Базы данных не являются очередями.
И, несмотря на повсеместное присутствие технологий организации очередей (ActiveMQ, MSMQ, MSSQL Service Broker, Oracle Advanced Queuing), мы часто просим наших реляционных братьев притворяться очередями. Это история одной такой глупости, и по пути мы углубимся в некоторые интересные сюжеты о взаимоблокировках, эскалации блокировок, планах выполнения и покрывающих индексах, о боже! Надеюсь, мы будем смеяться, мы будем плакать, и в итоге получим плохого парня (оказалось, я был плохим парнем).
Это первая часть серии из нескольких частей, описывающей всю сагу. В этой части я расскажу о проблеме, начальном признаке и инструментах и командах, которые я использовал, чтобы выяснить, что происходит не так.
И так начинается …
Я собираюсь подготовить почву для нашего обсуждения, познакомить вас с проблемой и установить персонажей, вовлеченных в нашу трагедию. Допустим, эта система организует музыкальные компакт-диски в маркированные ведра. Компакт-диск может быть только в одном ведре за один раз, и ведро отслеживает на совокупном уровне, сколько компакт-дисков содержится в нем (например, «размер» ведра). Вы можете представить себе стопку компакт-дисков и две корзины: «хорошие CD» и «плохие CD». Время от времени вы решаете, что вам не нравятся ваши предпочтения, и вы хотите перераспределить компакт-диски в новые ведра — возможно, к десятилетию: «музыка 1980-х», «музыка 1990-х», «вся другая (низшая) музыка» , Позже вы можете снова передумать и придумать новый способ организации ваших компакт-дисков и т. Д. Мы будем называть каждый «набор» ведер «поколением». Итак, в нулевом поколении у вас было 2 ведра «хороших CD» и «плохих CD», в первом поколении у вас были «CD 80-х» и т. Д., И так далее, и так далее. Поколение всегда увеличивается с течением времени, когда вы перераспределяете свои компакт-диски из контейнеров предыдущего поколения в контейнеры следующего поколения.
Наконец, хотя моя музыкальная коллекция может быть организована по некоторой схеме ведра, возможно, у моего друга Джерри есть своя собственная коллекция и своя схема ведра. Таким образом, целые наборы ведер по поколениям могут быть сгруппированы в музыкальные коллекции . Коллекции полностью независимы: мы с Джерри не делимся компакт-дисками и не делимся ведрами. Мы можем использовать одну и ту же систему для управления нашими музыкальными коллекциями.
Итак, мы имеем:
- CD — вещи, которые содержатся в ведрах, которые мы распространяем для каждого нового поколения
- Ведра — организационные единицы, сгруппированные по поколениям, которые содержат компакт-диски. На каждой корзине есть заметка с указанием количества компакт-дисков, которые в данный момент находятся в корзине.
- Поколение — набор ведер в определенный момент времени.
- Коллекция — самостоятельный набор компакт-дисков и ведер
Даже несмотря на то, что мы перераспределяем компакт-диски из сегментов одного поколения в другой, компакт-диск находится только в одном сегменте за раз. Визуализируйте физическое перемещение CD с «хороших CD» (поколение 0) на «музыку 1980-х» (поколение 1).
ПРИМЕЧАНИЕ. Наша действительная система не имеет ничего общего с компакт-дисками и ведрами — я просто обнаружил, что проще сопоставить систему с этой простой для визуализации метафорой.
В этой системе у нас есть миллионы компакт-дисков, тысячи блоков и множество процессоров, которые перемещают компакт-диски из лотков одного поколения в другое (параллельно, но не распространяются). Размер каждого ведра должен быть постоянным в любой момент времени.
Итак, предположим, что модель базы данных выглядит примерно так:
- Стол ковшей
- bucketId (например, 1,2,3,4) — КЛАВИША ПЕРВИЧНЫЙ КЛЮЧ
- название (например, музыка 80-х, музыка 90-х)
- поколение (например, 0, 1, 2)
- размер (например, 4323, 122)
- collectionId (например, «Музыкальная коллекция Стива») — НЕКЛАСТЕРНЫЙ ИНДЕКС
- Таблица CD
- cdId (например, 1,2,3,4) — первичный ключ кластеризован
- название (например, «Скромная мышь — Луна и Антарктида», «Интерпол — Антики»)
- bucketId (например, внешний ключ 1,2 и т. д. для таблицы Bucket) — НЕКЛАСТЕРНЫЙ ИНДЕКС
Обратите внимание, что обе таблицы сгруппированы по своим первичным ключам — это означает, что сами фактические данные записи хранятся в конечных узлах первичного индекса. Т.е. сама таблица является индексом. Кроме того, Buckets можно искать по «музыкальной коллекции» без сканирования (см. Вторичный некластеризованный индекс на collectionId), а Cds можно искать по bucketId без сканирования (см. Вторичный некластеризованный индекс на Cds). bucketId).
Алгоритм
Поэтому я написал процесс перераспределения с несколькими целями разработки: (1) он должен был работать в Интернете. Я мог бы одновременно добавлять новые компакт-диски в бункеры текущего поколения при перераспределении. (2) Я всегда мог найти компакт-диск — то есть я никогда не мог ложно сообщить, что какой-то компакт-диск отсутствовал только потому, что мне пришлось искать во время фазы перераспределения. (3) если мы прервем процесс перераспределения, мы сможем возобновить его позже. (4) это должно быть параллельно. Я хотел выполнить (1) и (2) с ограниченным временем блокировки, поэтому, какую бы работу по блокировке я не выполнял, я хотел, чтобы она была как можно более короткой для увеличения параллелизма.
Я использовал простую абстракцию параллелизма, которая содержала пул рабочих, которые разделяли поставщика работы. Поставщик работы будет продолжать давать «куски» предметов для перемещения из одного ведра в другое. Мы распространяем только одну музыкальную коллекцию за раз. Поставщик был доступен всем работникам, но он был синхронизирован для безопасного многопоточного доступа.
Алгоритм для каждого работника выглядит так:
|
1
2
3
4
5
6
7
|
(I) Get next chunk of work(II) For each CD decide the new generation bucket in which it belongs (accumulating the size deltas for old buckets and new buckets)(III) Begin database transaction(IV) Flush accumulated size deltas for buckets(V) Flush foreign key updates for CDs to put them in new buckets(VI) Commit database transaction |
Каждому работнику будет предоставлен кусок компакт-диска для текущей музыкальной коллекции, которая перераспределяется (I). Рабочий сделал бы некоторую работу, чтобы решить, какое ведро в новом поколении должно получить компакт-диск (II). Рабочий будет накапливать дельты для подсчетов: уменьшая исходное значение и увеличивая количество для нового. Затем рабочий сбрасывает (IV) эти дельты в коррелированном обновлении, например, UPDATE Buckets SET size = size + 123 WHERE bucketId = 1 . После того, как обновления размера были сброшены, он сбросил бы (V) все отдельные обновления полей внешнего ключа, чтобы сослаться на сегменты нового поколения, такие как UPDATE Cds SET bucketId = 123 WHERE bucketId = 101 . Эти две операции происходят в одной транзакции базы данных. Поставщик, который дает работу рабочим, представляет собой типичную «очередь», подобную запросу SELECT, — мы хотим перебрать все элементы в музыкальной коллекции старого поколения. Это происходит в отдельном соединении, отдельной транзакции базы данных от рабочих (обсуждается позже). Следующий блок будет прочитан с использованием рабочего потока (с синхронизацией потока). Это отдельное соединение «читатель» не имеет своего собственного потока или чего-либо еще.
Первые признаки неприятностей — полная остановка
Поэтому мы проводили большое объемное тестирование на не очень быстром оборудовании, когда внезапно … система просто остановилась. Казалось, мы были в процессе переноса компакт-дисков в новые ведра, и они просто перестали прогрессировать.
Узнайте, что делает приложение Java
Итак, первым шагом было посмотреть, что делает приложение Java:
|
1
2
3
4
|
c:\>jps1234 BucketRedistributionMain3456 jpsc:\>jstack 1234 > threaddump.out |
Jps находит идентификатор процесса Java, а затем запускает jstack для вывода трассировки стека для каждого из потоков в программе Java. Jps и Jstack включены в JDK.
Полученная трассировка стека показала, что все работники в socketRead ожидали завершения обновления базы данных, чтобы сбросить обновления размера корзины (шаг IV выше).
Вот частичная трассировка стека для одного из рабочих (некоторые неинтересные кадры опущены для краткости):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
"container-lowpool-3" daemon prio=2 tid=0x0000000007b0e000 nid=0x4fb0 runnable [0x000000000950e000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(Unknown Source) ... at net.sourceforge.jtds.jdbc.SharedSocket.readPacket(Unknown) at net.sourceforge.jtds.jdbc.SharedSocket.getNetPacket(Unknown) ... at org.hibernate.jdbc.BatchingBatcher.doExecuteBatch(Unknown) ... at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216) ... at com.mycompany.BucketRedistributor$Worker.updateBucketSizeDeltas() ... at java.util.concurrent.FutureTask$Sync.innerRun(Unknown Source) ... at java.lang.Thread.run(Unknown Source) |
Как вы можете видеть, наш работник обновлял размеры сегментов, что привело к «сбросу» Hibernate (фактически передает запрос к базе данных через провод к ядру базы данных), а затем мы ожидаем ответный пакет от MSSQL, как только инструкция завершена. Обратите внимание, что мы используем драйвер MSSQL jtds (о чем свидетельствует net.sourceforge.jtds в трассировке стека).
Итак, следующий вопрос: почему база данных просто зависает, ничего не делая?
Узнать, что делала база данных …
MSSQL предоставляет множество простых способов получить представление о том, что делает база данных. Сначала давайте посмотрим состояние всех соединений. Откройте SQL Server Management Studio (SSMS), нажмите «Новый запрос» и введите exec sp_who2
Это вернет вывод, который выглядит следующим образом:
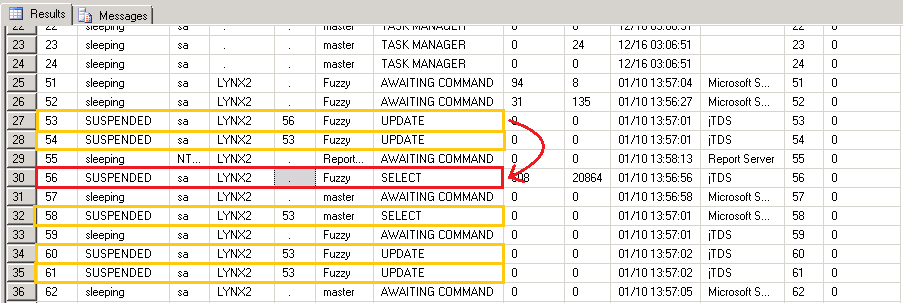
Вы можете увидеть все спиды для сеансов в базе данных. Нас должно интересовать пять: один для запроса «рабочая очередь» и четыре для работников, выполняющих обновления. Вывод sp_who2 включает столбец blkBy, в котором показан spid, блокирующий данный spid в случае, если данный spid является SUSPENDED.
Мы видим, что spid 56 — это запрос SELECT «рабочая очередь» (выделен красным). Обратите внимание, что никто не блокирует его … тогда мы видим спиды 53, 54, 60 и 61 (выделены желтым цветом), которые все ждут 56 (или друг друга). Не обращайте внимания на 58 — источником его приложений является студия управления, как вы можете видеть.
Так как любопытно! запрос читателя блокирует всех работников обновлений и не позволяет им запускать обновления своего размера. Запрос «очереди работы» читателя выглядит так:
|
1
|
SELECT c.cdId, c.bucketId FROM Buckets b INNER JOIN Cds c ON b.bucketId = c.bucketId WHERE b.collection = 'Steves Collection' and b.generation = 23 |
Инвестирование блокирующих и блокирующих проблем…
Я вижу, что spid 56 блокирует всех остальных. Так какие замки держит 56? В новом окне запроса я запустил exec sp_lock 56 и exec sp_lock 53 чтобы увидеть, какие блокировки были у каждого, а кто что ожидал.
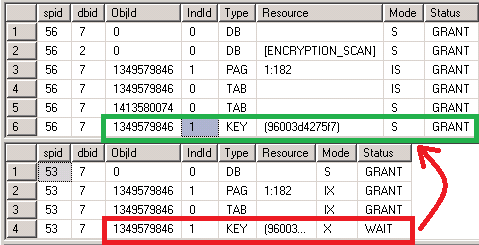
Вы можете видеть, что 56 удерживал S (общую) блокировку для ключевого ресурса (ключ = блокировка строки в индексе) объекта 1349579846, который соответствует таблице Buckets.
Я хотел получить план выполнения движка для запроса «очереди работы» читателя. Чтобы получить это, я выполнил запрос, который я создал некоторое время назад, чтобы получить как можно больше подробностей о текущих сеансах в системе — думать о нем как о «супер who2»:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
select es.session_id, es.host_name, es.status as session_status, sr.blocking_session_id as req_blocked_by,datediff(ss, es.last_request_start_time, getdate()) as last_req_submit_secs,st.transaction_id as current_xaction_id, datediff(ss, dt.transaction_begin_time, getdate()) as xaction_start_secs,case dt.transaction_type when 1 then 'read_write' when 2 then 'read_only' when 3 then 'system' when 4 then 'distributed' else 'unknown'end as trx_type,sr.status as current_req_status, sr.wait_type as current_req_wait, sr.wait_time as current_req_wait_time, sr.last_wait_type as current_req_last_wait, sr.wait_resource as current_req_wait_rsc, es.cpu_time as session_cpu, es.reads as session_reads, es.writes as session_writes, es.logical_reads as session_logical_reads, es.memory_usage as session_mem_usage,es.last_request_start_time, es.last_request_end_time, es.transaction_isolation_level,sc.text as last_cnx_sql, sr.text as current_sql, sr.query_plan as current_planfrom sys.dm_exec_sessions esleft outer join sys.dm_tran_session_transactions st on es.session_id = st.session_idleft outer join sys.dm_tran_active_transactions dt on st.transaction_id = dt.transaction_idleft outer join (select srr.session_id, srr.start_time, srr.status, srr.blocking_session_id, srr.wait_type, srr.wait_time, srr.last_wait_type, srr.wait_resource, stt.text, qp.query_plan from sys.dm_exec_requests srr cross apply sys.dm_exec_sql_text(srr.sql_handle) as stt cross apply sys.dm_exec_query_plan(srr.plan_handle) as qp) as sr on es.session_id = sr.session_idleft outer join (select scc.session_id, sct.text from sys.dm_exec_connections scc cross apply sys.dm_exec_sql_text(scc.most_recent_sql_handle) as sct) as sc on sc.session_id = es.session_idwhere es.session_id >= 50 |
В приведенном выше выводе последний столбец является планом выполнения SQL XML. Просматривая это для spid 56, я подтвердил свое подозрение: план по обслуживанию запроса «рабочая очередь» состоял в том, чтобы найти индекс «музыкальная коллекция» в таблице сегментов для «коллекции Стивеса», а затем искать кластерный индекс для подтверждения «генерации». = 23 ‘, затем ищите индекс bucketId в таблице Cds. Таким образом, для обслуживания предложения WHERE в запросе «рабочая очередь» движок должен был использовать как некластеризованный индекс в Buckets, так и кластеризованный индекс (для предиката версии).
При объединении и чтении строк на уровне изоляции READ COMMITTED механизм будет захватывать блокировки при прохождении от индекса к индексу, чтобы обеспечить согласованное чтение. Таким образом, чтобы прочитать значение генерации в таблице Buckets, он должен получить общую блокировку. И это имеет!
Проблема возникает, когда конкурирующие сеансы пытаются обновить размер той же записи таблицы Bucket. Ему нужна X (эксклюзивная) блокировка в этом ряду (выделено красным) и eek! он не может получить его, потому что этот запрос читателя имеет конфликтующий S-замок
уже предоставлено (выделено зеленым).
Хорошо, так что все имеет смысл, но почему удерживается замок S? В READ COMMITTED вы обычно удерживаете блокировки только во время чтения записи (есть исключения, и мы вернемся к этому во второй части). Они освобождаются, как только значение прочитано. Таким образом, если вы прочитаете 10 строк в одном операторе, двигатель будет: получать блокировку в строке 1, читать строку 1, снимать блокировку в строке 1, получать блокировку в строке 2, читать строку 2, снимать блокировку в строке 2, получать блокировку в строке 3 и т. д. Таким образом, ни один из четырех рабочих в настоящее время не читает — они пишут — или, по крайней мере, они пытаются, если это неприятное соединение с читателем не блокировало их.
Чтобы найти это, мне было любопытно, почему запрос читателя находился в состоянии SUSPENDED (см. Оригинальный вывод sp_who2 выше). В приведенном выше выводе «super who2» значением current_req_wait для запроса чтения «рабочей очереди» является ASYNC_Network_IO .
ASYNC_Network_IO ждать и как базы данных возвращают результаты
ASYNC_Network_IO — интересное ожидание. Давайте обсудим, как удаленные приложения выполняют и используют запросы SELECT из баз данных.
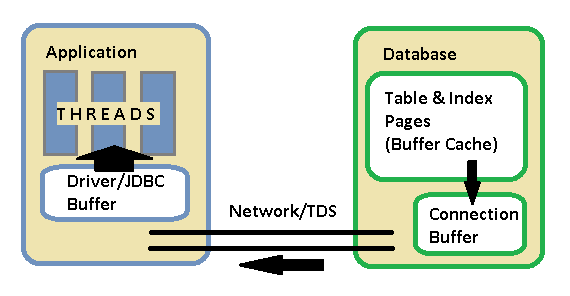
Эта диаграмма слишком упрощена, но в базе данных есть два куска памяти для обсуждения: буферный кеш и сетевой буфер подключения . Буферный кеш — это общая часть памяти, где хранятся фактические страницы таблиц и индексов для обслуживания запросов. Таким образом, части таблиц Buckets и Cds будут находиться в памяти, пока выполняется этот запрос «рабочая очередь». Механизм выполнения выполняет план, он работает из буферного кэша, получает блокировки и создает выходные записи для отправки клиенту. Когда он готовит эти выходные записи, он помещает их в сетевой буфер для конкретного соединения. Когда приложение читает записи из результирующего набора, оно фактически обслуживается из сетевого буфера в базе данных. Драйвер приложения, как правило, также имеет свой собственный буфер.
Когда вы просто выполняете простой запрос SQL SELECT и не объявляете курсор базы данных явно, MSSQL дает вам то, что он называет «набором результатов по умолчанию» — который все еще является своего рода курсором — вы можете думать о нем как о курсоре над куча записей, которые вы можете перебрать только один раз в прямом направлении. По мере того как потоки вашего приложения перебирают результирующий набор, драйвер запрашивает больше кусков строк из базы данных от вашего имени, что, в свою очередь, истощает сетевой буфер.
Однако при очень больших наборах результатов все результаты не могут поместиться в сетевой буфер соединения. Если приложение не считывает их достаточно быстро, в конечном итоге сетевой буфер заполняется, и механизм выполнения должен прекратить создавать новые записи результатов для отправки клиентскому приложению. Когда это происходит, spid должен быть приостановлен, и он приостанавливается с событием ожидания ASYNC_Network_IO . Это немного вводящее в заблуждение имя ожидания, потому что оно заставляет вас думать, что может быть проблема с производительностью сети, но чаще это проблема дизайна приложения или производительности. Обратите внимание, что, когда вращение приостановлено — как и любое другое приостановление — удерживаемые в данный момент замки будут удерживаться, пока вращение не будет возобновлено .
В нашем случае мы знаем, что у нас есть миллионы компакт-дисков, и мы не можем поместить их все в память приложения одновременно. Мы намеренно хотим использовать тот факт, что мы можем передавать результаты из базы данных и работать с ними порциями. К сожалению, если нам случится удерживать конфликтующую блокировку (S-блокировка записи Bucket), когда запрос считывателя приостановлен, то мы создадим, как мы наблюдали, блокировку многоуровневого приложения, и вся система остановится.
Так что же делать для решения? Я расскажу о некоторых вариантах и нашем возможном решении в частях 2 и 3. Обратите внимание, что я дал одну подсказку при нашей первой попытке, когда говорил о «покрытии индексов», а затем есть еще одна подсказка выше, к которой мы не пришли в этом пост о «повышении блокировки».