Современная комплексная обработка событий с открытым исходным кодом для IoT
В этой серии постов в блоге подробно рассказывается о моих выводах, когда я привожу в производство полностью современное представление о комплексной обработке событий, или сокращенно CEP. Во многих приложениях, от финансовых до розничных и IoT-приложений, огромное значение имеет автоматизация задач, требующих принятия мер в режиме реального времени. Оставляя в стороне ИТ-систему и фреймворки, которые поддерживают эту возможность, это, безусловно, полезная возможность.
В первом посте этой серии я объясняю, как CEP развивался для удовлетворения этого требования и как требования к CEP могут быть выполнены в современном контексте больших данных. Вкратце, я представляю подход, основанный на лучших практиках современной архитектуры, микросервисах и потоковом обмене сообщениями в стиле Кафки, с современным механизмом бизнес-правил с открытым исходным кодом.
Во второй части я получу более конкретный пример и проработаю рабочий пример, используя предложенную мной систему. Давайте начнем.
Smart City Traffic Monitoring
Мы сделали рабочую демонстрацию, для которой код будет выпущен на MapR GitHub. Он предназначен для работы либо в песочнице MapR, либо с использованием реального кластера MapR. Наше демо планируется выпустить, поэтому, пожалуйста, следите за обновлениями и проверьте www.mapr.com для объявления.
В этом примере мы будем использовать очень простой вариант «умного города» для мониторинга трафика. В этом случае мы смоделируем один датчик, который может измерять скорость проезжающих на нем автомобилей. Используя такие данные датчиков, было бы довольно легко обнаружить пробки в режиме реального времени и, таким образом, уведомить полицию о необходимости принять меры намного быстрее, чем они могли бы в противном случае.
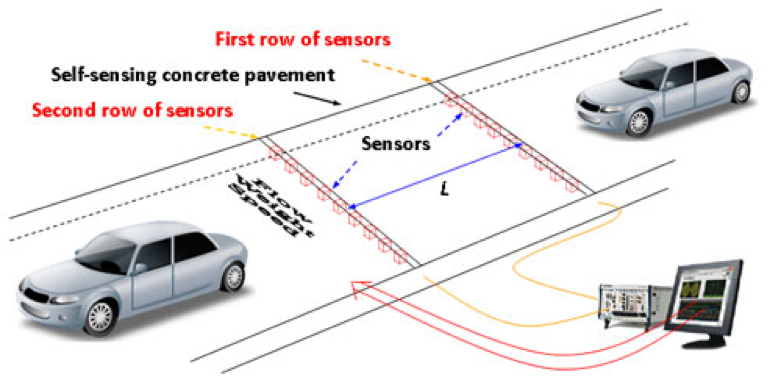
Некоторые другие типы случаев использования легко представить. Мы можем добавлять данные из общедоступной информации о погоде в режиме реального времени, подключаться к информационным панелям вдоль дорог и показывать рекомендации водителям без вмешательства человека. Комбинируя датчики состояния дороги с данными о погоде, мы можем предоставить консультативную обратную связь водителям о состоянии дороги и очень быстро предупредить население. Кроме того, добавляя исторические данные об авариях и используя прогнозную аналитику, мы можем представить меры безопасности дорожного движения, которые могут быть развернуты в реальном времени в районах с более высокой вероятностью аварий.
Честно говоря, я лишь поверхностно рассуждаю о том, что может сделать эта умная дорога, чтобы сделать пригородную жизнь проще и безопаснее, экономя при этом деньги для города. Но как бы мы создали прототип такой системы, если бы она не была чрезвычайно сложной и дорогой?
Как построить систему CEP на основе правил
Так что теперь у нас есть правильная, конкретная цель. Оказывается, что если мы решим основывать нашу систему на чтении наших данных из потока в стиле Кафки (т. Е. Постоянного, масштабируемого и высокопроизводительного), то мы, естественно, получим довольно крутой современный микросервис CEP.
Важным моментом здесь является не демонстрация того, как построить сверхсложную корпоративную архитектуру, а то, что, сделав несколько простых технологических решений и построив нашу демонстрацию разумным способом, мы естественным образом получим эту элегантную, современную и простую архитектуру .
Для простоты я решил реализовать свой прототип в песочнице MapR ( бесплатно его можно найти здесь ). Это связано с тем, что она будет включать систему потоковых сообщений MapR Streams, которую я могу использовать через API Kafka 0.9 с очень небольшой конфигурацией и знаю, что она будет работать так же в производственном кластере MapR 5.1+.
Наконец, следует отметить, что кластер Apache Kafka можно использовать также с тем же дизайном и кодом, просто с некоторой дополнительной работой для его запуска и работы.
Вид архитектуры высокого уровня

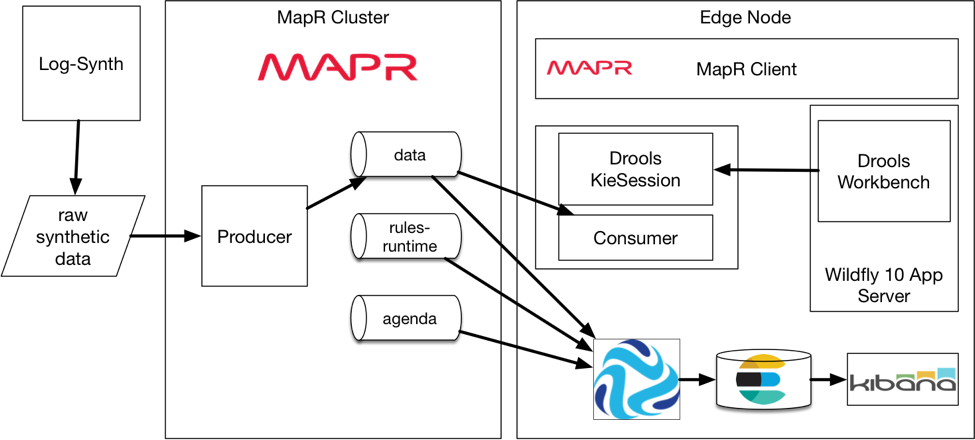
Как показано на приведенной выше схеме, поток данных агрегируется в шлюз производителя, который перенаправляет данные в поток с темой, названной «data». Данные будут в формате JSON, поэтому им легко манипулировать, они удобочитаемы и легко отправляются в Elasticsearch как есть для мониторинга с помощью панели управления Kibana.
У потребителя будет две задачи: прочитать данные из потока и разместить экземпляр KieSession, где механизм правил может применять правила к фактам по мере их добавления к нему.
Правила редактируются в графическом интерфейсе Workbench, веб-приложении Java, которое можно запустить на сервере приложений Java, таком как WildFly или Tomcat .
Правила извлекаются из рабочей среды пользовательским приложением с использованием соответствующих методов, предоставляемых средой Drools, которые полностью основаны на репозитории Maven.
Теперь мы можем более подробно рассмотреть предлагаемую систему в следующих разделах.
Список используемых технологий
Технология, которую мы собираемся использовать, выглядит следующим образом:
- MapR Sandbox 5.2
- Язык программирования Java (подойдет любой язык JVM)
- Библиотека Джексона 2 для преобразования в и из JSON
- MapR Streams или система обмена сообщениями Apache Kafka
- Сервер приложений Wildfly 10 для размещения Workbench
- JBoss Drools как наш выбор двигателя бизнес-правил OSS
- Log Synth для генерации синтетических данных для нашего прототипа
- Streamsets 1.6 для подключения MapR Streams и Elasticsearch
- Elasticsearch 2.4 и Kibana 4 для мониторинга
Архитектура прототипа мониторинга трафика
Когда я создавал эту демонстрацию для запуска в песочнице MapR, я использую инструкции для CentOS 6.X, версии RHEL 6.X с открытым исходным кодом. Инструкции для CentOS 7 практически идентичны, и найти похожие инструкции для Ubuntu было бы довольно просто и оставлено на усмотрение читателя.
Чтобы построить ядро системы мониторинга трафика, нам понадобятся две основные части:
- Программа для подачи данных датчика в MapR Streams / Kafka. Эта часть будет использовать поддельные данные, смоделированные с помощью симулятора транспортного средства, закодированного с помощью Log Synth. Мы будем использовать реализацию прокси MapR Kafka-rest (только что представленную в MEP 2.0) для добавления данных с помощью Python.
- Приложение на языке JVM, которое будет считывать данные из потока и передавать их в KieSession. Минимальный код для этой работы удивительно мал.
Чтобы отредактировать правила, мы развернем Workbench на Wildfly 10, что является довольно простым процессом. Посмотрите этот пост в блоге для получения инструкций или прочитайте документацию Drools. Установить Wildfly довольно просто; В этом блоге вы найдете отличные инструкции о том, как установить его как сервис на Centos / RHEL (это для Wildfly, но те же инструкции работают для 9 и 10).
Мы сделали одно изменение конфигурации для Wildfly. Мы изменили порт на 28080 вместо 8080, так как он уже используется в песочнице. Wildfly работает в автономном режиме, поэтому файл конфигурации находится в WILDFLY_HOME / standalone / configuration / standalone.xml.
Для мониторинга мы позволяем потоковой архитектуре работать на нас. Мы используем сборщик данных Streamset с открытым исходным кодом, чтобы легко перенаправить данные датчика в Elasticsearch, чтобы мы могли реально контролировать систему с помощью красивой панели инструментов с Kibana. Для настройки Streamsets с помощью MapR Streams требуется некоторая работа с версией 1.6 ( отличный пост в блоге об этом здесь или из официальной документации Streamsets ).
Наконец, установка и настройка Elasticsearch и Kibana хорошо документирована в Centos / RHEL .
Для производства все эти части могут быть легко разделены для запуска на отдельных серверах. Их можно запускать либо на узлах кластера, либо на пограничных узлах. Если это кластер MapR, то установка клиента MapR и указание его на узлы CLDB кластера будут всей конфигурацией, необходимой для полного доступа к потокам. Для кластера Apache Kafka обратитесь к официальной документации Kafka .
Прототип мониторинга трафика — Как
Создание потоков с помощью maprcli
Первая задача — создать потоки и темы для нашего приложения. Для этого рекомендуется сначала создать том для потоков. В качестве пользователя mapr введите из командной строки:
|
1
2
3
4
5
6
7
8
9
|
maprcli volume create -name streams -path /streamsmaprcli stream create -path /streams/traffic -produceperm p -consumerperm pmaprcli stream topic create -path /streams/traffic -topic datamaprcli stream topic create -path /streams/traffic -topic agendamaprcli stream topic create -path /streams/traffic -topic rule-runtime |
Примечание: MapR Streams — это больше надмножество Kafka, чем просто клон. Помимо ускорения MapR Streams может использовать все преимущества файловой системы MapR , такие как тома (с разрешениями, квотами и т. Д.) И репликацией. Кластер не ограничивается определением тем, но может определять несколько потоков, каждый из которых может иметь несколько тем. Поэтому вместо имени темы поток MapR имеет путь: обозначение темы. Здесь полное название нашего потока данных — «/ streams / traffic: data». Вы можете прочитать больше о преимуществах MapR Streams и Kafka в этом пошаговом руководстве Джима Скотта .
Генерация поддельных данных
Я использовал инструмент Log-Synth для генерации данных для этого прототипа. Log-Synth использует схему в сочетании с классом Sampler для создания данных очень гибким и простым способом.
Моя схема:
|
1
2
3
4
|
[{"name":"traffic", "class":"cars", "speed": "70 kph", "variance": "10 kph", "arrival": "25/min", "sensors": {"locations":[1, 2, 3, 4, 5, 6, 7,8,9,10], "unit":"km"},"slowdown":[{"speed":"11 kph", "location":"2.9 km - 5.1 km", "time": "5min - 60min"}]}] |
Команда для генерации данных:
|
1
|
synth -count 10K -schema my-schema.json >> output.json |
Данные генерируются по одной машине за раз, и каждая точка данных представляет собой показание датчика. Данные будут моделировать поток автомобилей, движущихся со скоростью 70 км / ч со скоростью 25 автомобилей в минуту. Замедление произойдет между 2,9 и 5,1 км, где скорость будет снижена до 11 км / ч через 5–60 минут после начала симуляции. Это будет пробка, которую мы хотим обнаружить с помощью нашей системы CEP.
Сгенерированные данные — это файл, в котором каждая строка представляет собой итоговый список измерений датчиков для одного автомобиля:
|
1
|
[{"id":"s01-b648b87c-848d131","time":52.565782936267404,"speed":19.62484385513174},{"id":"s02-4ec04b36-2dc4a6c0","time":103.5216023752337,"speed":19.62484385513174},{"id":"s03-e06eb821-cda86389","time":154.4774218142,"speed":19.62484385513174},{"id":"s04-c44b23f0-3f3e0b9e","time":205.43324125316627,"speed":19.62484385513174},{"id":"s05-f57b9004-9f884721","time":256.38906069213255,"speed":19.62484385513174},{"id":"s06-567ebda7-f3d1013b","time":307.3448801310988,"speed":19.62484385513174},{"id":"s07-3dd6ca94-81ca8132","time":358.3006995700651,"speed":19.62484385513174},{"id":"s08-2d1ca66f-65696817","time":409.25651900903136,"speed":19.62484385513174},{"id":"s09-d3eded13-cf6294d6","time":460.21233844799764,"speed":19.62484385513174},{"id":"s0a-1cbe97e8-3fc279c0","time":511.1681578869639,"speed":19.62484385513174}] |
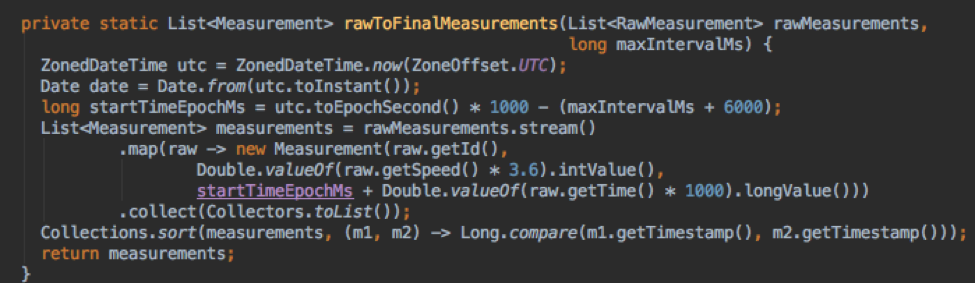
Показание имеет идентификатор датчика, скорость в метрах в секунду и дельту времени от времени 0 (момент начала моделирования) в секундах.
Мой код производителя просто переводит показания в список показаний датчиков, упорядоченных по времени, и я преобразую скорость в км / с, а время в метку времени в миллисекундах с начала эпохи.
Отправка кода в поток может выполняться по одной строке за раз с использованием стандартного кода производителя. Код в образце Java-производителя работает просто отлично.
Еще одна интересная новая возможность — использовать совершенно новый Kafka Rest Proxy , который также доступен на MapR из MEP 2.0 (MapR Ecosystem Pack). Это означает, что датчики могут напрямую подключаться к Kafka с любого языка, поскольку REST API на основе HTTP является глобальным стандартом.
Использование Workbench
Мы можем войти в Workbench и войти с правами администратора (пользователя с ролью «admin»), созданного с помощью сценария add-user.sh от Wildfly.
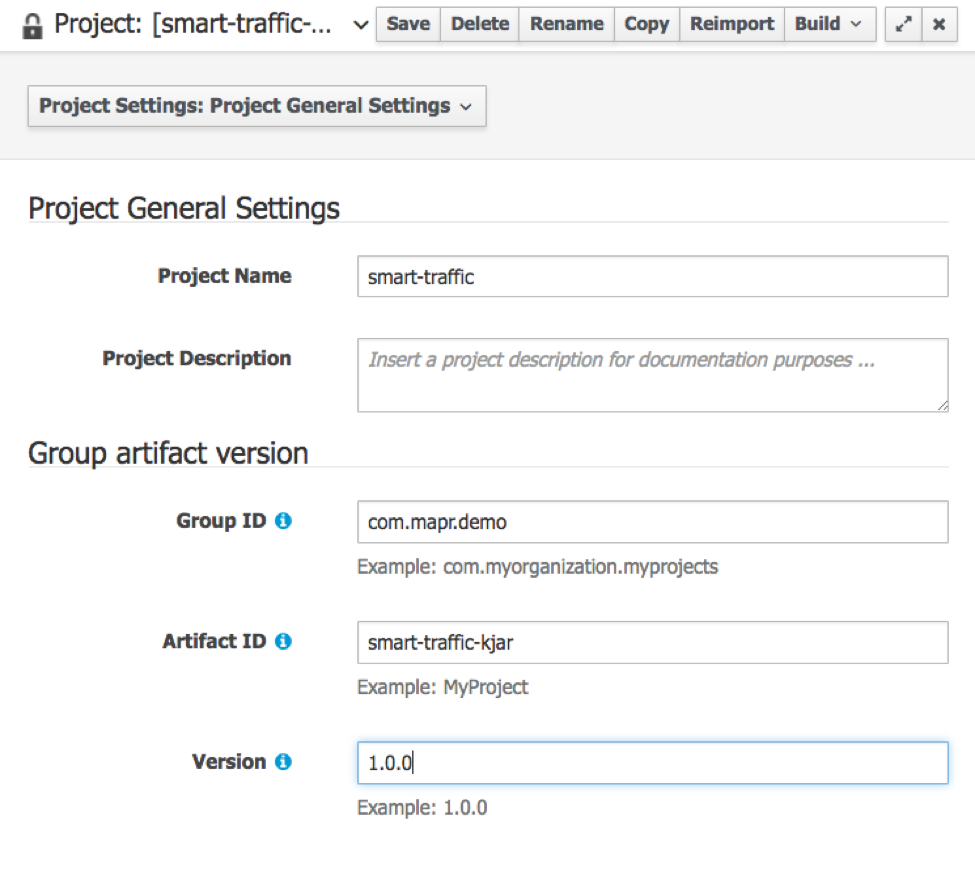
Использование Workbench выходит за рамки статьи, но общая идея состоит в том, чтобы создать организационную единицу и репозиторий, а затем создать проект.
Объекты данных
Нам нужно будет создать факты для работы с механизмом правил. Для Drools рекомендуется использовать отдельный проект Maven для вашей модели данных. Ради простоты я создал их прямо с верстака.
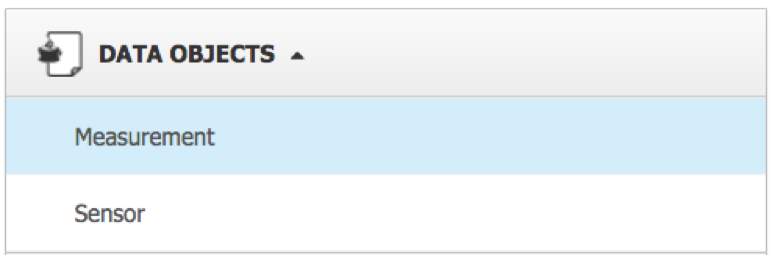
Измерение — это суперобобщенный компонент, который моделирует измерения скорости датчика. Для прототипа я сохранил его так же просто, как необработанные данные с отметкой времени, идентификатором датчика и скоростью.
Сен 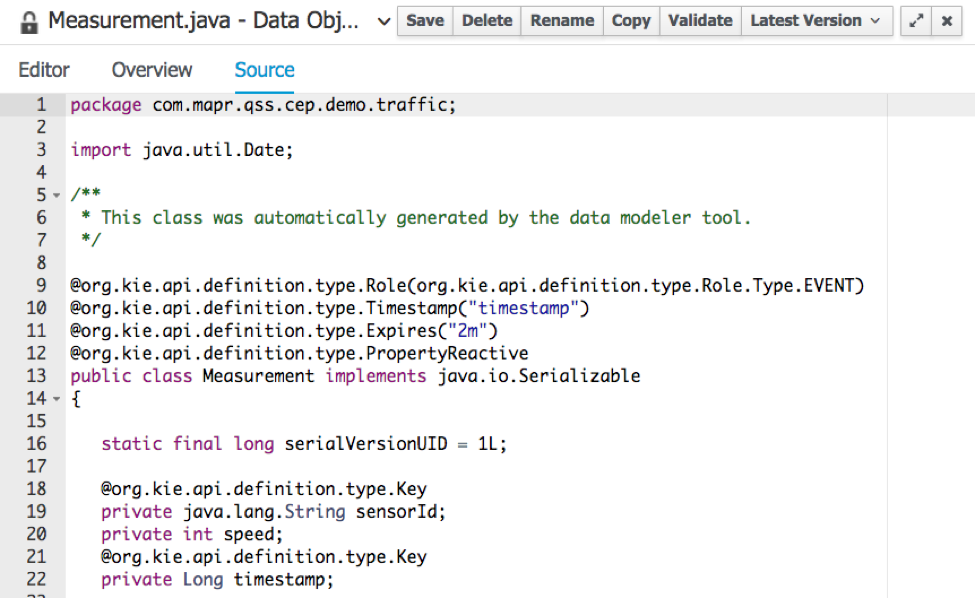 Компонент sor bean моделирует сам датчик и будет иметь идентификатор и среднюю скорость всех автомобилей, которые он измеряет за определенный промежуток времени, определенный нашими правилами. Эта средняя скорость будет использоваться для запуска оповещения для интенсивного движения. Строка трафика должна указывать текущий уровень трафика, который может быть «НЕТ», «СВЕТ» или «ТЯЖЕЛЫЙ».
Компонент sor bean моделирует сам датчик и будет иметь идентификатор и среднюю скорость всех автомобилей, которые он измеряет за определенный промежуток времени, определенный нашими правилами. Эта средняя скорость будет использоваться для запуска оповещения для интенсивного движения. Строка трафика должна указывать текущий уровень трафика, который может быть «НЕТ», «СВЕТ» или «ТЯЖЕЛЫЙ».
 Правила мониторинга трафика
Правила мониторинга трафика
- создать датчики для нового идентификатора
- обнаружить интенсивный трафик
- обнаруживать светофор
- обнаружить нормальный трафик
- получить среднюю скорость на датчике
Правило создания датчиков гарантирует, что в памяти доступны объекты датчиков. Это факт, который мы используем, чтобы узнать среднюю скорость на определенном датчике.
Обнаружение интенсивного движения — это ключевое правило, которое мы хотим использовать для отправки тревоги в полицию, если на определенном датчике обнаружено интенсивное движение.
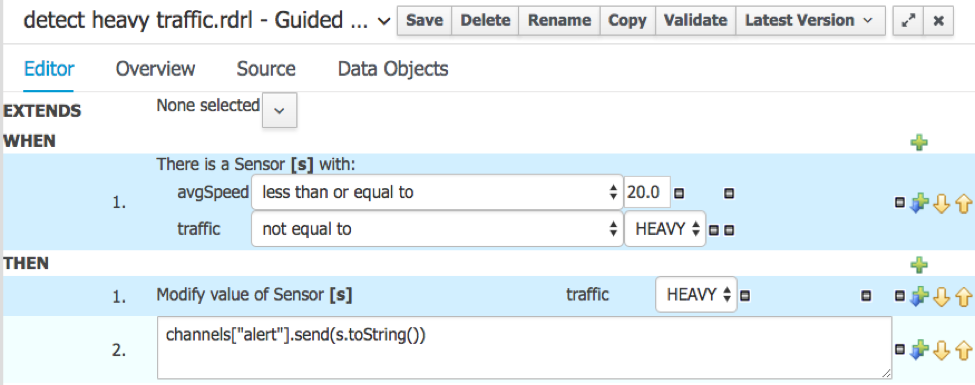
Поэтому, когда средняя скорость достигает 20 км / ч или менее, а датчик еще не находится в режиме интенсивного движения, установите уровень в положение HEAVY и отправьте предупреждение.
Это значит, что нам нужно знать среднюю скорость. Вот правило для его вычисления с использованием правила Drools DSL (предметно-ориентированный язык):
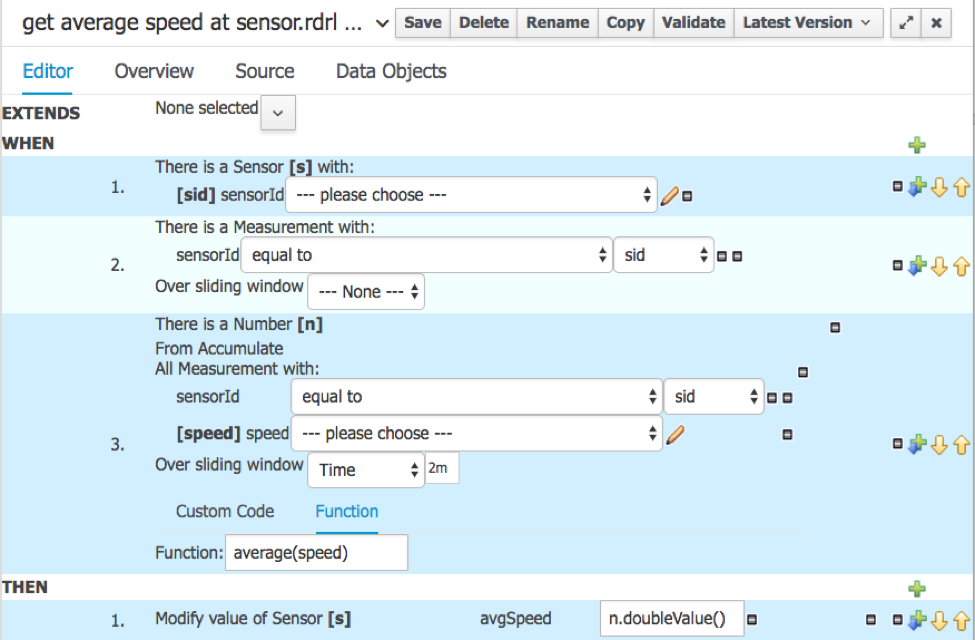
Это не ракетостроение! Эти правила довольно четко иллюстрируют, как составление простых, но полезных правил может быть реально оставлено на усмотрение бизнес-аналитиков и разработано отдельно от всего потока и платформы больших данных.
Потребительская сторона
Потребитель читает данные из потока. Учебный код на Java из документации вполне адекватен. Джексон используется для преобразования JSON в объекты Measurement.
У потребителя есть экземпляр KieSession, и каждое измерение добавляется к сеансу с использованием kieSession.insert (fact) и сопровождается вызовом kieSession.fireAllRules (), который запускает алгоритм, чтобы проверить, соответствуют ли какие-либо правила новому состоянию сессии с учетом новых данных.
Канал, который является просто обратным вызовом, используется, чтобы позволить правилу вызывать функцию «вне» KieSession. Мой прототип использует этот метод для регистрации оповещения. В производственной системе мы могли бы легко изменить код, чтобы отправить электронное письмо, SMS или предпринять другие действия.
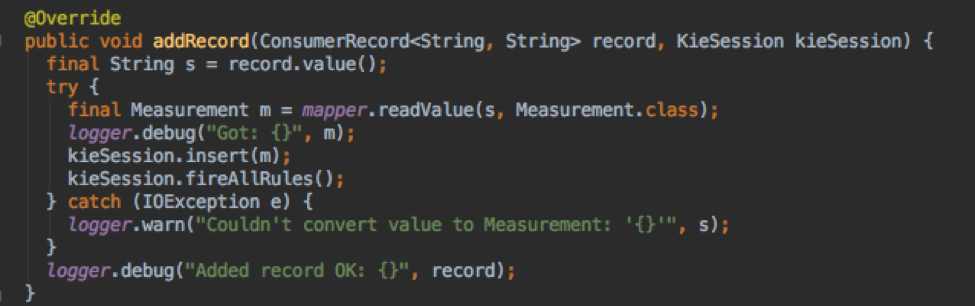
Импорт правил в потребительское приложение
Мы получаем правила для работающего приложения, выбирая его из репозитория Maven, интегрированного в Workbench.
|
1
2
3
4
5
|
KieServices kieServices = KieServices.Factory.get();ReleaseId releaseId = kieServices.newReleaseId( "org.mapr.demo", "smart-traffic-kjar", "1.0.0" );KieContainer kContainer = kieServices.newKieContainer( releaseId );KieSession kieSession = kContainer.newKieSession(); |
Таким образом, возникает вопрос, как вызов newReleaseId узнает, что нужно извлечь артефакт с нашими правилами из репозитория Maven в Workbench?
Ответ с файлом ~ / .m2 / settings.xml, куда вы добавляете эту информацию. Мы рекомендуем использовать пользователя mapr для всего в песочнице, поэтому полный путь: /home/mapr/.m2/settings.xml
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
[<a href="mailto:mapr@maprdemo">mapr@maprdemo</a> .m2]$ cat settings.xml<?xml version="1.0" encoding="UTF-8"?><settings><servers><server><id>guvnor-m2-repo</id><username>admin</username><password>admin</password></server></servers><profiles><profile><id>cep</id><repositories><repository><id>guvnor-m2-repo</id><name>Guvnor M2 Repo</name><url><strong><a href="http://127.0.0.1:28080/drools-wb-webapp/maven2/">http://127.0.0.1:28080/drools-wb-webapp/maven2/</a></strong></url><releases><enabled>true</enabled><updatePolicy>interval:1</updatePolicy></releases><snapshots><enabled>true</enabled><updatePolicy>interval:1</updatePolicy></snapshots></repository></repositories></profile></profiles><activeProfiles><activeProfile>cep</activeProfile></activeProfiles></settings> |
Основная информация выделена жирным шрифтом, что соответствует URL-адресу хранилища maven2 рабочей среды Drools. Эту информацию можно скопировать и вставить из файла pom.xml, который можно увидеть с помощью представления репозитория:
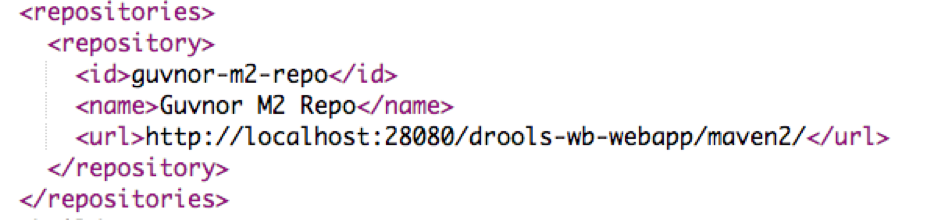
Так что я просто скопировал это, и теперь все работает как по волшебству.
Мониторинг прототипа Smart Traffic
У нас есть один поток с данными и два других потока для мониторинга внутренних компонентов механизма правил. Это очень легко с Drools, потому что он использует Слушатели Java, чтобы сообщить о своем внутреннем состоянии. Мы просто предоставляем настраиваемую реализацию слушателей для вывода данных в поток, а затем используем Streamsets, чтобы перенаправить всех в Elasticsearch.
Elasticsearch Mappings
Отображения определены в небольшом скрипте, который я создал:
Наборы потоков для потока без кода в Elasticsearch Pipeline
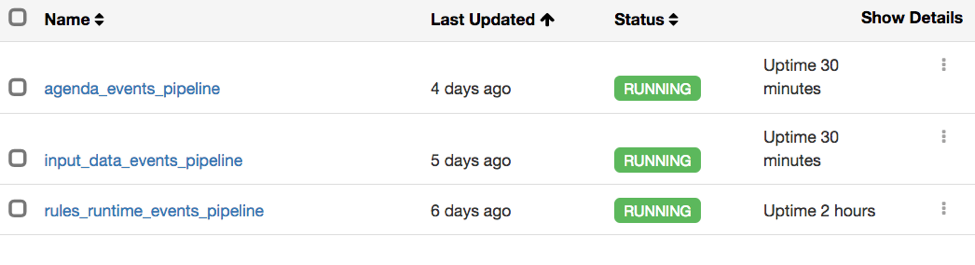
Каждый поток имеет свой собственный конвейер, где каждый выглядит так:
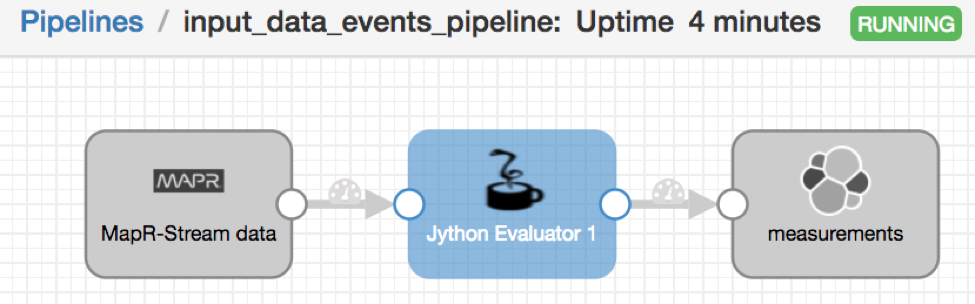
При необходимости Jython Evaluator добавляет информацию о метках времени.
Запуск прототипа
Начать потребителю:

Затем запустите производителя:

В моем прототипе я добавил код для управления скоростью, с которой данные отправляются в поток, чтобы упростить просмотр правил. 10 000 событий довольно малы для Drools и MapR Streams / Kafka, и поэтому вся демонстрация будет закончена менее чем за секунду. Это значение «-r 25» для 25 событий в секунду.
Приборная панель выглядит так:
Как только данные начинают поступать в:
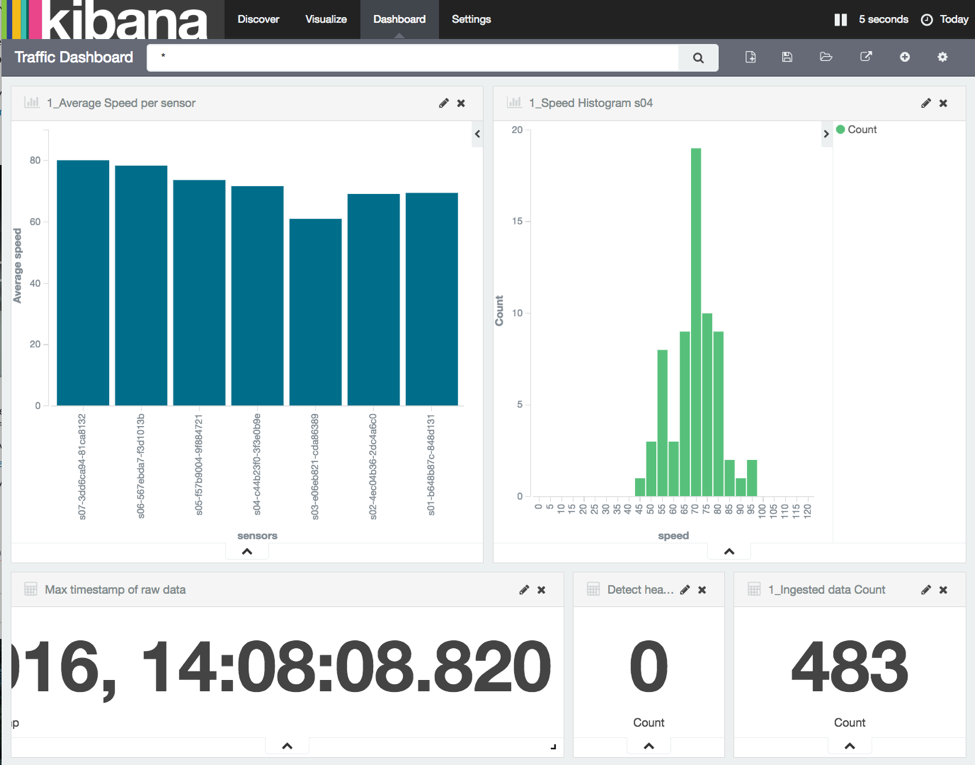
Пробка видна уже сейчас:
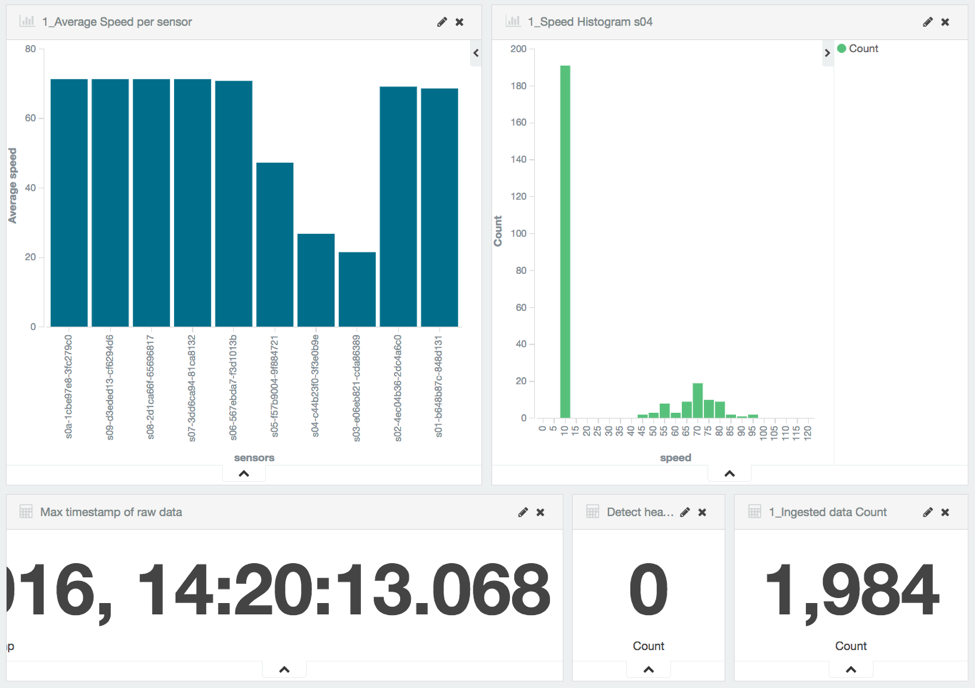
Как только средняя скорость датчика падает ниже 20 км / ч, срабатывает сигнал тревоги:

И приборная панель будет отображать счет «1»
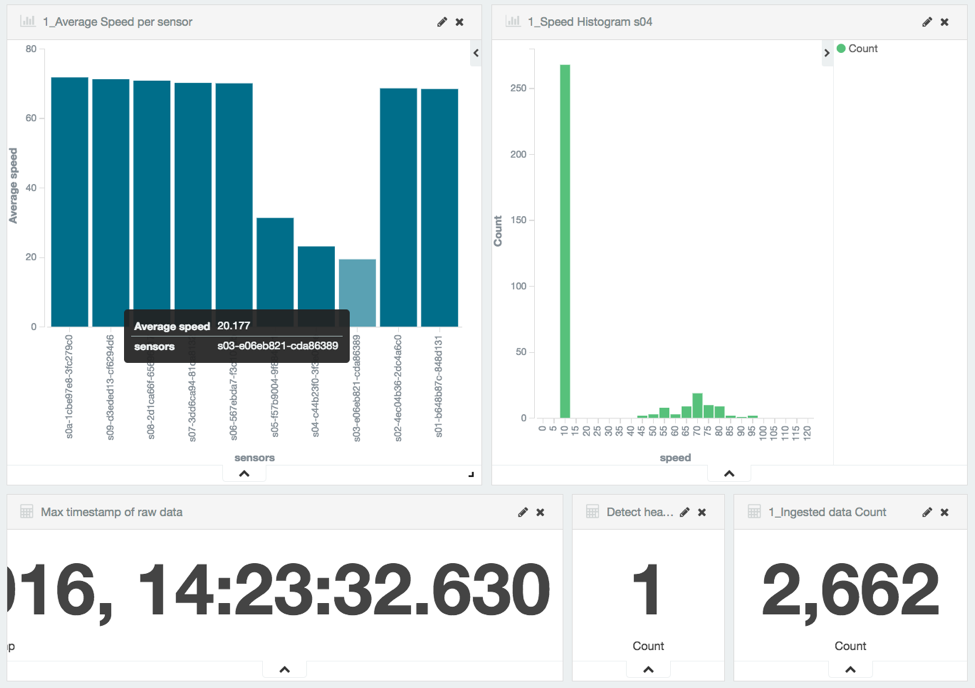
Моделирование будет продолжено, и два других датчика поочередно опустятся ниже 20, что в общей сложности приведет к срабатыванию 3 сигналов тревоги.
В заключении
Этот проект превратился в отличную иллюстрацию силы и простоты потоковой архитектуры с использованием микросервисов. Распространенным заблуждением о микросервисах является то, что они ограничены синхронными службами REST. Это совсем не так. Наша система является бэкэнд-системой, поэтому все микросервисы (производитель, потребитель, наборы потоков и ES / Kibana) работают асинхронно, обрабатывая данные по мере их поступления из потока.
Проект было довольно легко построить технически, потому что каждая часть полностью независима от других, и поэтому может быть протестирована в изоляции. Как только производитель может правильно отправлять данные в поток, его больше не нужно проверять на наличие проблем, касающихся других частей системы. Кроме того, каждая часть была добавлена по одной, что облегчает выявление проблем и их устранение.
В целом, с очень небольшим количеством оригинального кода, мы могли бы реализовать работающую, полезную систему, которая потребовала бы очень мало изменений, чтобы быть введенной в производство. Только производитель должен быть настроен для конкретного датчика или источника данных.
Правила — самая трудоемкая и подверженная ошибкам часть. Это ничем не отличается от того, если бы проект был выполнен с использованием пользовательского кода Spark. Выигрыш за подход, основанный на механизме правил, таком как Drools и Drools Workbench, заключается в том, что правила можно редактировать, тестировать и улучшать независимо от того, как код выполняется в кластере. Работа в Workbench вообще не зависит от системы, так как она автоматически загружается приложением-потребителем.
С точки зрения бизнес-ценности, вся ценность в правилах, при условии стабильной производственной системы. У организаций нет причин не использовать эту возможность быстрой редакции, чтобы стать еще более гибкими и реагирующими на изменяющиеся условия в интересах своих клиентов… и в итоге.
| Ссылка: | Мониторинг трафика Smart City в режиме реального времени с использованием потоковой архитектуры на основе микросервисов (часть 2) от нашего партнера по JCG Матье Дюмулена в блоге Mapr . |