Основная цель Nextflow — сделать рабочие процессы переносимыми между различными вычислительными платформами, используя преимущества функций распараллеливания, предоставляемых базовой системой, без необходимости повторной реализации кода приложения.
С самого начала в Nextflow были включены исполнители, предназначенные для работы с наиболее популярными менеджерами ресурсов и планировщиками пакетов , обычно используемыми в центрах обработки данных HPC, такими как Univa Grid Engine , платформа LSF , SLURM , PBS и Torque .
При использовании одного из этих исполнителей Nextflow отправляет задачи вычислительного рабочего процесса как независимые запросы задания в планировщик базовой платформы, указывая для каждого из них вычислительные ресурсы, необходимые для выполнения своей работы.
Этот подход хорошо работает для рабочих процессов, которые состоят из длительных задач, что имеет место в большинстве распространенных геномных конвейеров.
Однако этот подход плохо масштабируется для рабочих нагрузок, состоящих из большого числа недолговечных задач (например, несколько секунд или субсекунд). В этом сценарии время планирования менеджера ресурсов намного больше, чем фактическое время выполнения задачи, что приводит к общему времени выполнения, которое намного превышает реальное время выполнения. В некоторых случаях это представляет собой недопустимую трату вычислительных ресурсов.
Кроме того, суперкомпьютеры, такие как MareNostrum в Барселонском суперкомпьютерном центре (BSC) , оптимизированы для приложений с распределенной памятью. В этом контексте необходимо заранее выделить определенное количество вычислительных ресурсов для распределенного запуска приложения, обычно с использованием стандарта MPI .
В этом сценарии модель выполнения Nextflow была далека от оптимальной, если не невозможной.
Распределенное выполнение
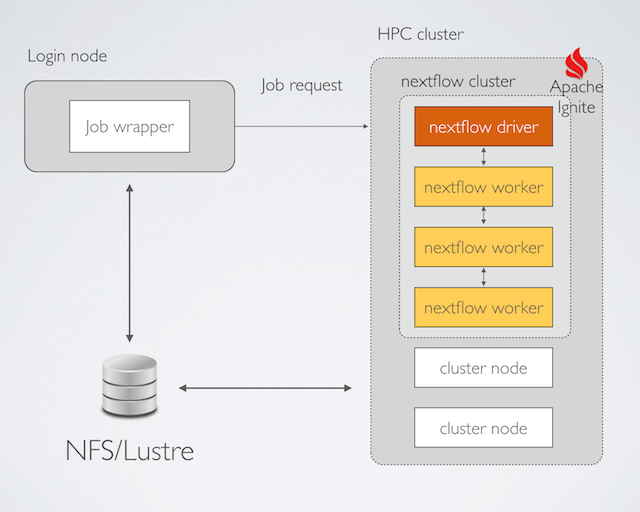
По этой причине, начиная с выпуска 0.16.0, Nextflow внедрил новую модель распределенного выполнения, которая значительно улучшает вычислительные возможности платформы. Он использует Apache Ignite , облегченный механизм кластеризации и сетку данных в памяти, которая была недавно открыта под эгидой программного обеспечения Apache.
При использовании этой функции приложение Nextflow запускается так, как если бы оно было приложением MPI. Он использует упаковщик заданий, который отправляет один запрос с указанием всех необходимых вычислительных ресурсов. Командная строка Nextflow выполняется с помощью mpirun утилиты, как показано в примере ниже:
#!/bin/bash
#$ -l virtual_free=120G
#$ -q <queue name>
#$ -N <job name>
#$ -pe ompi <nodes>
mpirun --pernode nextflow run <your-project-name> -with-mpi [pipeline parameters]
Этот инструмент порождает экземпляр Nextflow в каждом из вычислительных узлов, выделенных администратором кластера.
Каждый экземпляр Nextflow автоматически соединяется с другими одноранговыми узлами, создавая частный внутренний кластер, благодаря функции кластеризации Apache Ignite, встроенной в сам Nextflow.
Первый узел становится драйвером приложения, который управляет выполнением приложения рабочего процесса, отправляя задачи остальным узлам, которые действуют как рабочие.
Когда приложение завершено, драйвер Nextflow автоматически завершает работу кластера Nextflow / Ignite и завершает выполнение задания.
Вывод
Таким образом, можно развернуть рабочую нагрузку Nextflow в суперкомпьютере, используя стратегию выполнения, которая напоминает модель распределенного выполнения MPI. Это не требует реализации вашего приложения с использованием API / библиотеки MPI и позволяет поддерживать переносимость кода на разных платформах исполнения.
Хотя в настоящее время у нас нет сравнения производительности между распределенным исполнением Nextflow и эквивалентным приложением MPI, мы предполагаем, что последнее обеспечивает лучшую производительность благодаря низкоуровневой оптимизации.
Nextflow, однако, фокусируется на быстром прототипировании научных приложений в переносимой форме, сохраняя при этом возможность эффективного масштабирования и распределения рабочей нагрузки приложений в кластере HPC.
Это позволяет исследователям быстро провести эксперимент, повторно используя существующие инструменты и программные компоненты. Это в конечном итоге позволяет реализовать оптимизированную версию с использованием низкоуровневого языка программирования на втором этапе проекта.