В этой части мы рассмотрим объединение микросервиса как совокупности услуг и рассмотрим, как мы можем оценить производительность этих услуг. Мы представляем JLBH (Java Latency Benchmark Harness) для тестирования этих сервисов.
Создание Сервисного Обертки.
Для более сложных сервисов мы используем EventLoop в Chronicle Threads для управления несколькими параллельными задачами. В этом примере у нас есть только одна задача, поэтому проще иметь собственный класс для ее поддержки.
Этот класс доступен на ServiceWrapper .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
public class ServiceWrapper<I extends ServiceHandler> implements Runnable, Closeable { private final ChronicleQueue inputQueue, outputQueue; private final MethodReader serviceIn; private final Object serviceOut; private final Thread thread; private final Pauser pauser = new LongPauser(1, 100, 500, 10_000, TimeUnit.MICROSECONDS); (1) private volatile boolean closed = false; public ServiceWrapper(String inputPath, String outputPath, I serviceImpl) { Class outClass = ObjectUtils.getTypeFor(serviceImpl.getClass(), ServiceHandler.class); (2) outputQueue = SingleChronicleQueueBuilder.binary(outputPath).build(); (3) serviceOut = outputQueue.createAppender().methodWriter(outClass); serviceImpl.init(serviceOut); (4) inputQueue = SingleChronicleQueueBuilder.binary(inputPath).build(); serviceIn = inputQueue.createTailer().methodReader(serviceImpl); (5) thread = new Thread(this, new File(inputPath).getName() + " to " + new File(outputPath).getName()); thread.setDaemon(true); thread.start(); (6) } @Override public void run() { AffinityLock lock = AffinityLock.acquireLock(); (7) try { while (!closed) { if (serviceIn.readOne()) { (8) pauser.reset(); (9) } else { pauser.pause(); (9) } } } finally { lock.release(); } } @Override public void close() { closed = true; } @Override public boolean isClosed() { return closed; }} |
|
1
|
This Pauser controls the back off strategy in which no events are coming through. It will retry once, yield 100 times, then start sleeping from half a millisecond to 10 milliseconds. |
Получите тип параметра для ServiceHandler и в этом случае это Service . Создайте очередь вывода. И передать его реализации, чтобы он мог записать в свою очередь вывода. Создать ридер для входной очереди. Начните serviceIn которая будет читать из serviceIn Reader. Привязать этот поток к изолированному процессору, где это возможно. Прочитайте и обработайте одно сообщение. reset() pauser, если пришло сообщение, в противном случае вызовите его для возможной паузы.
Сроки нашего сервиса.
Простое обслуживание может само время. Это может быть использовано как оболочка, однако для более сложной службы вы можете использовать встроенную запись истории и только проверить результат в конце.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
class ServiceImpl implements Service, ServiceHandler<Service> { private final NanoSampler nanoSampler; private final NanoSampler endToEnd; private Service output; public ServiceImpl(NanoSampler nanoSampler) { this(nanoSampler, t -> { }); } public ServiceImpl(NanoSampler nanoSampler, NanoSampler endToEnd) { this.nanoSampler = nanoSampler; this.endToEnd = endToEnd; } @Override public void init(Service output) { this.output = output; } @Override public void simpleCall(SimpleData data) { data.number *= 10; // do something. long time = System.nanoTime(); nanoSampler.sampleNanos(time - data.ts); (1) data.ts = time; // the start time for the next stage. output.simpleCall(data); // pass the data to the next stage. endToEnd.sampleNanos(System.nanoTime() - data.ts0); (2) }} |
|
1
2
|
Take the timing since the last stageTake the timing from the start |
Использование JLBH Java Latency Benchamrk Harness
Этот инструмент основан на JMH (Java Microbenchmark Harness), где основным отличием является поддержка тестирования асинхронных процессов, где вы хотите исследовать временные параметры на разных этапах, возможно, на разных этапах.
|
01
02
03
04
05
06
07
08
09
10
|
JLBHOptions jlbhOptions = new JLBHOptions() .warmUpIterations(50_000) .iterations(MESSAGE_COUNT) .throughput(THROUGHPUT) (1) .runs(6) .recordOSJitter(true) (2) .pauseAfterWarmupMS(500) .accountForCoordinatedOmmission(ACCOUNT_FOR_COORDINATED_OMMISSION) (3) .jlbhTask(new MultiThreadedMainTask());new JLBH(jlbhOptions).start(); |
|
1
2
3
|
Benchmark for a target throughput.Add a thread to record the OS jitter over the interval.Turn on correction for coordinated ommission. |
Для настройки теста мы создаем три сервиса. Это моделирует шлюз, который принимает данные от внешних систем, таких как служба Aweb или FIX Engine. Это принимается одной службой, которая передает сообщение второй службе, и, наконец, оно записывается в службу шлюза, которая может передавать данные во внешнюю систему.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
UUID uuid = UUID.randomUUID();String queueIn = OS.TMP + "/MultiThreadedMain/" + uuid + "/pathIn";String queue2 = OS.TMP + "/MultiThreadedMain/" + uuid + "/stage2";String queue3 = OS.TMP + "/MultiThreadedMain/" + uuid + "/stage3";String queueOut = OS.TMP + "/MultiThreadedMain/" + uuid + "/pathOut";@Overridepublic void init(JLBH jlbh) { serviceIn = SingleChronicleQueueBuilder.binary(queueIn).build().createAppender().methodWriter(Service.class); (1) service2 = new ServiceWrapper<>(queueIn, queue2, new ServiceImpl(jlbh.addProbe("Service 2"))); (2) service3 = new ServiceWrapper<>(queue2, queue3, new ServiceImpl(jlbh.addProbe("Service 3"))); (3) serviceOut = new ServiceWrapper<>(queue3, queueOut, new ServiceImpl(jlbh.addProbe("Service Out"), jlbh)); (4) (5)} |
|
1
2
3
4
5
|
Just a writerReads that message and writes to the third serviceReads from the second service and writes to the outbound service.The output gateway reads from the third service and writes its result to a log/queue.The last service also sets the end to end timing. |
Каждое сообщение сохраняется на каждом этапе и доступно при перезапуске. Поскольку для каждого входного сообщения есть одно выходное сообщение, вы можете перезапустить его, указав тот же индекс, что и выходной. Более надежной стратегией будет запись истории в вывод, как описано в предыдущем посте.
Запуск тестов
При выполнении тестов производительности есть два важных момента
- какой процентиль тебя волнует?
- Типичный,
- 99% плитки (худший 1 из 100)
- 99,9% плитки (худший 1 из 1000)
- Плитка 99,99% (худшее значение 1 из 10000)
- худшее когда-либо
- Какую пропускную способность вы хотите проверить?
Важно, чтобы вы контролировали пропускную способность для теста, чтобы вы могли видеть, как ваша система ведет себя при разных устойчивых выходных данных. Ваша система будет работать максимально быстро в течение коротких периодов, однако буферы и кеши быстро заполняются и не могут поддерживать эту скорость без больших задержек.
Глядя на типичную производительность.
В этом тесте на E5-2650 v2 пропускная способность, которую он может достичь для этого теста, составляет 600 000 сообщений в секунду. Тем не менее, было бы нецелесообразно делать это в течение длительного периода времени, поскольку система быстро достигает точки, в которой она находится с нарастающей задержкой, чем дольше это продолжается. Это связано с тем, что в системе нет места для работы с дрожанием или задержкой. Каждая задержка накапливается по мере того, как система пытается удержаться Так что же является более практичной пропускной способностью для этой фиктивной системы.
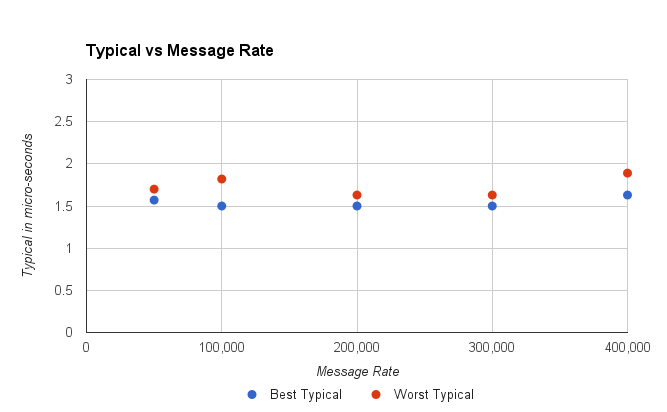
Рисунок 1. Худший Типичный был самый высокий из 15, 2-минутных пробегов.
Это выглядит нормально, при всех пропускных способностях до 400 000 сообщений в секунду типичная производительность стабильна. Однако при пропускной способности 450 000 сообщений в секунду служба может получить задержку, из-за которой ей будет трудно восстановиться, и типичная задержка увеличится до 20–40 секунд.
Короче говоря, с учетом типичной производительности наша оценка пропускной способности, которую мы могли бы предпочесть, упала с 600 К / с до 400 К / с.
Глядя на девятки.
Рассматривая более высокие процентили (худшие результаты), мы можем определить, какие задержки были бы приемлемыми и как часто. Как правило, я бы рассматривал тайл на 99%, что в 4 раза больше типичного, и тайл на 99,9%, который в 10 раз больше типичного времени ожидания. Это эмпирическое правило, которое я использую, однако результаты варьируются в зависимости от системы.
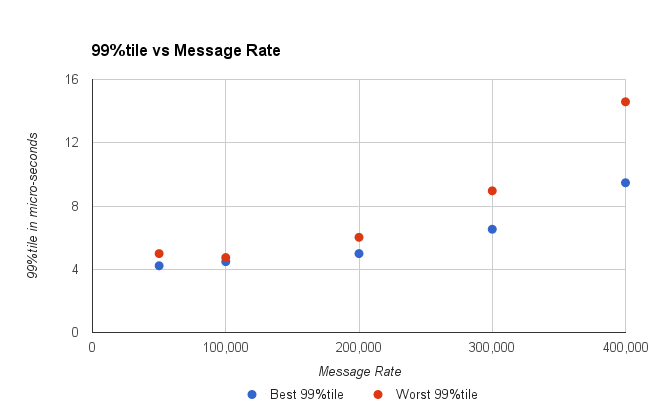
Рисунок 2. Наихудшая цифра 1 в 100 увеличивается с увеличением пропускной способности.
Можно предположить, что размер мозаичного фрагмента 99% должен составлять менее 10 микросекунд, и сделать вывод, что система может обрабатывать 300 тыс. Сообщений в секунду.
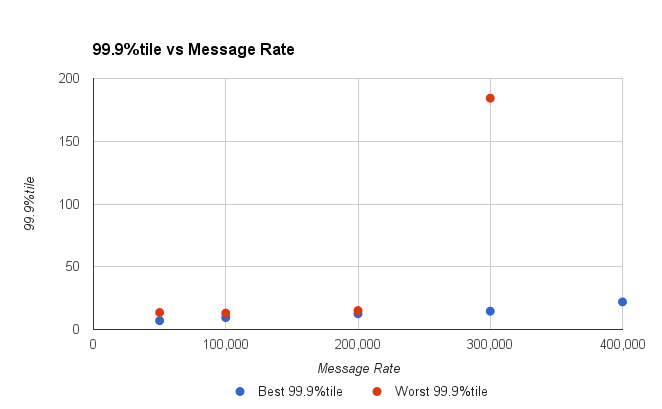
Рисунок 3. Наихудшая цифра 1 в 1000 увеличивается с увеличением пропускной способности.
Взглянув на плитку 99,9%, вы можете увидеть, что при скорости выше 200 Кбит / с наши задержки увеличиваются. До 200 К / с наша система имеет очень стабильные задержки.
Можем ли мы выдержать 200 K мсг / сек?
Возникает проблема, что мы не хотим долго поддерживать этот уровень. С пакетами все в порядке, но делайте это целый день, и вы генерируете много данных. Если все сообщения записаны, и для каждого входящего сообщения они составляют 1/2 КБ, это будет производить 200 МБ / с, и, хотя SSD может сделать это легко, у него будет достаточно свободного места. 200 МБ / с — это 9 ТБ в день. Девять ТБ пригодных для использования высокопроизводительных SSD по-прежнему довольно дорогие.
Допустим, мы хотели записать менее 2 ТБ в день. Несколько жестких дисков большой емкости могут сохранять все ваши сообщения в течение недели. Это 23 МБ / с. При 512 байтах на сообщение (всего) вы смотрите на более скромную выдержку в 50 Кб / с, но со скоростью до 200 Кб / с — 600 Кб / с в зависимости от ваших требований.
В итоге
У нас есть тестовый набор для многопоточных асинхронных процессов, и он может помочь вам изучить, как ваша служба может вести себя при различных нагрузках пропускной способности. Хотя ваша система может поддерживать высокую пропускную способность в течение очень коротких периодов времени, насколько устойчивая пропускная способность влияет на задержку вашей системы.
| Ссылка: | Микросервисы в мире хроники — часть 5 от нашего партнера по JCG Питера Лоури из блога Vanilla Java . |