Вступление
MapR-DB Table Replication позволяет реплицировать данные в другую таблицу, которая может находиться в том же кластере или в другом кластере. Это отличается от автоматической и внутрикластерной репликации, которая копирует данные в разные физические узлы для обеспечения высокой доступности и предотвращения потери данных.
Этот учебник посвящен репликации таблиц MapR-DB, которая реплицирует данные между таблицами в разных кластерах.
Репликация данных между различными кластерами позволяет:
- обеспечить еще один уровень аварийного восстановления, который защищает ваши данные и приложения от глобального сбоя центра обработки данных,
- подтолкнуть данные близко к приложениям и пользователям,
- агрегировать данные из нескольких центров обработки данных.
Топологии репликации
MapR-DB Table Replication предоставляет различные топологии для адаптации репликации к бизнес-требованиям и техническим требованиям:
- Репликация главный-подчиненный : в этой топологии вы реплицируете один путь из исходных таблиц в реплики. Реплики могут находиться в удаленном кластере или в кластере, где расположены исходные таблицы.
- Репликация с несколькими хозяевами : в этой топологии репликации есть два отношения «ведущий-ведомый», причем каждая таблица играет роль ведущего и ведомого. Клиентские приложения обновляют обе таблицы, и каждая таблица реплицирует обновления на другую.
В этом примере вы узнаете, как настроить репликацию с несколькими мастерами.
Предпосылки
- 2 MapR Clusters 5.x с лицензией Enterprise Edition
- в этой демонстрации они называются
cluster1иcluster2
- в этой демонстрации они называются
Настройка репликации
На следующих шагах вы сконфигурируете свои кластеры для включения репликации mutip-master следующим образом:
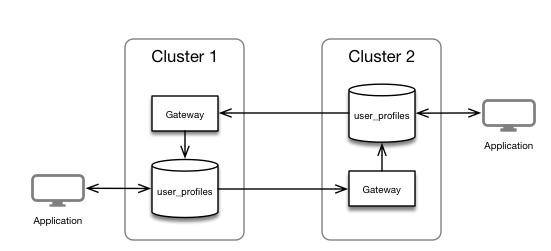
Конфигурирование кластеров
Каждый узел исходного кластера должен взаимодействовать с узлами CLDB целевого кластера. На каждом узле исходного кластера отредактируйте файл mapr-clusters.conf и добавьте информацию о целевом кластере.
Конфигурация кластера 1
Во всех узлах cluster1 отредактируйте файл /opt/mapr/conf/mapr-clusters.conf и добавьте конфигурацию cluster2 . Файл должен выглядеть следующим образом:
|
1
2
3
|
cluster1 secure=false cluster1-node1:7222 cluster1-node2:7222 cluster1-node2:7222cluster2 secure=false cluster2-node1:7222 cluster2-node2:7222 cluster2-node3:7222 |
Конфигурация кластера 2
Во всех узлах cluster2 отредактируйте файл /opt/mapr/conf/mapr-clusters.conf и добавьте конфигурацию cluster1 . Файл должен выглядеть следующим образом:
|
1
2
3
|
cluster2 secure=false cluster2-node1:7222 cluster2-node2:7222 cluster2-node3:7222cluster1 secure=false cluster1-node1:7222 cluster1-node2:7222 cluster1-node2:7222 |
Вы можете найти информацию о формате mapr-clusters.conf в документации .
Откройте окно терминала на одном из узлов mapr с mapr пользователя mapr и выполните следующие действия:
|
1
2
3
4
5
|
$ ls /mapr/cluster1/apps hbase installer opt tmp user var$ ls /mapr/cluster2/apps hbase installer opt tmp user var |
Установка и настройка шлюза MapR
Шлюз MapR обеспечивает одностороннюю связь между исходным кластером MapR и целевым кластером MapR. В этом примере вы будете использовать репликацию с cluster1 cluster2 , это означает, что данные будут реплицироваться из cluster1 в cluster2 и из cluster2 в cluster1 .
Хорошей практикой является установка MapR-Gateway в целевой кластер, поэтому в нашем случае давайте установим один шлюз на один из узлов cluster1 и один шлюз на один из узлов cluster2 . Обратите внимание, что эта конфигурация не будет высокой доступности, и обычно вы будете развертывать более 1 шлюза по кластеру.
Установка MapR-шлюза
Как пользователь root на одном узле cluster1 , адаптируйте команду к вашей среде linux, например, для узла cluster1-node2
|
1
2
3
4
5
|
$ yum install mapr-gateway# Update MapR configuration$ /opt/mapr/server/configure.sh -N cluster1 -C cluster1-node1:7222,cluster1-node2:7222,cluster1-node3:7222 -R |
Сделайте то же самое для cluster2 , например, для узла cluster2-node2 :
|
1
2
3
4
5
|
$ yum install mapr-gateway# Update MapR configuration$ /opt/mapr/server/configure.sh -N cluster1 -C cluster2-node1:7222,cluster2-node2:7222,cluster2-node3:7222 -R |
Регистрация шлюза в кластеры
Теперь, когда у нас есть шлюз, работающий на каждом кластере, вы должны зарегистрировать шлюз в каждом кластере.
На cluster1 выполните следующую команду, чтобы зарегистрировать шлюз cluster2 качестве пункта назначения:
|
1
2
3
4
|
$ maprcli cluster gateway set -dstcluster cluster2 -gateways cluster2-node2# Check the configuration$ maprcli cluster gateway list |
На cluster2 выполните следующую команду, чтобы зарегистрировать шлюз cluster1 качестве пункта назначения:
|
1
2
3
4
|
$ maprcli cluster gateway set -dstcluster cluster1 -gateways cluster1-node2# Check the configuration$ maprcli cluster gateway list |
Создание таблицы с репликацией
В окне терминала, как пользователь mapr на cluster1 , создайте таблицу и вставьте документы:
|
1
|
$ maprcli table create -path /apps/user_profiles -tabletype json |
Это создаст новую таблицу JSON; также можно использовать /mapr/cluster1/apps/user_profiles .
Теперь давайте добавим документы с помощью MapR-DB Shell:
|
1
2
3
4
5
|
$ mapr dbshellmaprdb mapr:> insert /apps/user_profiles --value '{"_id":"user001" , "first_name":"John", "last_name":"Doe"}'maprdb mapr:> find /apps/user_profiles |
Добавление репликации таблицы
Теперь user_profiles cluster1 репликацию между user_profiles на cluster1 в таблицу cluster2 в cluster2 .
В cluster1 в окне терминала от имени mapr выполните следующую команду:
|
1
|
$ maprcli table replica autosetup -path /apps/user_profiles -replica /mapr/cluster2/apps/user_profiles -multimaster yes |
Вы можете получить информацию о конфигурации репликации для таблицы, используя следующую команду:
|
1
|
$ maprcli table replica list -path /apps/user_profiles -json |
Тестирование репликации
Откройте другой терминал в cluster2 и используйте MapR-DB Shell для просмотра реплицированных данных:
|
1
2
3
4
5
|
$ mapr dbshellmaprdb mapr:> find /apps/user_profiles{"_id":"user001","first_name":"John","last_name":"Doe"}1 document(s) found. |
Вы также можете использовать полный путь /mapr/cluster2/apps/user_profiles
В cluster1 добавьте новый документ с помощью MapR-DB Shell:
|
1
2
3
4
5
|
$ mapr dbshellmaprdb mapr:> insert /apps/user_profiles --value '{"_id":"user002" , "first_name":"Simon", "last_name":"Dupont"}'maprdb mapr:> find /apps/user_profiles |
Сделайте поиск в таблице cluster2 , и вы увидите, что данные были реплицированы.
Вы можете вставить или удалить документ в cluster2 и сделать поиск в cluster1 , вы увидите, что новый документ также реплицируется в другом направлении.
Обратите внимание, что для этой демонстрации мы используем 2 терминала, подключенных к каждому кластеру, которые вы можете провести в тесте, используя глобальное пространство имен в одной оболочке MapR-DB.
Вывод
Из этого руководства вы узнали, как настроить репликацию Map-Multi-Master для автоматической репликации данных между двумя кластерами.
MapR-DB Table Replication предоставляет множество опций, не только с точки зрения топологии (master-slave / mult-master), но также некоторые опции и команды для:
- реплицировать некоторые столбцы / атрибуты или семейство столбцов
- настроить репликацию в защищенном кластере
- пауза репликации.
Вы можете найти больше информации о репликации таблиц MapR-DB и MapR-Gateway в документации:
| Ссылка: | Начало работы с MapR-DB Table Replication от нашего партнера по JCG Тугдуала Граля в блоге Tug’s Blog . |