Сообщество Apache Hadoop предоставило нам отличный набор инструментов, которые позволяют нам взаимодействовать с распределенной файловой системой Hadoop. Эти инструменты запутывают сложности множества машин в фоновом режиме, показывая нам один простой и понятный интерфейс.
Отличным инструментом для начала работы с Hadoop является hadoop fs . Набор инструментов hadoop fs запускает пользовательский клиент общей файловой системы, который взаимодействует с распределенной файловой системой аналогично тому, как мы взаимодействуем с файловой системой Unix (но с очень ограниченным набором команд). Можно перечислять, изменять разрешения, перемещать, копировать и выполнять другие операции с файлами и каталогами в распределенной файловой системе. Полный список команд hadoop fs можно найти на сайте hadoop.apache.org.
Однако, поскольку HDFS является файловой системой только для чтения, а поскольку набор инструментов hadoop fs был создан для HDFS, невозможно найти какие-либо инструменты для редактирования файлов, такие как vim или nano. Чтобы редактировать файлы в стиле Linux, MapR предоставляет NFS- доступ к файловой системе MapR, так что все команды Unix могут использоваться в Hadoop 1 . Если вы заинтересованы в понимании важности и различий между файловой системой чтения / записи MapR и файловой системой HDFS только для чтения, прочтите это сообщение в блоге .
1 еще один отличный пост в блоге, объясняющий MapR NFS
Введение в MapRCLI
В дополнение ко всем командам оболочки Hadoop MapR предоставляет полностью дополняющий набор инструментов, основанный на Hadoop, чтобы дать вам гораздо больше возможностей и понимания файловой системы MapR. Эти инструменты невероятно полезны для администраторов, работающих с кластером Hadoop, а также для разработчиков, пытающихся отлаживать приложения Hadoop. В этом посте (Введение в интерфейс командной строки MapR) я представлю команду списка узлов maprcli и расскажу, как ее использовать, чтобы узнать больше о вашем кластере. В следующих статьях блога я расскажу, как использовать maprcli для работы с томами и пулами хранения MapR, списками контроля доступа MapR и многим другим!
Список узлов MapR CLI
Первое, что нужно сделать в существующем кластере, это посмотреть, сколько узлов вы работаете, выяснить, какие службы работают в кластере, и выяснить, где расположены эти службы. Maprcli позволяет вам увидеть это и МНОГО дополнительной информации, относящейся ко всем узлам в кластере. Попробуйте сами, запустив:
|
1
|
$ maprcli node list |
Вот как будет выглядеть вывод:
На самом деле, если бы вы попробовали команду, вы бы увидели, что объем выводимой информации слишком велик для усвоения. Другой подход — вернуть данные в формате JSON, просто запустив:
|
1
|
$ maprcli node list -json |
Вот как будет выглядеть вывод:
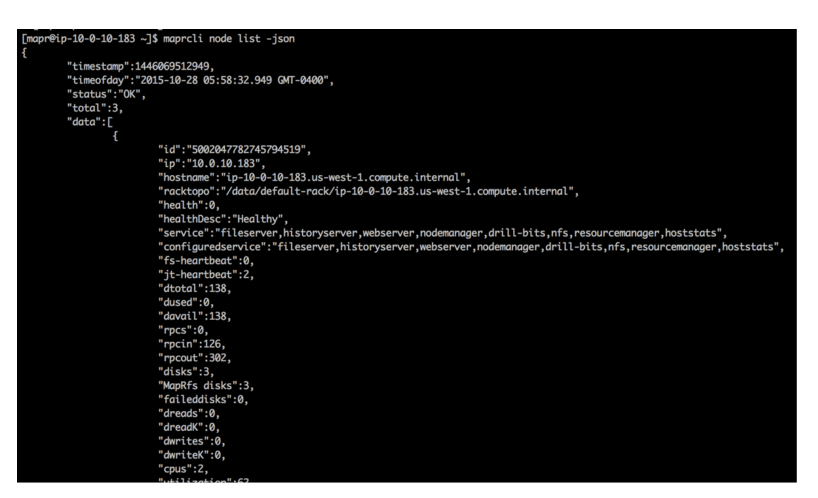
Это выглядит намного лучше, но если вы не пытаетесь провести полный аудит, все равно слишком много информации, и будет очень трудно найти какие-то конкретные вещи, которые вы можете искать. Чтобы отточить конкретную информацию, вы можете передать аргумент «-columns» и указать ключ (имена столбцов) для нужных вам данных. По умолчанию возвращаются имя хоста и IP-адрес узлов, но если вы хотите увидеть, что представляют собой службы в кластере, попробуйте следующее:
|
1
|
$ maprcli node list -columns service |

Это невероятно полезно, так как теперь мы знаем, над чем работаем в нашем кластере. Команда сообщает нам, сколько именно узлов запущено, какие службы запущены на каждом узле, а также имя хоста и IP-адреса, связанные с каждым узлом. Как насчет остальной информации? Как вы можете использовать остальную часть возможной информации, которую вы даже не знаете, существует? Чтобы сделать это, просто перечислите имена столбцов всей информации, которую эта команда может вывести для каждого узла, выполнив:
|
1
|
for f in `maprcli node list | head -1`; do echo $f; done | sort |
Теперь, когда вы знаете, где находится каждый сервис, вы можете управлять каждым из них, используя один и тот же инструмент с разными аргументами. Одна из причин, по которой вам может потребоваться остановить / запустить службы, заключается в том, что новые изменения конфигурации могут вступить в силу. Например, если вы запускаете задания Spark, которым требуется больше памяти, чем выделенной памяти по умолчанию, вы можете изменить «yarn.scheduler. максимум-выделения-мб »в файле yarn-site.xml. Чтобы YARN узнал новую конфигурацию, необходимо перезапустить Resource Manager следующим образом:
|
1
2
|
maprcli node services -name resourcemanager -action stop -nodes <space separated RM hostnames> |
Убедитесь, что сервисы больше не работают:
|
1
|
maprcli node list -columns service |
И снова запустите менеджер ресурсов:
|
1
2
|
maprcli node services -name resourcemanager -action start -nodes <space separated RM hostnames> |
Точно так же вы можете просто заменить начальный «стоп» на «рестарт».
Поиграйте с этим инструментом. Есть множество других параметров и аргументов, которые вы можете предоставить этой команде, чтобы получить много новой информации, которую вы не могли получить.
В следующей записи блога мы расскажем, как создавать тома MapR, как устанавливать специфичные для тома характеристики, такие как коэффициенты репликации, квоты и разрешения, и как их легко использовать для HA и аварийного восстановления.
Если у вас есть какие-либо вопросы об использовании командной строки MapR, пожалуйста, задавайте их в разделе комментариев ниже.
| Ссылка: | Начало работы с командной строкой MapR (часть I) от нашего партнера по JCG Нельсона Эстрады в блоге Mapr . |