Что означает «Масштаб» в контексте баз данных? Говоря о масштабировании, люди пришли к выводу, что:
- SQL не масштабируется
- Весы NoSQL
Совершенно очевидно, что производители NoSQL делают такие заявления . Также было интересно, что многие потребители NoSQL сделали такие заявления, даже если они, вероятно, перепутали SQL вообще с MySQL в частности . Затем они продолжают сравнивать MongoDB с масштабируемостью MySQL , что вполне понятно, поскольку MySQL для SQL — это то же, что MongoDB для NoSQL .
Давайте вернемся на землю …
… потому что в последние десятилетия не было ни одной базы данных, которая могла бы опередить Oracle по показателям Совета по эффективности обработки транзакций Мы верим, что сотрудники CERN приняли осознанное решение, когда выбрали Oracle Exadata и другие продукты Oracle для управления своими огромными данными еще до того, как огромные данные стали называть большими данными .
Итак, давайте сделаем быстрое сравнение. Недавно Влад Михалча написал в блоге о «молниеносной агрегации» (с MongoDB). Он взял набор данных из 50 миллионов записей в форме:
|
1
2
3
4
5
6
|
created_on | value-------------------------------------------2012-05-02T06:08:47Z | 0.92701931064948442012-09-06T22:40:25Z | 0.0053348918445408342012-06-15T05:58:22Z | 0.05611344985663891... | ... |
Это случайные метки времени и случайные числа. Затем он агрегировал эти данные с помощью следующего запроса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
var dataSet = db.randomData.aggregate([ { $group: { "_id": { "year" : { $year : "$created_on" }, "dayOfYear" : { $dayOfYear : "$created_on" } }, "count": { $sum: 1 }, "avg": { $avg: "$value" }, "min": { $min: "$value" }, "max": { $max: "$value" } } }, { $sort: { "_id.year" : 1, "_id.dayOfYear" : 1 } }]); |
И получил «ошеломляющий» результат агрегации молниеносной скорости:
Агрегация заняла: 129.052 с
129 секунд для таблицы среднего размера с 50M записями — это молниеносная скорость для MongoDB? Хорошо, подумали мы. Давайте попробуем это с Oracle. Влад любезно предоставил нам пример данных, которые мы импортировали в следующую тривиальную таблицу Oracle:
|
1
2
3
4
5
6
7
8
9
|
CREATE TABLESPACE aggregation_test DATAFILE 'aggregation_test.dbf' SIZE 2000M ONLINE;CREATE TABLE aggregation_test ( created_on TIMESTAMP NOT NULL, value NUMBER(22, 20) NOT NULL)TABLESPACE aggregation_test; |
Теперь давайте загрузим эти данные с помощью sqlldr в мой одноядерный лицензированный экземпляр Oracle XE 11gR2:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
OPTIONS(skip=1)LOAD DATA INFILE randomData.csv APPENDINTO TABLE aggregation_test FIELDS TERMINATED BY ','( created_on DATE "YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"", value TERMINATED BY WHITESPACE "to_number(ltrim(rtrim(replace(:value,'.',','))))") |
А потом:
|
1
2
3
4
5
6
7
8
|
C:\oraclexe\app\oracle\product\11.2.0\server\bin\sqlldr.exe userid=TEST/TEST control=randomData.txt log=randomData.log parallel=true silent=feedback bindsize=512000 direct=true |
Загрузка записей заняла некоторое время на моем компьютере со старым диском:
|
1
2
|
Elapsed time was: 00:03:07.70CPU time was: 00:01:09.82 |
Я мог бы настроить это так или иначе, так как SQL * Loader не самый быстрый инструмент для работы . Но давайте бросим вызов 129 для агрегации. Пока что мы не указали никакого индекса, но это не обязательно, поскольку мы агрегируем всю таблицу со всеми 50M записями. Давайте сделаем это с помощью следующего запроса к Владу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
SELECT EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), COUNT(*), AVG(value), MIN(value), MAX(value)FROM aggregation_testGROUP BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD')ORDER BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD') |
Это заняло 32 секунды на моей машине с очевидным полным сканированием таблицы. Не впечатляет Давайте попробуем другой запрос Влада, отфильтрованный за один час, который был выполнен за 209 мс в его тесте ( что, на наш взгляд, на самом деле совсем не быстро ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
var dataSet = db.randomData.aggregate([ { $match: { "created_on" : { $gte: fromDate, $lt : toDate } } }, { $group: { "_id": { "year" : { $year : "$created_on" }, "dayOfYear" : { $dayOfYear : "$created_on" }, "hour" : { $hour : "$created_on" } }, "count": { $sum: 1 }, "avg": { $avg: "$value" }, "min": { $min: "$value" }, "max": { $max: "$value" } } }, { $sort: { "_id.year" : 1, "_id.dayOfYear" : 1, "_id.hour" : 1 } }]); |
Влад сгенерировал случайную дату, которую он записал как
|
1
2
3
|
Aggregating from Mon Jul 16 2012 00:00:00 GMT+0300 to Mon Jul 16 2012 01:00:00 GMT+0300 |
Итак, давайте использовать точно такие же даты. Но сначала мы должны создать индекс для AGGREGATION_TEST(CREATED_ON) :
|
1
2
3
4
5
6
7
|
CREATE TABLESPACE aggregation_test_index DATAFILE 'aggregation_test_index1.dbf' SIZE 2000M ONLINE;CREATE INDEX idx_created_onON aggregation_test(created_on)TABLESPACE aggregation_test_index; |
ХОРОШО. Теперь давайте запустим Oracle-эквивалент запроса Влада (обратите внимание, в предложениях GROUP BY, SELECT, ORDER BY есть новый столбец):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
SELECT EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on), COUNT(*), AVG(value), MIN(value), MAX(value)FROM aggregation_testWHERE created_on BETWEEN TIMESTAMP '2012-07-16 00:00:00.0' AND TIMESTAMP '2012-07-16 01:00:00.0'GROUP BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on)ORDER BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on); |
Это заняло 20 секунд в первом запуске. Если честно, перед запуском этого утверждения я очистил некоторые кеши. Я полагаю, что MongoDB Влада уже «прогрелся» для второго запроса:
|
1
2
|
alter system flush shared_pool;alter system flush buffer_cache; |
Потому что, когда я снова запустил тот же запрос, потребовалось всего 0,02 секунды, чтобы включился буферный кеш Oracle, предотвращая фактический доступ к диску. Я мог бы настроить свой экземпляр Oracle таким образом, чтобы сохранить всю таблицу в памяти из первого запроса, в случае чего Oracle мог бы превзойти MongoDB на порядок.
Другой вариант — настроить индексацию. Давайте удалим наш существующий индекс и заменим его на «покрывающий» индекс как таковой:
|
1
2
3
4
5
|
DROP INDEX idx_created_on;CREATE INDEX idx_created_on_valueON aggregation_test(created_on, value)TABLESPACE aggregation_test_index; |
Давайте снова очистить кеш:
|
1
2
|
alter system flush shared_pool;alter system flush buffer_cache; |
И запустить запрос …
- Первое исполнение: 0.5 с
- Второе исполнение: 0,005 с
По плану выполнения теперь я могу сказать, что запросу больше не нужен доступ к таблице. Все соответствующие данные содержались в индексе:
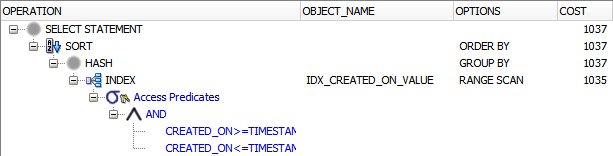
Теперь это начинает впечатлять, верно?
Итак, какой вывод мы можем сделать из этого?
Вот несколько выводов:
Не спешите с выводами
Прежде всего, мы должны быть осторожны с тем, чтобы делать какие-либо выводы вообще. Мы сравниваем яблоки с апельсинами. Мы даже сравнивали бы яблоки с апельсинами, сравнивая Oracle с SQL Server. Оба эталонных теста были написаны быстро, взломанные эталонные тесты, которые не представляют никаких продуктивных ситуаций. Уже сейчас мы можем сказать, что при агрегировании данных в таблице записей 50M нет существенного выигрыша, но Oracle, похоже, очень быстро работает лучше по сравнению с тестом дисков SSD (MongoDB) и HDD (Oracle)!
Честно говоря, мой компьютер имеет лучший процессор, чем у Влада:
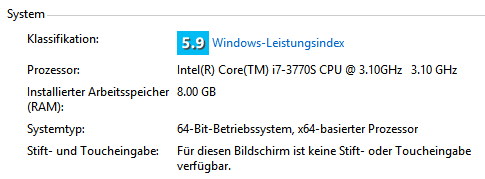
Мой компьютер
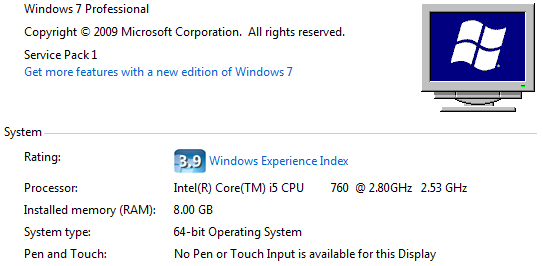
Компьютер влад
И SQL, и NoSQL могут масштабироваться
Большая часть дебатов о масштабировании NoSQL — это FUD. Люди всегда хотят верить поставщикам, которые говорят: «их продукт не делает то и это». Не покупайте это немедленно. Запустите небольшой тест, как указано выше, и убедитесь сами: масштабирование не является проблемой для баз данных SQL и NoSQL . Не будьте ослеплены первоначальным «медленным» выполнением Oracle. Oracle — очень сложная база данных, которая может настраиваться в соответствии с фактическими потребностями благодаря оптимизатору на основе затрат и статистике.
И ничто не мешает вам (и вашему администратору БД) использовать все функции вашего инструмента. В этом примере мы только поцарапали поверхность. Например, мы можем применить IOT (организованную по индексу таблицу) или секционирование таблицы, если вы используете Oracle Enterprise Edition.
50M не большие данные
ЦЕРН имеет большие данные. Google делает. Facebook делает. Вы не 50M — это не «большие данные». Это просто ваша средняя таблица базы данных.
200 мс не быстро
Очевидно, что вам может быть наплевать, сколько времени потребуется для подготовки автономного отчета на выделенном сервере пакетных отчетов. Но если у вас есть реальный пользователь в реальном интерфейсе, ожидающий его … Если они это сделают, 200 мс не быстро, потому что они могут выполнять 20 из этих запросов. И может быть 10 000 таких пользователей. В реальной OLTP-системе наличие таких запросов отчетности даже означает, что Oracle 0.005s не быстр!