирование в нижнем состоянии часто недостаточно для того, чтобы вызвать снижение производительности или ошибки OutOfMemoryError . Иногда утечка медленно крадет память в течение недель или месяцев безотказной работы. Этот тип утечки трудно обнаружить до производства, но не невозможно. В этой статье будет изложен один из подходов к поиску таких утечек без затрат на копейки!
Основные черты этого подхода основаны на PhantomReference и инструментах. PhantomReference обычно не используются, поэтому давайте рассмотрим подробнее. В Java существует три типа ссылок : WeakReference , SoftReference и PhantomReference . Большинство разработчиков знакомы с WeakReferences. Они просто не предотвращают сборку мусора объектов, на которые они ссылаются. SoftReferences похожи на WeakReferences, но иногда препятствуют сборке мусора их ссылочных объектов. SoftReferences, скорее всего, предотвратит сборку мусора, если доступная память будет считаться избыточной во время сборки мусора. Наконец, PhantomReferenceОни почти не похожи на своих слабых и мягких братьев и сестер в том смысле, что они не предназначены для того, чтобы приложение непосредственно содержало эти ссылки. PhantomReference используются в качестве механизма уведомления о том, когда объект собирается собирать мусор. В Javadoc говорится, что «фантомные ссылки чаще всего используются для планирования действий по предварительной очистке более гибким способом, чем это возможно с механизмом финализации Java». Мы не заинтересованы в выполнении какой-либо очистки, но мы будем записывать, когда объект собирается мусором.
Инструментарий является другой неотъемлемой функциональностью. Инструментарий — это процесс изменения байт-кода класса перед его загрузкой виртуальной машиной. Это мощная функция Java и может использоваться для мониторинга, профилирования и, в нашем случае, регистрации событий. Мы будем использовать инструментарий для изменения классов приложений таким образом, что каждый раз, когда создается экземпляр объекта, мы создаем для него PhantomReference . Дизайн для этого механизма обнаружения утечки памяти должен быть разработан сейчас. Мы будем использовать инструментарий, чтобы заставить классы сообщать нам, когда они создают объекты, и мы будем использовать PhantomReference для записи, когда они будут собирать мусор. Наконец, мы будем использовать хранилище данных для записи этих данных. Эти данные будут основой для нашего анализа, чтобы определить, протекают ли объекты.
Прежде чем мы продолжим, давайте перейдем к скриншоту того, что мы сможем сделать в конце этой статьи.
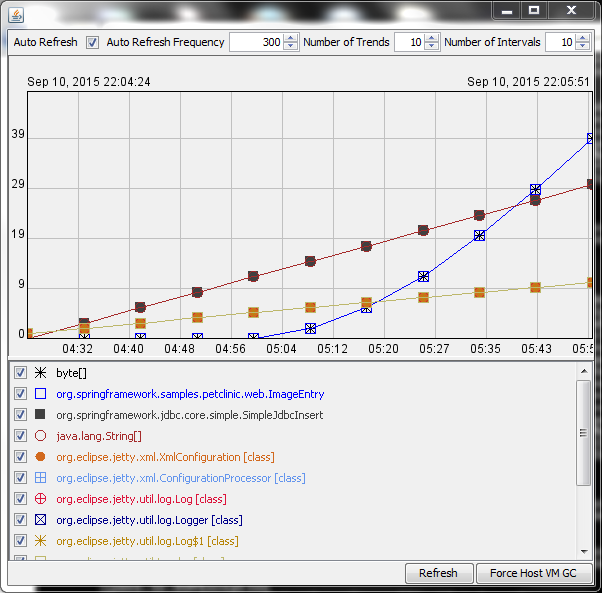
На этом графике показано количество объектов, которые были выделены, но не были собраны с течением времени. Запущенный код является демонстрационным приложением Plumbr . Plumbr добавил несколько утечек памяти в рамках Spring «ы Pet Clinic образца приложения. График станет более понятным, когда вы увидите соответствующий код с утечкой:
public class LeakingInterceptor extends HandlerInterceptorAdapter {
static List<ImageEntry> lastUsedImages =
Collections.synchronizedList(new LinkedList<ImageEntry>());
private final byte[] imageBytes;
public LeakingInterceptor(Resource res) throws IOException {
imageBytes = FileCopyUtils.copyToByteArray(res.getInputStream());
}
@Override
public boolean preHandle
(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
byte[] image = new byte[imageBytes.length];
System.arraycopy(imageBytes, 0, image, 0, image.length);
lastUsedImages.add(new ImageEntry(image));
return true;
}
}При каждом запросе этот перехватчик пропускает объект ImageEntry , который ссылается на массив байтов. Следовательно, после всего 10 обновлений главной страницы PetClinic вы уже можете видеть тенденцию утечки на графике.
Теперь давайте начнем писать код. Первый класс, который нам понадобится, — это интерфейс, который инструментальный байт-код будет вызывать при создании экземпляра класса. Давайте назовем этот класс «Recorder» и создадим статический метод для получения объектов:
class Recorder {
public static void record(Object o) {
...
}
}Детали реализации этого метода выходят за рамки данной статьи. Теперь, когда у нас есть интерфейс, мы можем работать над нашим программным кодом. Инструментарий — это широкая тема, но мы будем ограничивать область применения нашего проекта. Мы будем использовать ASM (из ObjectWeb) для выполнения манипуляций с байт-кодом. В этом руководстве предполагается, что вы уже знакомы с ASM. Если вы этого не сделаете, вы можете сначала потратить некоторое время на то, чтобы освежиться.
Проще говоря, мы хотим изменить любой код приложения, который создает новый объект, так, чтобы он вызывал наш метод Recorder.record (…) с новым объектом в качестве параметра. Чтобы идентифицировать «код приложения», мы позволим пользователю предоставить набор регулярных выражений, которые будут указывать набор классов, которые должны быть включены, и классы, которые должны быть исключены. Мы создадим класс с именем Configuration для загрузки файла свойств конфигурации, который содержит эту информацию. Этот класс будет использоваться, чтобы определить, должен ли класс быть инструментирован. Позже мы будем использовать его для определения некоторых других свойств.
Инструментарий происходит во время выполнения по мере загрузки классов. Инструментарий выполняется «агентами», которые упакованы в файл JAR. Если вы не знакомы с агентами, вы можете проверить документацию javadoc пакета java.lang.instrument . Точкой входа в агент является класс агента. Вот возможные сигнатуры методов для точек входа оператора:
public static void premain(String agentArgs, Instrumentation inst);
public static void agentmain(String agentArgs, Instrumentation inst);Метод premain вызывается, когда агент задается с помощью параметра -javaagent командной строки JVM при запуске. Основной метод агента вызывается, если агент подключен к существующей JVM. Наш агент будет наиболее полезным, если он применяется при запуске. Можно предположить, что вы можете подключить агент после обнаружения утечки памяти, но он может предоставить только те данные утечки памяти, которые он записал с момента подключения. Далее это будут только классы инструментов, которые загружаются после того, как это присоединено. Можно заставить JVM переопределить классы, но наш компонент не будет обеспечивать эту функциональность.
Давайте назовем наш класс агента HeapsterAgent и передадим каждому из перечисленных выше методов тело:
public static void premain(String agentArgs, Instrumentation inst) {
configure(agentArgs, inst);
}
public static void agentmain(String agentArgs, Instrumentation inst) {
configure(agentArgs, inst);
}Процесс инициализации для обеих точек входа будет одинаковым, поэтому мы рассмотрим их в одном методе конфигурации. Мы пропустим большинство деталей реализации Конфигурации, чтобы сосредоточиться на инструментарии. Мы хотим, чтобы наш класс реализовывал интерфейс java.lang.instrument.ClassFileTransformer . Когда ClassFileTransformer зарегистрирован в JVM, ему предоставляется возможность изменять классы по мере их загрузки. Наш класс HeapsterAgent теперь имеет эту подпись:
public class HeapsterAgent implements ClassFileTransformerМетод configure должен зарегистрировать экземпляр HeapsterAgent в JVM, чтобы перехватить загружаемые классы. Вот код:
inst.addTransformer(new MemoryTraceAgent());«Inst» — это параметр Instrumentation метода configure (…).
Умные читатели уже могут подумать: «Как загрузчики классов приложения обнаружат новый класс Recorder?». Есть несколько решений этой проблемы. Мы могли бы использовать метод appendToBootstrapClassLoaderSearch (JarFile jarfile) класса Instrumentation для добавления соответствующих классов в загрузочный путь к классам, где классы должны обнаруживаться загрузчиками классов приложения. Однако, чтобы обнаружить утечку классов, сам класс ClassLoader должен быть инструментирован. Это можно сделать эффективно только путем создания собственного jar — файла, содержащего java.lang.ClassLoader, и замены собственного java.lang.ClassLoader в JRE с помощью -Xbootclasspath / p. параметр. Следовательно, мы можем также упаковать другие вспомогательные классы в одну и ту же банку.
Давайте теперь перейдем к методу преобразования. Этот метод предоставляется в интерфейсе ClassFileTransformer . Вот полная подпись:
public byte[] transform(ClassLoader loader, String className,
Class<?> classBeingRedefined, ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws IllegalClassFormatException;Это где магия инструментов начинает происходить. Этот метод вызывается каждый раз, когда JVM загружает класс. Наиболее важными параметрами для нас являются className и classfileBuffer . className поможет нам определить, является ли класс классом приложения, а classfileBuffer — это байтовый массив байтового кода, который мы можем изменить. Давайте посмотрим, как мы будем исключать какие классы изменять. Очевидно, что мы хотим изменить только классы приложения, поэтому мы сравним параметр className с нашими включениями и исключениями. Имейте в виду, что className находится во внутреннем формате и для разделителей имен использует косую черту (/) вместо точек (.). Мы также не хотим использовать наш агентский код. Мы сможем контролировать это, сравнивая путь к пакету className с нашей собственной кодовой базой. Наконец, при разработке этого кода я выделил несколько классов Oracle, которые просто никогда не должны быть инструментированы (возможно, их больше). Однако, в общем, если вы ищете утечки в вашем приложении, вы, вероятно, можете игнорировать java. *, Javax. *, Sun. * И т. Д. Я жестко запрограммировал некоторые из них в методе transform. Если вы считаете, что в коде Oracle есть ошибка, вы всегда можете отключить эту фильтрацию. Однако я рекомендую вам пощадить код Oracle, который вы используете из базовых пакетов, таких как java.lang Маловероятно, что вы первыми обнаружили ошибку в этих классах и можете отправить свою JVM в неисправимый штопор.
Последняя часть метода преобразования является фактическим преобразованием. Вот важный код:
public byte[] transform(ClassLoader loader, String className,
Class<?> classBeingRedefined, ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws IllegalClassFormatException {
if (className.startsWith("java") || className.startsWith("sun")) return null;
if (!isAgentClass(dotName) && configuration.isIncluded(dotName)) {
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
Transformer transformer = new Transformer(writer);
ClassReader reader = new ClassReader(classfileBuffer);
reader.accept(transformer, ClassReader.EXPAND_FRAMES);
return writer.toByteArray();
}
else return null;
}Если полное имя класса начинается с «java» или «sun», мы возвращаем null. Возвращение null — это способ вашего агента сказать: «Я не заинтересован в преобразовании этого класса». Затем мы проверяем, соответствует ли className классу агента, вызывая isAgentClass (…) . Вот реализация:
boolean isAgentClass(String className) {
return className.startsWith("ca.discotek.rebundled.org.objectweb.asm") ||
className.startsWith("ca.discotek.heapster");
}В приведенном выше фрагменте кода вы заметите, что я изменил имя базового пакета для классов ASM с org.objectweb.asm на ca.discotek.rebundled.org.objectweb.asm . Классы агентов будут доступны в пути загрузки классов. Если бы я не изменил пространство имен пакетов классов ASM агента, другие инструменты или приложения, работающие в JVM, могут непреднамеренно использовать классы ASM агента.
Остальная часть метода преобразования — довольно простые операции ASM. Однако теперь нам нужно внимательно посмотреть, как работает класс HeapsterTransformer . Как вы можете догадаться, HeapsterTransformer расширяет класс ClassVisitor и переопределяет метод посещения:
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
super.visit(version, access, name, signature, superName, interfaces);
this.className = name;
this.superName = superName;
}Он записывает имя класса и имя суперкласса для последующего использования.
Метод visitMethod также переопределяется:
public MethodVisitor visitMethod
(int access, String name, String desc, String signature, String[] exceptions) {
return new HeapsterMethodVisitor
(name, access, desc, super.visitMethod(access, name, desc, signature, exceptions));
}Это заставляет посетить наш собственный MethodVisitor с именем HeapsterMethodVisitor . HeapsterMethodVisitor необходимо добавить некоторые локальные переменные, чтобы он был подклассом LocalVariableSorter . Параметры конструктора включают имя метода, которое записывается для последующего использования. Другие методы , которые HeapsterMethodVisitor переопределения являются: visitMethodInsn , visitTypeInsn и visitIntInsn . Кто-то может подумать, что мы можем сделать все это в visitMethodInsn , добавив код, когда мы видим вызов конструктора ( <init>), но, к сожалению, все не так просто. Сначала давайте рассмотрим, что мы пытаемся достичь. Мы хотим записывать каждый раз, когда создается экземпляр объекта приложения. Это может произойти несколькими способами. Наиболее очевидным является «новая» операция. Но как насчет Class.newInstance () или когда десериализация ObjectInputStream осуществляется с помощью метода readObject ? Эти методы не используют оператор «new». Кроме того, как насчет массивов? Создание массива не является инструкцией visitMethodInsn , но мы также хотим записать их. Само собой разумеется, сборка кода для захвата всех этих событий является сложной задачей.
Давайте сначала посмотрим на метод visitMethodInsn . Вот первое утверждение:
if (opcode == Opcodes.INVOKESPECIAL && name.equals("<init>") &&
!isIgnorableConstructorCall(className, methodName, owner, superName)) {Opcodes.INVOKESPECIAL указывает, что либо вызывается конструктор, либо статический инициализатор. Мы заботимся только о звонках конструкторам. Кроме того, нас не волнуют все вызовы конструктора. В частности, мы заботимся только о вызове первого конструктора, а не о цепочке вызовов конструкторов от конструктора к его конструктору суперкласса. Вот почему так важно было записать имя суперкласса ранее. Мы используем метод isIgnorableConstructorCall, чтобы определить, хотим ли мы использовать инструмент:
boolean isIgnorableConstructorCall(String className, String containingMethodName, String owner, String superName) {
if (owner.equals(className) && containingMethodName.equals("<init>")) return true;
else if (owner.equals("java/lang/Object")) return true;
else return superName.equals(owner);
}Первый оператор if проверяет, вызывает ли конструктор другой конструктор в том же классе (например, this (…)). Вторая строка проверяет, вызывается ли вызов конструктора для типа java.lang.Object . При использовании ASM, любого класса, суперкласс которого java.lang.Object , суперкласс будет указан как нулевой . Это предотвращает возникновение исключения NullPointerException в третьей строке, где мы проверяем, что вызывается вызов конструктора для суперкласса (например, super (…) ). Объект типа java.lang.Object будет иметь нулевой тип суперкласса.
Теперь, когда мы установили, какие конструкторы мы можем игнорировать, давайте вернемся к visitMethodInsn . Как только вызов конструктора завершен, мы можем записать объект:
mv.visitMethodInsn(opcode, owner, name, desc);
addRecorderDotRecord();Первая строка идентична исходной инструкции байт-кода. Вторая строка вызывает addRecorderDotRecord () . Этот метод содержит байт-код для вызова нашего класса Recorder . Мы будем использовать это несколько раз, так что это по-своему. Вот код:
void addRecorderDotRecord() {
mv.visitMethodInsn
(Opcodes.INVOKESTATIC, Recorder.class.getName().replace('.', '/'), "record", "(Ljava/lang/Object;)V");
}Все это должно показаться довольно простым, если вы понимаете ASM, но есть одно необъяснимое упущение, которое должно быть очевидным для эксперта по байт-коду. Java основана на стеке. Когда мы вызвали оригинальный метод:
mv.visitMethodInsn(opcode, owner, name, desc);… он вытолкнул новый объект из стека. Но инструкция addRecorderDotRecord ожидает, что новый объект все еще будет в стеке. И когда он завершится, он появится на новом объекте. Это не имеет смысла, потому что мы не исследовали остальные переопределенные методы. Давайте перейдем к посещению TypeInsn (…) . Вот первая половина:
public void visitTypeInsn(int opcode, String type) {
mv.visitTypeInsn(opcode, type);
if (opcode == Opcodes.NEW) {
addDup();
}
...VisitTypeInsn с Opcode.NEW в качестве параметра будет непосредственно предшествовать вызов конструктора объекта. Кроме того, спецификация JVM запрещает вам вызывать другие методы до инициализации объекта. Используя firstTypeInsn и секунду visitMethodInsn , мы можем добавить дополнительную ссылку на объект в стеке, который можно использовать в качестве параметра для нашего метода Recorder.record (…) .
Теперь давайте посмотрим на оператор elseMif-параметра visitMethodInsn . Методы newInstance , clone и readObject являются специальными методами, которые могут создавать экземпляры объекта без использования оператора «new». Когда мы сталкиваемся с этими методами, мы создаем дубликат ссылки на объект в стеке (используя addDup () ), а затем вызываем наш метод Recorder.record (…) , который выталкивает нашу дублированную ссылку на объект из стека. Вот метод addDup () :
void addDup() {
mv.visitInsn(Opcodes.DUP);
}Мы уже частично рассмотрели метод visitTypeInsn , но давайте теперь рассмотрим его полностью:
public void visitTypeInsn(int opcode, String type) {
mv.visitTypeInsn(opcode, type);
if (opcode == Opcodes.NEW) {
addDup();
}
else if (opcode == Opcodes.ANEWARRAY) {
addDup();
addRecorderDotRecord();
}
}Первая строка этого метода обеспечивает выполнение оригинальной инструкции. Мы уже обсуждали оператор if, который используется для дублирования объекта, созданного с помощью оператора «new», прежде чем мы добавим вызов в Recorder.record (…) . Оператор else-if-if обрабатывает создание одномерных массивов не примитивных типов. В этом случае мы добавляем в стек дублирующую ссылку на объект массива, а затем вызываем Recorder.record (…), который его выталкивает.
Далее у нас есть посещение MultiANewArrayInsn :
mv.visitMultiANewArrayInsn(desc, dims);
addDup();
addRecorderDotRecord();Этот метод довольно прост для понимания. Первая строка создает новый массив нескольких измерений. Вторая строка помещает дубликат ссылки в стек, а третья строка вызывает наш метод Recorder.record (…), который выталкивает дубликат из стека.
Наконец, у нас есть визитIntInsn:
public void visitIntInsn(int opcode, int operand) {
mv.visitIntInsn(opcode, operand);
if (opcode == Opcodes.NEWARRAY || opcode == Opcodes.MULTIANEWARRAY) {
addDup();
addRecorderDotRecord();
}
}Этот метод обрабатывает операцию байтового кода по созданию массива примитивов и многомерного массива. Оператор if идентифицирует эти операции, и его тело обеспечивает выполнение исходной инструкции, затем дублирует ссылку на объект массива в стеке, а затем мы вызываем Recorder.record (…), который выдает его.
Давайте теперь поменяем механизмы и рассмотрим код ASM, чтобы сгенерировать наш собственный метод java.lang.ClassLoader . Как упоминалось ранее, нам нужно определить наш собственный java.lang.ClassLoader для записи классов по мере их определения. Существует класс ClassLoaderGenerator , который выполняет основную работу по извлечению класса java.lang.ClassLoader из файла rt.jar нашей целевой JRE, но давайте углубимся в код ASM в ClassLoaderClassVisitor . Большая часть кода в этом классе не особенно интересна. Давайте право на visitMethodInsn метод его MethodVistor класса:
public void visitMethodInsn
(int opcode, String owner, String name, String desc, boolean isInterface) {
mv.visitMethodInsn(opcode, owner, name, desc, isInterface);
if (opcode == Opcodes.INVOKEVIRTUAL &&
includedMethodNameList.contains(name)) {
logger.info
("Instrumenting method invocation: " + owner + "." + name + ": " + desc);
int variableIndex = newLocal(Type.getType(Class.class));
visitVarInsn(Opcodes.ASTORE, variableIndex);
visitVarInsn(Opcodes.ALOAD, variableIndex);
addRecorderDotRecord();
visitVarInsn(Opcodes.ALOAD, variableIndex);
}
}Строка 3 вызывает исходную инструкцию. Оператор if строк 5-6 идентифицирует инструкцию как метод defineClass . В defineClass методы (а именно, defineClass0 , defineClass1 , defineClass2 ) являются носителями методы , которые возвращают java.lang.Class объект. Захватив эти вызовы, мы можем захватить, когда классы созданы. Строки 10-13 создают локальную переменную для хранения объекта java.lang.Class , создают вызов Recorder.record (…) и помещают Class обратно в стек. К вашему сведению, в другом коде ASM я использовал дубликат инструкция дублировать ссылку, но когда я запустил код, он не взаимодействовал, что привело меня к использованию локальной переменной.
Теперь мы покрыли все необходимые инструменты. Другой основной концепцией документирования является использование PhantomReference s. Мы уже обсуждали, как PhantomReference может сообщать нам, когда объект собирается мусором, но как это помогает нам отслеживать утечки памяти? Если мы используем PhantomReferenceЧтобы ссылаться на каждый объект приложения, мы можем исключить объекты с утечкой, если они регулярно собираются мусором. Оставшийся набор объектов становится нашим набором кандидатов. Если мы можем наблюдать тенденцию увеличения количества объектов для определенного типа, вполне вероятно, что мы обнаружили утечку. Вы должны заметить, что эти тенденции, которые сохраняются за пределами крупных сборщиков мусора, еще более вероятны с течением времени. Однако этот код не учитывает сборки мусора в настоящее время.
Теперь мы вернемся к классу Recorder для проверки функциональности PhantomReference . Метод записи имеет следующий код:
long classId = dataStore.newObjectEvent(o, System.currentTimeMillis());
PhantomReference<Object> ref = new PhantomReference<Object>(o, queue);
map.put(ref, classId);Первая строка ссылается на переменную с именем dataStore . Хранилище данных — это деталь реализации. Я реализовал хранилище данных в памяти, но я хочу сосредоточиться на PhantomReference s, поэтому мы пока проигнорируем эти детали. dataStore является экземпляром BufferedDataStore , который имеет следующую сигнатуру метода:
public long newObjectEvent(Object o, long time) throws NameNotFoundException;Этот метод принимает вновь созданный объект в качестве параметра и время создания объекта. Метод возвращает значение long, представляющее уникальный идентификатор для типа объекта. Следующим шагом является создание PhantomReference . Мы передаем ReferenceQueue в конструктор PhantomReference , который регистрирует его как объект, о котором мы хотим получать уведомление, когда он собирается сборщиком мусора. Наконец, мы храним ссылку и связанный с ней идентификатор класса на карте. Эти строки будут иметь больше смысла после просмотра кода, который слушает очередь
static class RemoverThread extends Thread {
public RemoverThread() {
setDaemon(true);
}
public void run() {
while (alive) {
PhantomReference ref = (PhantomReference) queue.remove();
Long classId = map.remove(ref);
dataStore.objectGcEvent(classId, System.currentTimeMillis());
}
}
}Это класс, который определен внутри класса Recorder . Это поток демона, что означает, что он не будет препятствовать выходу JVM, даже если он еще жив. Метод run содержит цикл while, который будет выполняться вечно, пока не будет вызван метод stop для изменения свойства alive . Метод ReferenceQueue.remove () блокируется до тех пор, пока не появится PhantomReference для удаления. Раз в PhantomReference появится, мы смотрим на Classid с карты. Затем записать событие, вызвав DATASTORE «s objectGcEvent метод.
Теперь мы рассмотрели, как инструктировать классы приложения для вставки метода Recorder.record (…) , как создавать PhantomReference для этих объектов и как реагировать на их события сборки мусора. Теперь у нас есть возможность записывать, когда объекты создаются и когда они собираются мусором. Как только эта базовая функциональность установлена, вы можете реализовать свой детектор утечки различными способами. Эта база кода использует хранилище данных в памяти. Этот тип источника данных использует то же пространство кучи, что и ваше приложение, для хранения данных, поэтому он не рекомендуется для долгосрочного обнаружения утечек (другими словами, это сама утечка памяти!). Более разумным вариантом для долгосрочного обнаружения будет сохранение данных в реальной базе данных.
Другим аспектом этого детектора утечки является подход к выявлению утечки. Некоторые детекторы утечек могут сказать вам «я обнаружил утечку!», Но этот не делает. Он предоставляет вам график основных кандидатов на утечку и позволяет пользователю оценить, какие объекты на самом деле являются утечками. Это означает, что вы должны быть активными в обнаружении утечек. Тем не менее, этот код может быть легко улучшен. Вы могли бы разработать алгоритм для изоляции утечек памяти, который информирует пользователя реактивно. Есть и другие возможные улучшения. Пользовательский интерфейс этого инструмента представляет собой линейный график объектов с наибольшей вероятностью утечки. Это вполне нормально для подсчета объектов, когда есть много памяти. Следовательно, одним из улучшений будет запись и отрисовка основных сборок мусора на графике.Знание того, что потенциально протекающие объекты выживают при сборке мусора, является очень хорошим показателем утечки памяти.
В этом проекте много кода, который мы не рассмотрели. Например, код для поиска тенденций, для построения графика данных или для запроса данных не рассматривался. Целью этой статьи было продемонстрировать, как можно собирать данные об утечке памяти, что делает несвязанный код вне области видимости. Тем не менее, есть еще одна тема, которую мы рассмотрим, как настроить и запустить это программное обеспечение.
Тип хранилища данных, используемого агентом в целевой JVM, определяется свойством data-store-class в файле конфигурации. На данный момент существует только реализация в памяти, ca.discotek.heapster.datastore.MemoryDataStore , для хранения данных утечки. Как это, это ужасная идея, потому что это сама утечка. Он не имеет политики выселения и в конечном итоге вызовет ошибку OutOfMemoryError . Когда MemoryDataStore инициализируется, он устанавливает сокет сервера, который клиенты могут использовать для запроса данных. MemoryDataStore использует файл конфигурации , чтобы получить номер порта сервера. Он также использует его для установки уровня журнала (который вам, вероятно, не нужно настраивать, но допустимые значения являются трассировкой , информация , предупреждение и ошибка .). Свойство включения — это регулярное выражение языка Java, используемое для указания классов вашего приложения, которые будут использоваться для обнаружения утечек памяти. Вы также можете указать свойство исключения, чтобы исключить пространства имен из свойства включения .
Чтобы подключиться к вашему серверу, вам нужно запустить клиент. Существует универсальный класс ca.discotek.heapster.client.gui.ClientGui , который ищет свойство класса клиента в файле конфигурации. Он создает экземпляр и использует его для связи с сервером. Поскольку наш агент настроен на использование класса MemoryDataStore , мы хотим, чтобы наш клиент ca.discotek.heapster.client.MemoryClient подключался к серверу MemoryDataStore. Класс MemoryClient ищет порт сервера в файле конфигурации. Для простоты настройки я поместил свойства сервера и клиента в один test.cfg Файл конфигурации. Если ваша целевая JVM находится на другом компьютере, чем ваш клиент, вам понадобятся отдельные файлы конфигурации. Вот что я использовал:
я создал класс ca.discotek.heapster.client.MemoryClient . Этот клиент использует файл конфигурации для поиска порта
client-class=ca.discotek.heapster.client.MemoryClient
data-store-class=ca.discotek.heapster.datastore.MemoryDataStore
log-level=info
server-port=8888
inclusion=ca\.discotek\.testheapster\..*Свойство включения указывает пространство имен моего тестового приложения под названием LeakTester , которое может различными способами создавать различные типы объектов. Вот снимок экрана:
Чтобы переопределить java.lang.ClassLoader JVM , мы сгенерируем наш собственный jar- файл начальной загрузки и будем использовать флаг JVM -Xbootclasspath / p, чтобы вставить jar-загрузчик в конце bootclasspath. Мы должны будем выполнить эту задачу для разных версий JRE целевой JVM. Между версиями могут быть внутренние изменения API, которые нарушили бы совместимость, если бы вы использовали сгенерированный класс ClassLoader из JRE X с JRE Y.
Предположим, вы загрузили дистрибутив утечки памяти и распаковали его в / temp / heapster . Предположим также, что ваша целевая версия JRE JVM — 1.6.0_05. Сначала создадим каталог /temp/heapster/1.6.0_05 для размещения файла, который мы собираемся сгенерировать. Далее мы запустим следующую команду:
java -jar /temp/heapster/heapster-bootpath-generator.jar /java/jdk1.6.0_05/jre/lib/rt.jar /temp/heapster/1.6.0_05Второй и третий программные аргументы указывают местоположение файла rt.jar целевой JVM и место, где вы хотите сохранить сгенерированный файл jar. Эта команда сгенерирует heapster- classloader.jar в /temp/heapster/1.6.0_05 .
Предполагая, что вы хотите запустить приложение LeakTester , связанное с этим проектом, вы должны выполнить следующую команду:
/java/jdk1.6.0_05/bin/java -Xbootclasspath/p:/temp/heapster/1.6.0_05/heapster-classloader.jar -javaagent:/temp/heapster/discotek-heapster-agent.jar=/temp/heapster/config/test.cfg ca.discotek.testheapster.LeakTesterДалее, давайте запустим клиент:
/java/jdk1.6.0_05/bin/java -classpath /temp/heapster/discotek-heapster-client.jar;/temp/heapster/discotek-graph-1.0.jar ca.discotek.heapster.client.gui.ClientGui /temp/heapster/config/test.cfgТеперь вы должны увидеть окно, похожее на снимок экрана выше . Однако этот снимок экрана использует пример приложения Plumbr, а не мое приложение LeakTester. Если вы хотите увидеть график примера приложения Plumbr, вы можете сделать следующее:
- Получите пример приложения Plumbr согласно их инструкциям.
- Откройте файл demo / start.bat в редакторе.
- В командной строке Java внизу, поместите -agentlib: plumbr -javaagent: .. \ .. \ plumbr.jar с -Xbootclasspath / p: /temp/heapster/1.6.0_05/heapster-classloader.jar -javaagent: / темп / heapster / discotek-heapster-agent.jar = / температуры / heapster / конфигурации / test.cfg
- Сохраните ваши изменения.
- Откройте /temp/heapster/config/test.cfg в редакторе.
- Измените свойство включения на включение =. * Petclinic. *
- Сохраните ваши изменения.
- Запустите пример приложения Plumbr, как вы делали раньше.
- Запустите ClientGui с использованием точно такой же командной строки, которую мы использовали для сценария LeakTester.
Обратите внимание, что вы можете генерировать трафик с помощью демонстрации Plumbr двумя способами: 1. Используйте create_usage.bat для управления трафиком с помощью JMeter или 2. откройте приложение в браузере (http: // localhost: 18080). Я рекомендую вам использовать браузер, чтобы вы могли контролировать трафик и наблюдать за последствиями обновления каждой страницы.
Эта статья была введением в то, как можно обнаружить утечки памяти с помощью инструментов и PhantomReferences. Это не означает, что это законченный продукт. Для улучшения проекта могут быть добавлены следующие функции:
- Укажите основные сборки мусора на графике
- Разрешить собирать следы стека при создании экземпляров объектов с утечками для выявления ошибочного кода источника
- Храните данные об экземплярах и сборке мусора в базе данных, чтобы приложение не стало утечкой памяти
- ClientGui может отображать доступную кучу и permgen (аналогично JConsole) (что может быть полезно для перекрестных ссылок на графы объектов)
- Обеспечить механизм удаления данных об экземплярах и сборке мусора.
Если вам понравилась эта статья и вы хотели бы прочитать больше, см. Другие статьи по разработке байт-кода на Discotek.ca или следите за Discotek.ca в твиттере, чтобы получить уведомление, когда моя следующая статья готова о том, как использовать классы для сбора статистики производительности!