В последнем посте нашей серии «Моделирование для начинающих Neo4j» мы рассмотрели двунаправленные отношения. В этом посте мы сравниваем последствия определения отношений с использованием разных типов отношений по сравнению с использованием свойств отношений.
Свойства как классификаторы
Допустим, мы хотим смоделировать рейтинги фильмов в Neo4j. У людей есть возможность оценить фильм от 1 до 5 звезд. Один из способов моделирования этого и, возможно, первый, который приходит в голову, — это создание отношения RATED со свойством оценки, которое принимает 5 различных значений: целые числа от 1 до 5.
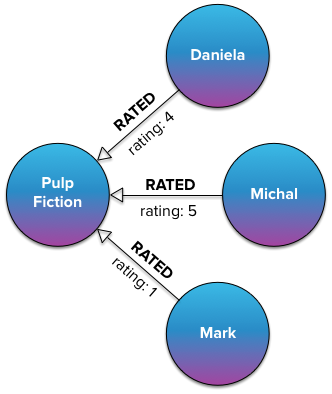
Написание запросов с использованием этой модели довольно просто как в Java, так и в Cypher. Если бы мы хотели получить всех людей с положительной оценкой «Криминальное чтиво», то есть с рейтингом выше 3, мы могли бы просто написать
for (Relationship r : pulpFiction.getRelationships(INCOMING, RATED)) {
if ((int) r.getProperty("rating") > 3) {
Node fan = r.getStartNode(); //do something with it
}
}
или, что то же самое, в Cypher
START pulpFiction=node({id})
MATCH (pulpFiction)<-[r:RATED]-(fan)
WHERE r.rating > 3
RETURN fan
Типы отношений
Поскольку мы заранее знаем все возможные качества отношений, есть еще один вариант: использование отдельного типа отношений для каждого рейтинга. Например, мы могли бы определить следующие типы отношений: ЛЮБИЛ , ПОНРАВИЛОСЬ , НЕЙТРАЛЬНУЮ , не понравилось , и HATED , соответствует 5 звезд до 1 звезда, соответственно. Приведенный выше график будет выглядеть следующим образом.
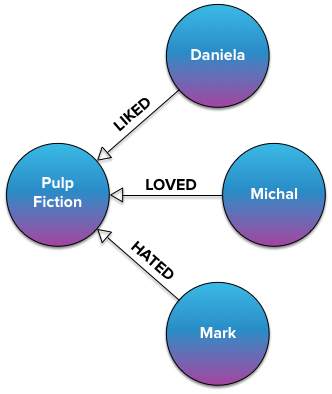
Оба запроса должны быть слегка изменены, чтобы получить одинаковый результат, т. Е. Люди, которые являются поклонниками чтиво. На Java можно написать:
for (Relationship r : pulpFiction.getRelationships(INCOMING, LIKED, LOVED)) {
Node fan = r.getStartNode(); //do something with it
}
и в Cypher:
START pulpFiction=node({id})
MATCH (pulpFiction)<-[r:LIKED|LOVED]-(fan)
RETURN fan
сравнение
С точки зрения синтаксиса запросов, на самом деле не так уж много различий. Если бы мы имели, например, 10 различных качеств отношений и хотели запросить 7 из них, можно было бы утверждать, что первый подход более удобен: он не требует перечисления всех типов отношений, которые мы ищем.
Давайте, однако, рассмотрим два подхода с точки зрения производительности. Первый эксперимент предназначен для выяснения, есть ли какие-либо различия в пропускной способности записи между двумя подходами. Мы создали 1000 отношений между случайными парами узлов и измерили время, необходимое для этого. Мы изменили количество отношений, созданных в одной транзакции, от 1 до 1000. Результаты изображены на следующем рисунке:
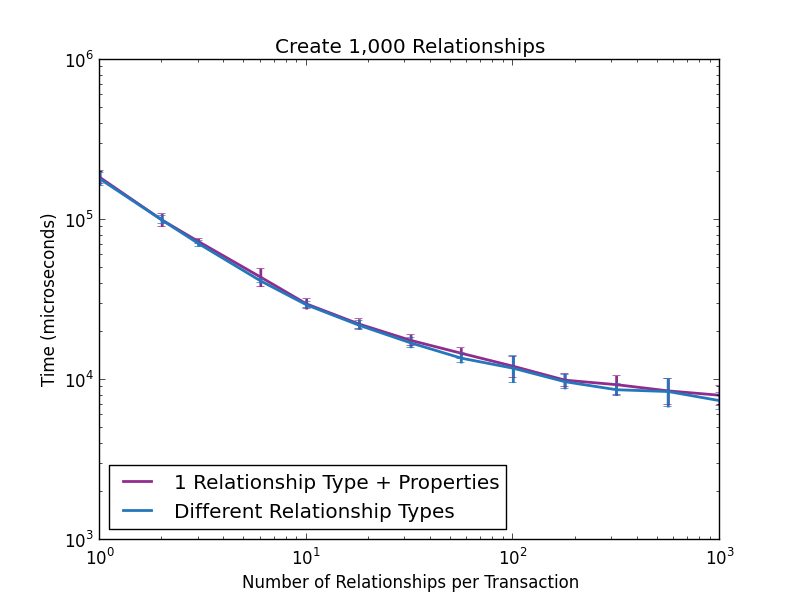
Очевидно, что между двумя подходами нет существенной разницы в пропускной способности записи. Однако это не относится к обходам.
Во втором эксперименте мы выполнили все запросы, показанные ранее 100 раз на графике со 100 узлами и 5000 случайно выбранных, равномерно распределенных отношений (что в среднем дает степень каждого узла 100). Мы провели эксперименты в трех разных условиях.
- Кэши не задействованы, данные читаются с диска
- Данные в низкоуровневом кеше, высокоуровневый кеш отключен
- Данные в кеше высокого уровня
Следующие два рисунка показывают время, необходимое для выполнения этих запросов в Cypher и Java, соответственно.
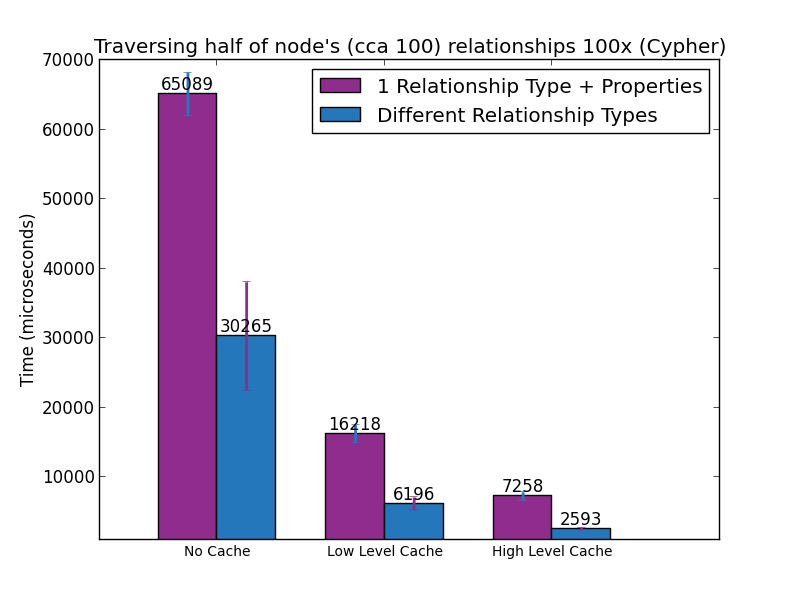
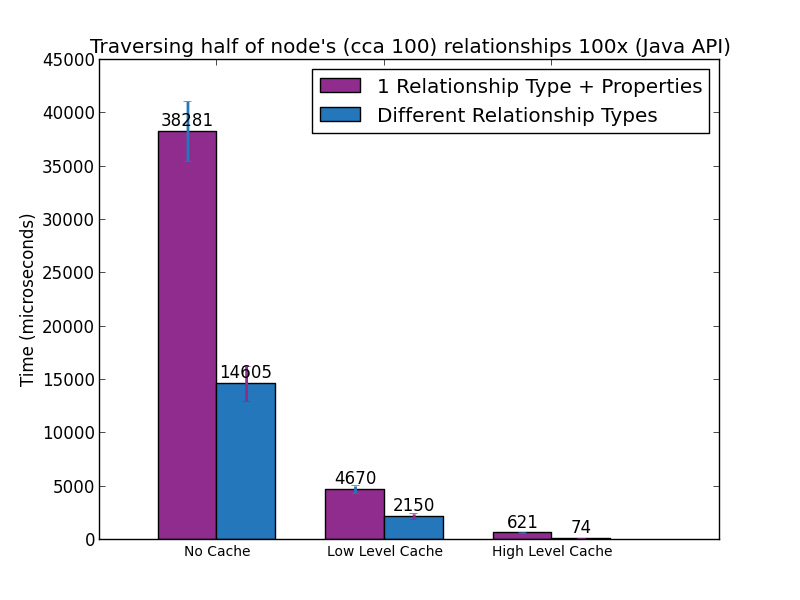
Подход с множественными типами отношений всегда превосходит подход с одним типом и свойством, иногда в 8 раз. Для этого есть техническая причина, связанная с тем, как Neo4j организует свои данные на диске и в памяти. Но это тема для одного из следующих постов.
Важно понимать, что мы измерили только обход одного шага. Если это уже в 8 раз быстрее, глубина прохождения 2 уровня может быть в 64 раза быстрее, а глубина 3 уровня может быть в 512 раз быстрее.
Вывод
Когда это возможно, выбор различных типов отношений для одного типа, квалифицированного по свойствам, может оказать значительное положительное влияние на производительность при запросе графика. Первый подход всегда как минимум в 2 раза быстрее, чем второй. Когда данные находятся в высокоуровневом кеше, а график запрашивается с использованием собственного API Java, первый подход более чем в 8 раз быстрее для обходов с одним прыжком.