В моем продолжающемся исследовании моделирования тем я наткнулся на блог The Programming Historian и пост, показывающий, как извлечь темы из корпуса, используя молоток библиотеки Java.
Инструкции в блоге позволяют легко приступить к работе, но, как и в случае с другими библиотеками, которые я использовал, вы должны указать, из каких тем состоит корпус. Я никогда не уверен, какое значение выбрать, но авторы делают следующее предложение:
Как узнать количество тем для поиска? Есть ли естественное количество тем? Мы обнаружили, что нужно запустить обучающие темы с различным количеством тем, чтобы увидеть, как разбивается файл композиции. Если мы получим большинство наших оригинальных текстов по очень ограниченному количеству тем, то мы воспринимаем это как сигнал о том, что нам нужно увеличить количество тем; настройки были слишком грубыми.
Существуют вычислительные способы поиска этого, включая использование команды MALLETs hlda, но для читателя этого урока, вероятно, будет просто быстрее пройти через ряд итераций (но для получения дополнительной информации см. Griffiths, TL, & Steyvers, M. ( 2004). Поиск научных тем . Труды Национальной академии наук, 101, 5228-5235).
Так как у меня еще не было времени погрузиться в газету или изучить, как использовать соответствующую опцию в молотке, я подумал, что я внесу некоторые изменения в стоп-слова и количество тем и посмотрю, как это получилось.
Насколько я понимаю, идея состоит в том, чтобы попытаться получить равномерное распределение тем -> документов, то есть мы не хотим, чтобы все документы имели одинаковую тему, в противном случае любые вычисления сходства тем, которые мы проводим, не будут такими интересными.
Я попытался запустить молоток с 10, 15, 20 и 30 темами, а также поменял используемые стоп-слова. У меня была одна версия, в которой только что были удалены главные герои и слово «рассказчик», и другая, где я отбирал 20% лучших слов по вхождению и любые слова, которые появлялись менее 10 раз.
Причиной для этого было то, что он должен идентифицировать интересные фразы в эпизодах лучше, чем TF / IDF, а не просто выбирать самые популярные слова во всем корпусе.
Я использовал молоток из командной строки и запускал его на две части.
- Генерация модели
- Отработать распределение тем и документов на основе гиперпараметров
Я написал сценарий, чтобы выручить меня:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
#!/bin/sh train_model() { ./mallet-2.0.7/bin/mallet import-dir \ --input mallet-2.0.7/sample-data/himym \ --output ${2} \ --keep-sequence \ --remove-stopwords \ --extra-stopwords ${1}} extract_topics() { ./mallet-2.0.7/bin/mallet train-topics \ --input ${2} --num-topics ${1} \ --optimize-interval 20 \ --output-state himym-topic-state.gz \ --output-topic-keys output/himym_${1}_${3}_keys.txt \ --output-doc-topics output/himym_${1}_${3}_composition.txt} train_model "stop_words.txt" "output/himym.mallet"train_model "main-words-stop.txt" "output/himym.main.words.stop.mallet" extract_topics 10 "output/himym.mallet" "all.stop.words"extract_topics 15 "output/himym.mallet" "all.stop.words"extract_topics 20 "output/himym.mallet" "all.stop.words"extract_topics 30 "output/himym.mallet" "all.stop.words" extract_topics 10 "output/himym.main.words.stop.mallet" "main.stop.words"extract_topics 15 "output/himym.main.words.stop.mallet" "main.stop.words"extract_topics 20 "output/himym.main.words.stop.mallet" "main.stop.words"extract_topics 30 "output/himym.main.words.stop.mallet" "main.stop.words" |
Как видите, этот скрипт сначала генерирует несколько моделей из текстовых файлов в ‘mallet-2.0.7 / sample-data / himym’ — в каждом эпизоде HIMYM есть один файл. Затем мы используем эту модель для создания тематических моделей разных размеров.
На выходе два файла; одна содержит список тем, а другая описывает процент слов в каждом документе из каждой темы.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
$ cat output/himym_10_all.stop.words_keys.txt 0 0.08929 back brad natalie loretta monkey show call classroom mitch put brunch betty give shelly tyler interview cigarette mc laren1 0.05256 zoey jerry arthur back randy arcadian gael simon blauman blitz call boats becky appartment amy gary made steve boat2 0.06338 back claudia trudy doug int abby call carl stuart voix rachel stacy jenkins cindy vo katie waitress holly front3 0.06792 tony wendy royce back jersey jed waitress bluntly lucy made subtitle film curt mosley put laura baggage officer bell4 0.21609 back give patrice put find show made bilson nick call sam shannon appartment fire robots top basketball wrestlers jinx5 0.07385 blah bob back thanksgiving ericksen maggie judy pj valentine amanda made call mickey marcus give put dishes juice int6 0.04638 druthers karen back jen punchy jeanette lewis show jim give pr dah made cougar call jessica sparkles find glitter7 0.05751 nora mike pete scooter back magazine tiffany cootes garrison kevin halloween henrietta pumpkin slutty made call bottles gruber give8 0.07321 ranjit back sandy mary burger call find mall moby heather give goat truck made put duck found stangel penelope9 0.31692 back give call made find put move found quinn part ten original side ellen chicago italy locket mine show |
|
01
02
03
04
05
06
07
08
09
10
11
|
$ head -n 10 output/himym_10_all.stop.words_composition.txt#doc name topic proportion ...0 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/1.txt 0 0.70961794636687 9 0.1294699168584466 8 0.07950442338871108 2 0.07192178481473664 4 0.008360809510263838 5 2.7862560133367015E-4 3 2.562409242784946E-4 7 2.1697378721335337E-4 1 1.982849604752168E-4 6 1.749937876710496E-41 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/10.txt 2 0.9811551470820473 9 0.016716882136209997 4 6.794128563082893E-4 0 2.807350575301132E-4 5 2.3219634098530471E-4 8 2.3018997315244256E-4 3 2.1354177341696056E-4 7 1.8081798384467614E-4 1 1.6524340216541808E-4 6 1.4583339433951297E-42 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/100.txt 2 0.724061485807234 4 0.13624729774423758 0 0.13546964196228636 9 0.0019436342339785994 5 4.5291919356563914E-4 8 4.490055982996677E-4 3 4.1653183421485213E-4 7 3.5270123154213927E-4 1 3.2232165301666123E-4 6 2.8446074162457316E-43 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/101.txt 2 0.7815231689893246 0 0.14798271520316794 9 0.023582384458063092 8 0.022251052243582908 1 0.022138209217973336 4 0.0011804626661380394 5 4.0343527385745457E-4 3 3.7102343418895774E-4 7 3.1416667687862693E-4 6 2.533818368250992E-4 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/102.txt 6 0.6448245189567259 4 0.18612146979166502 3 0.16624873439661025 9 0.0012233726722317548 0 3.4467218590717303E-4 5 2.850788252495599E-4 8 2.8261550915084904E-4 2 2.446611421432842E-4 7 2.2199909869250053E-4 1 2.028774216237081E-5 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/103.txt 8 0.7531586740033047 5 0.17839539108961253 0 0.06512376460651902 9 0.001282794040111701 4 8.746645156304241E-4 3 2.749100345664577E-4 2 2.5654476523149865E-4 7 2.327819863700214E-4 1 2.1273153572848481E-4 6 1.8774342292520802E-46 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/104.txt 7 0.9489502365148181 8 0.030091466847852504 4 0.017936457663121977 9 0.0013482824985091328 0 3.7986419553884905E-4 5 3.141861834124008E-4 3 2.889445824352445E-4 2 2.6964174000656E-4 1 2.2359178288566958E-4 6 1.9732799141958482E-47 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/105.txt 8 0.7339694064061175 7 0.1237041841318045 9 0.11889696041555338 0 0.02005288536233353 4 0.0014026751618923005 5 4.793786828705149E-4 3 4.408655780020889E-4 2 4.1141370625324785E-4 1 3.411516484151411E-4 6 3.0107890675777946E-48 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/106.txt 5 0.37064909999661005 9 0.3613559917055785 0 0.14857567731040344 6 0.09545466082502917 4 0.022300625744661403 8 3.8725629469313333E-4 3 3.592484711785775E-4 2 3.3524900189121E-4 7 3.041961449432886E-4 1 2.779945050112539E-4 |
Вывод немного сложен для понимания сам по себе, поэтому я немного постобработал с использованием панд, а затем прогнал результаты этого через matplotlib, чтобы увидеть распределение документов по разным темам с разными стоп-словами. Вы можете увидеть сценарий здесь .
Я получил следующую таблицу:
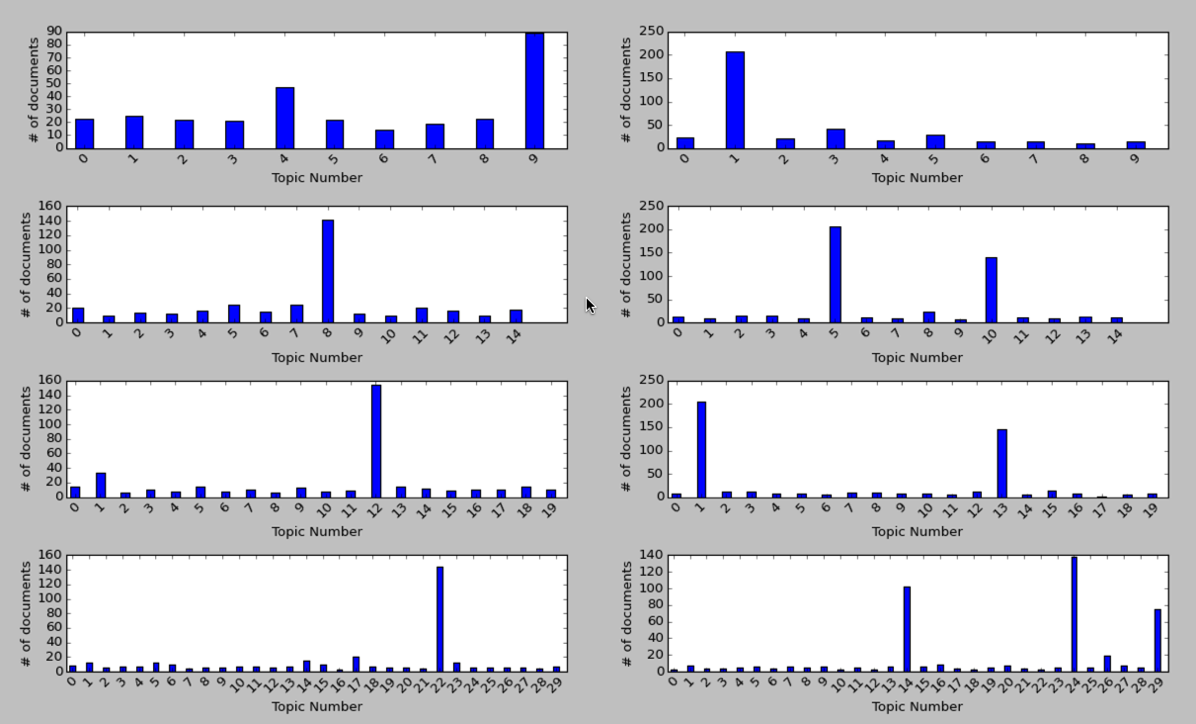
С левой стороны мы используем больше стоп-слов, а справа только основные. Для большинства вариантов есть одна или две темы, к которым относится большинство документов, но, что интересно, наиболее равномерное распределение кажется, когда у нас мало тем.
Вот основные слова для самых популярных тем слева:
15 тем
|
1
|
8 0.50732 back give call made put find found part move show side ten mine top abby front fire full fianc |
20 тем
|
1
|
12 0.61545 back give call made put find show found part move side mine top front ten full cry fire fianc |
30 тем
|
1
|
22 0.713 back call give made put find show part found side move front ten full top mine fire cry bottom |
Все они содержат более или менее одинаковые слова, которые на первый взгляд кажутся довольно общими словами, поэтому я удивлен, что они не были исключены.
С правой стороны мы не удалили много слов, поэтому мы ожидаем, что распространенные слова в английском языке будут доминировать. Давайте посмотрим, если они делают:
10 тем
|
1
|
1 3.79451 don yeah ll hey ve back time guys good gonna love god night wait uh thing guy great make |
15 тем
|
1
2
3
|
5 2.81543 good time love ll great man guy ve night make girl day back wait god life yeah years thing 10 1.52295 don yeah hey gonna uh guys didn back ve ll um kids give wow doesn thing totally god fine |
20 тем
|
1
2
3
|
1 3.06732 good time love wait great man make day back ve god life years thought big give apartment people work 13 1.68795 don yeah hey gonna ll uh guys night didn back ve girl um kids wow guy kind thing baby |
30 тем
|
1
2
3
4
5
|
14 1.42509 don yeah hey gonna uh guys didn back ve um thing ll kids wow time doesn totally kind wasn 24 2.19053 guy love man girl wait god ll back great yeah day call night people guys years home room phone 29 1.84685 good make ve ll stop time made nice put feel love friends big long talk baby thought things happy |
Опять же, у нас есть похожие слова в каждом прогоне, и, как и ожидалось, все они довольно общие слова.
Мой вывод из этого исследования состоит в том, что я должен также изменить процент стоп-слов и посмотреть, приведет ли это к улучшению распределения.
Выделение очень распространенных слов, как мы делаем с левосторонними диаграммами, кажется, имеет смысл, хотя мне нужно выяснить, почему в каждой группе есть один выброс.
Авторы предполагают, что наличие большинства наших текстов в небольшом количестве тем означает, что нам нужно создавать больше их, поэтому я тоже буду исследовать это.
- Код на github и стенограммы, так что попробуйте и дайте мне знать, что вы думаете.
| Ссылка: | Моделирование тем: Определение оптимального количества тем от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |